Data Validation in Pipelines is no longer an optional safeguard — it’s the foundation of every data-driven enterprise. In today’s high-velocity digital ecosystem, clean, reliable, and trustworthy data fuels analytics, AI systems, and product innovation. Imagine a world where a trusted dashboard suddenly shows wildly incorrect metrics because one upstream source slipped invalid or malformed entries into the pipeline. Or a model retrained on subtly corrupted data begins to degrade in production. These risks are not theoretical — they’re happening across industries every day, with costly downstream consequences.
According to Gartner and industry sources, poor data quality costs organizations tens of millions of dollars annually — one recent estimate pegs the damage at $12.9 million per company from rework, bad decisions, and hidden errors. And IDC reports that companies are now achieving an average 3.7× ROI on their data/AI investments — but only when underlying data infrastructure is treated with rigor and trust.
The promise of AI and analytics hinges on one foundational element: trustworthy, clean data passing through your pipelines. That’s where Data Validation in Pipelines becomes mission-critical.
Let’s start with what you’ll gain from this discussion:
TL;DR — What You Will Gain
- A strategic viewpoint on why “data validation in pipelines” is now a board-level concern
- A clear definition and layered framework for pipeline validation
- Deep dive into the key components (governance, technology, metrics, processes)
- Proven best practices and pitfalls you must avoid
- A practical, phased roadmap to implement pipeline validation at scale
- Insights into future trends (AI-driven validation, observability, validation-as-code)
- Techment’s own perspective, approach, and how we partner with enterprises
Learn how Techment empowers data-driven enterprises in Data Management for Enterprises: Roadmap
The Rising Imperative of Data Validation in Pipelines
Why Now, and Why It Matters
Three converging trends make data validation in pipelines not optional — but essential:
- Exponential Complexity & Velocity of Data
Enterprises ingest data from dozens or hundreds of systems — APIs, app logs, IoT devices, third-party vendors, streaming sources, databases, and more. Complexity breeds risk: mismatched schemas, semantic drift, missing fields, and subtle anomalies. - Blurring of Pipelines & Products
Modern systems treat data pipelines as part of product logic — auto-retrained models, operational analytics, real-time dashboards. A failure in validation isn’t just a data error — it becomes a product outage or a faulty decision in the wild. - Regulation, Trust, and Governance Pressures
Compliance regimes (e.g. GDPR, HIPAA, financial reporting rules) demand traceability, lineage, and proof that your data is valid. Business stakeholders expect data you produce to be trusted.
If you skip validation — or trust it only “at the end” — you risk cascading data errors, reduced adoption, and loss of confidence. Great Expectations articulates this well:
Read more about Business Intelligence (BI) and Automation: Using Big Data to create
Inaction has real business impacts:
- Misleading analytics and bad decisions
- Model drift or performance degradation
- Escalating technical debt
- Data consumers bypassing central systems (shadow analytics)
- Financial & reputation costs from regulatory errors
A recent taxonomy study of pipeline quality issues found that incorrect data types and schema incompatibility account for ~33% of data quality incidents, often in the cleaning/transformation stages.
If you’re leading data or engineering at scale, the question is no longer if you need robust pipeline validation — but how fast and how well you can build it.
Learn more about Data Integrity: The Backbone of Business Success
Defining Data Validation in Pipelines: Concept & Framework
To get alignment across architecture, engineering, and product, we must clearly define what “data validation in pipelines” means — and how it fits within broader data quality.
Defining the Concept
Data validation in pipelines refers to the systematic, automated validation checks and controls applied at multiple stages of a data pipeline (ingestion, transformation, load, streaming), to ensure that data entering downstream systems meets structure, semantic, business, and statistical expectations.
It is a subset (and enforcement layer) of broader data quality management, but with a real-time or near-real-time, rule-based posture.
Validation is different from general profiling or auditing: it actively enforces constraints (e.g. “this field must be non-null,” “this value must fall within X–Y,” or “no unexpected schema change”) rather than passively surfacing metrics.
Core Dimensions of Pipeline Validation
You can think of pipeline validation along four interacting dimensions:
- Structural / Schema Validation
Ensuring schema (fields, types, nullability, cardinality) matches contract expectations. - Semantic / Business Rule Validation
Enforcing domain logic: e.g. order_amount ≥ 0, user_age > 0, cross-field consistency. - Statistical & Anomaly Detection
Recognizing patterns and drift: value distributions, time-series deviations, outliers. - Temporal, Referential & Lineage Validation
Ensuring referential integrity (FK checks), consistency over time, lineage correctness.
These dimensions map into layers in a pipeline validation framework, which cross-cuts governance, process, tech, and metrics. (I recommend your design team build a diagram with “ingestion → validation → transform → load” flow and inline hooks for each validation dimension.)
Under that framework, you will nest checks at every stage, not as a single “validation block at the end.”
Dive deeper into AI and Data Integration: Breaking Silos for Smarter Decision-Making
Key Components of a Robust Pipeline Validation Architecture
To operationalize validation, your architecture must support governance, process, tooling, and measurement in an integrated way. Below is a breakdown of core components — with examples, metrics, and automation levers.
- Governance & Rule Management
- Validation Rule Catalog: A centralized repository where structural, semantic, and statistical rules live (with versioning, ownership, and documentation).
- Business-IT Co-Ownership: Domain experts define logical validations (e.g. “customer_age > 18”), IT enforces them; changes go through review.
- Change Management / Approvals: When a schema or source evolves, validation rules must be reviewed and updated. Use release processes or validation flagging.
- Exception Policy & Escalation: Define what to do when validations fail — block, quarantine, log and continue, or default. Policies must clearly define SLAs for remediation.
- Validation Engines & Technology
- Schema Validators: Tools such as JSON Schema, Apache Avro, Protobuf, or custom schema assertions.
- Expectation Engines: Tools like Great Expectations, Deequ, or built-in frameworks in Spark / SQL pipelines.
- Streaming Validators: Lightweight, low-latency rule engines for real-time pipelines (e.g. Flink, Kafka Streams).
- Statistical Analysis Modules: Leverage anomaly detection, drift detection, or machine learning models to flag abnormal partitions.
- Circuit Breakers & Fallbacks: In continuous streams, invalid data should not break the pipeline—introduce circuit breaker patterns to temporarily pause or isolate data flows.
- Lineage and Metadata Systems: To trace where a data row originated, and how it was validated, enriched, or transformed.
Techment has observed that even advanced enterprises require a hybrid strategy—rule-based checks for most validation, supplemented by statistical monitors for subtle drift.

- Process & Workflow Integration
- Validation at Ingestion (Before Landing): Catch schema mismatches, corrupted payloads, empty files, or missing mandatory fields at source.
- Validation Pre-Transformation: Before heavy transformations, ensure the input is well-formed.
- Mid-Pipeline Validation (Semantic Checks): After transformations, verify business logic, cross-field consistency, referential integrity.
- Post-Load Reconciliation: Validate record counts, checksums, and completeness against source systems.
- Batch vs Streaming: For batch jobs, you can afford heavier validation. For streaming, use lightweight checks, sliding-window statistics, and fallback modes.
- Retry & Quarantine Logic: On validation failures, reroute data to an error queue or staging zone for inspection.
- Feedback Loops & Learning: Use exceptions and anomalies to refine rules or catch overlooked edge cases.
- Metrics, Monitoring & Alerting
- Validation Pass Rate (%): Percentage of records passing all validations.
- Failure Patterns & Root Causes: Track which rule(s) fail most often.
- Latency Overhead: Monitor how much extra time validation adds.
- Drift / Distribution Shifts: Monitor rolling z-scores, MMD distances, or KL-divergences.
- SLA Violations: Number of ingestions/transformations delayed due to validation.
- Business Impact Alerts: Map validation failures to downstream impacts (e.g. dashboards, model anomalies).
- Audit Logs & Lineage Traces: For each validation check, log context, input, failure reason, and path.
Every validation architecture must be observability-first. Without monitoring, you’re blind.
Discover more with AI-Powered Automation: The Competitive Edge in Data Quality Management
Best Practices for Reliable Clean Data Flow
Here are 6 strategic best practices that Techment recommends — based on experience across multiple enterprise data journeys:
- “Validate Early, Fail Fast, Surface Quickly”
Catching errors as close to the source as possible minimizes the blast radius. Early schema or integrity rejects save downstream cost.
“Validate as early as possible … Saves computation time and resources” quanthub.com
- Layer Checks with Progressive Complexity
Don’t build the heaviest validation at the ingestion boundary. Start with schema + null checks, then semantic, and add statistical validation in subsequent stages. This staged approach avoids performance penalties.
- Embed Validation in CI/CD Pipeline
Treat validation logic like test code. Run unit, integration, and regression validation tests on all changes to pipeline logic. eyer.ai
- Use fixtures and sample datasets
- Automate negative test cases (incorrect data)
- Fail deployments if key rules break
- Adopt a DataOps / Validation-as-Code Mindset
Validation rules should be versioned, reviewed, tested, and packaged as code. This ties into DataOps principles and ensures reproducibility.
- Define rule modules
- Maintain a rule version history
- Share as code across teams
- Prioritize Exception Handling & Quarantine Workflows
Not all invalid data should be dropped silently. Quarantine, but keep traceability. Build dashboards for error patterns and remediation flows.
- Continuously Refine via Data Feedback Loops
Track the false positives / negatives from your validation logic and iteratively improve. Use anomaly events to create new rules. Over time, you’ll evolve from reactive validation to proactive monitoring.
Also, avoid alert fatigue — group repetitive fail patterns, threshold rules, and rate-limit alerts. Monte Carlo Data
Explore how Techment drives reliability with How Data Visualization Revolutionizes Analytics in the Utility Industry?
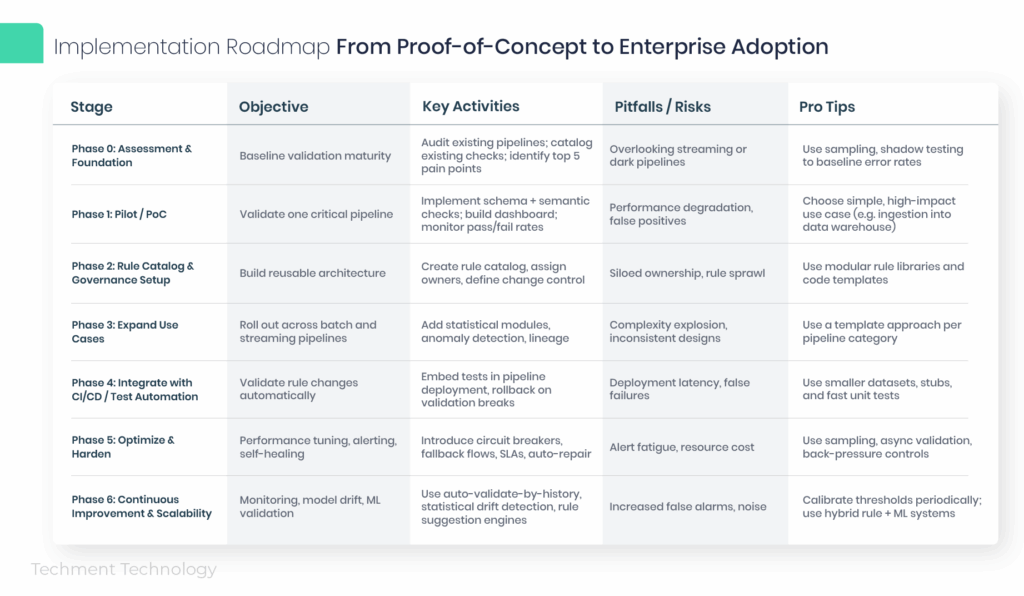
Implementation Roadmap: From Proof-of-Concept to Enterprise Adoption
Below is a phased roadmap to embed Data Validation in Pipelines at enterprise scale:
Common pitfalls to guard against:
- Applying heavy statistical checks in ingestion path causing latency blow-ups
- Lack of ownership so rule drift or schema drift goes unnoticed
- Not quarantining invalid data (leading to silent drops)
- Validation logic creeping into business code (violating separation)
- Alert fatigue from noisy rule failures
Read how Techment streamlined governance in Optimizing Payment Gateway Testing for Smooth Medically Tailored Meals Orders Transactions!
️Common Pitfalls & How to Avoid Them: Ensuring Clean Data Flow
When you’re implementing Data Validation in Pipelines, watch out for these common failure modes — and how to mitigate them:
Pitfall 1: Performance Overhead / Latency
Validation logic too heavy (deep statistical checks, large lookups) blocks ingestion or transformation SLAs.
Mitigation:
- Segment checks by criticality
- Use asynchronous or sampled validation
- Pre-aggregate or pre-index reference data
- Use streaming-friendly architectures (micro-batches, windowing)
Pitfall 2: Schema Evolution Breaks Everything
Upstream schema changes silently break validation logic, causing massive false alarms or crashes.
Mitigation:
- Introduce schema versioning
- Pre-announce changes and require validation rule updates
- Use schema compatibility checks before deployment
- Incorporate soft validation (warn vs block) for new fields initially
Pitfall 3: Alert Fatigue & Noisy Failures
Too many low-value alerts overwhelm engineers; key failures get ignored.
Mitigation:
- Aggregate or throttle alerts
- Prioritize alerts by severity
- Use dashboards rather than individual pings
- Set blackout windows or intelligent suppression
Pitfall 4: Validation Blind Spots
Not all rules can catch semantic shifts; you may miss emerging anomalies.
Mitigation:
- Use statistical and drift-based checks as complement
- Periodically review failure logs and error patterns
- Add new rules dynamically based on observed anomalies
- Use ML-based validation where patterns are subtle
Pitfall 5: Lack of Ownership or Accountability
Without clear ownership, broken rules go stale or unchecked.
Mitigation:
- Assign rule owners and SLAs
- Include validation in architecture review process
- Report validation performance to leadership
Pitfall 6: Quarantine / Remediation Gaps
Invalid data gets dropped or lost without traceability, or gets reintroduced unmanaged.
Mitigation:
- Maintain error queues or tables
- Provide dashboards and tooling for manual inspection and correction
- Track remediation lead times and error recurrence
ROI & Business Value Quantification
- If poor data quality costs ~$12.9M annually (per Integrate.io / Gartner) Integrate.io, then improving validation could recuperate 10-30%
- Reducing downstream rework saves engineering hours, accelerates analytics delivery
- Trustworthy data boosts adoption and decision velocity
- In ML pipelines, Meta’s system GATE improved validation precision 2.1× over baseline for corrupted partitions arXiv
Discover measurable outcomes in Leveraging AI And Digital Technology For Chronic Care Management
Emerging Trends & Future Outlook in Data Validation
Looking ahead, the discipline of pipeline validation is entering a new evolution phase. Here are critical trends to watch:
- Validation-as-Code & Automated Rule Generation
Techniques like Auto-Validate by History (AVH) propose automatic synthesis of validation constraints based on historical pipeline executions. Microsoft / academic research has shown this can reduce manual rule maintenance burden in large-scale recurring pipelines. arXiv
- Integration with Observability & Data Quality Platforms
Validation is converging with observability — think data observability, data lineage, monitoring of schema drift, and data health scores. Expect unified consoles combining validation failures, lineage, SLAs, and root cause drill-downs.
- AI / ML–Driven Anomaly Detection
As static rules hit limitations, AI/ML models (autoencoders, clustering, time-series models) will catch subtle drifts and complex cross-feature anomalies beyond simple ranges.
- Validation in Federated / Data-Mesh Architectures
In a distributed domain-data architecture, each domain or product team may own validation. Rule consistency across domains, contract enforcement, and cross-domain lineage become critical.
- Self-Healing & Auto-Remediation
Groundbreaking systems will not just detect validation failures — they’ll attempt corrective actions (e.g. auto-fill missing values, invoke fallback logic, reprocess data) and alert only unresolved cases.
- Low-Code / No-Code Validation Builders
As data platforms democratize, business users may define simple validation rules via UIs, which then get translated into executable code pipelines.
These trends will elevate validation from a “catch-after” tactic to a strategic system of defense and trust in enterprise data infrastructure.
Discover more in our case study on Autonomous Anomaly Detection and Automation in Multi-Cloud Micro-Services environment
Techment’s Perspective & Methodology
At Techment, we’ve guided 20+ large-enterprise clients through data modernization journeys, always with one core principle: Trustworthy data is non-negotiable.
Our Approach
1. Validation Maturity Assessment
We begin with a 2-week discovery, cataloging existing pipelines, current validation logic, pain points, and stakeholder obligations.
2. Strategic Prioritization
Rather than “boil the ocean,” we identify 1 or 2 high-impact pipelines (e.g. revenue reporting, product analytics) to pilot validation enhancements.
3. Rule Catalog & Governance Framework
We co-design a rule registry with business and engineering ownership, versioning, change management, and remediations.
4. Hybrid Validation Architecture
Our standard pattern is:
- Structural & nullability checks at ingestion
- Semantic checks mid-pipeline
- Statistical drift monitors at load
- Quarantine and remediation system
- CI/CD integration and automated alerts
5. Monitoring & Feedback Loops
We embed observability, dashboards, error dashboards, root-cause analysis, and evolution cycles to build a self-improving validation regime.
6. Scale & Rollout
Once the pilot proves value, we roll across pipelines using a template-based, modular approach, with guardrails and accelerators.
Discover Insights, Manage Risks, and Seize Opportunities with Our Data Discovery Solutions
Why Choose Techment
- Deep domain expertise in data & AI transformation
- Proven success across fintech, healthtech, logistics, enterprise SaaS
- End-to-end capability — from strategy, architecture, implementation, to training
- A track record of creating sustainable, evolving data platforms
Our clients consistently report:
- 40–60% reduction in data incidents
- 25–50% time savings in root-cause investigations
- Faster analytics delivery and higher user trust
Get started with a free consultation and know more about Data Management for Enterprises: Roadmap
FAQ: Addressing Leadership Questions
Q1. What is the ROI of data validation in pipelines?
The ROI comes from avoided rework, increased trust, faster analytics, and reduced downstream errors. Given that data quality lapses cost ~$12.9M per org annually Integrate.io, even a conservative 10% improvement yields multimillion-dollar returns.
Q2. How can enterprises measure success in validation adoption?
Use metrics like validation pass rates, error remediation lead time, reduction in downstream incidents, latency overhead, and user trust feedback.
Q3. What tools and frameworks scale for large pipelines?
Great Expectations, Deequ, Apache Iceberg, Delta Lake, custom rule engines, streaming rule systems (Flink, Kafka Streams), and internal validation-as-code libraries.
Q4. How do you integrate validation into existing data ecosystems?
Adopt a side-by-side pattern: shadow validate before cutting over, wrap validations in modular libraries, and integrate into existing orchestration (Airflow, dbt, etc.).
Q5. What governance challenges will we face?
Key challenges include: ownership ambiguity, schema drift, rule proliferation, stakeholder alignment, alert fatigue, and change management. Address them early via clear roles, process design, and governance layers.
Conclusion & Next Steps
Data validation in pipelines isn’t a “nice-to-have” — it’s the backbone of enterprise trust, reliability, and scalability in modern data and AI systems. For leaders — CTOs, Product Heads, Data Architects — investing in a rigorous, multi-layered validation architecture is not just operational hygiene; it’s a strategic differentiator.
If you act carefully, your data pipelines become not just conveyors of bits, but guardians of business truth.
Next steps to take:
- Run a validation maturity assessment across your critical pipelines.
- Pilot a schema + semantic validation in one high-impact pipeline.
- Build a rule catalog and governance framework.
- Integrate validation tests into CI/CD.
- Expand to streaming and statistical checks.
- Monitor, refine, and evolve.
Let Techment partner with you in that journey — from assessment to enterprise rollout.
Schedule a free Data Discovery Assessment with Techment
Related Reads You May Enjoy
- Modernizing Legacy Infrastructure with Cloud-native Technologies
- Intelligent Test Automation for Faster QA & Reliable Releases
- AI-Powered Automation: The Competitive Edge in Data Quality Management
- Digitized and Automated Platform for mental therapy
- Data Cloud Continuum: Value-Based Care Whitepaper



