What Are RAG Optimization Techniques?
RAG optimization techniques are architectural improvements used to enhance the performance of Retrieval-Augmented Generation systems in enterprise AI applications.
These techniques improve how AI systems retrieve, rank, and process knowledge before generating responses.
The most effective RAG optimization techniques include:
- Multi-query retrieval
- Hybrid search and re-ranking
- Hypothetical Document Embeddings (HyDE)
- Multi-representation indexing
- RAPTOR hierarchical retrieval
- Graph-based RAG
- Agentic RAG orchestration
- Contextual compression retrieval
- Query routing and intent classification
- Continuous evaluation pipelines
By combining these techniques, enterprises can build scalable AI knowledge systems that reduce hallucinations and improve answer accuracy.
Generative AI has rapidly moved from experimentation to enterprise deployment. But as organizations scale AI applications across knowledge management, analytics, and customer engagement, they encounter a critical limitation: large language models alone cannot reliably access enterprise knowledge.
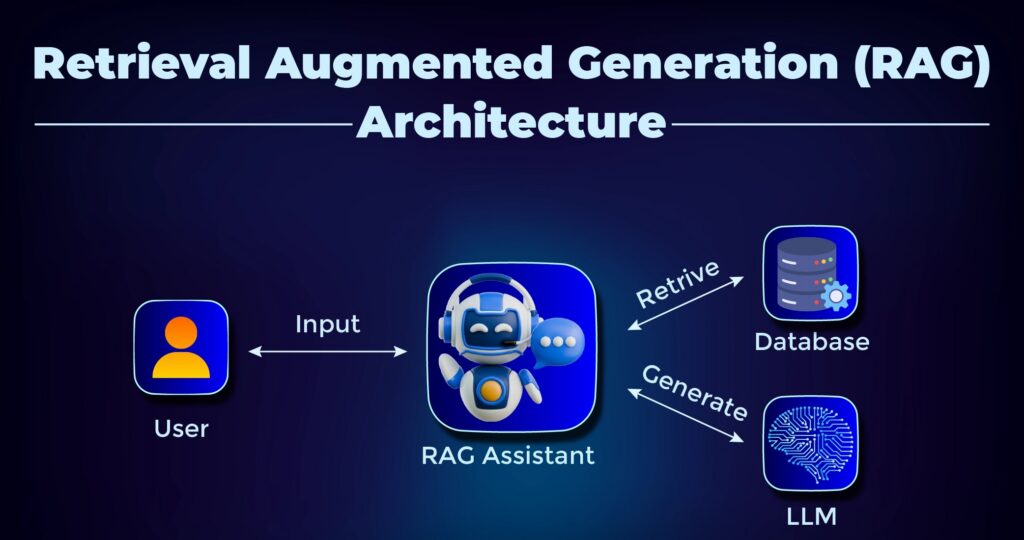
This is where Retrieval-Augmented Generation (RAG) emerges as a foundational architecture.
RAG systems combine large language models (LLMs) with enterprise data retrieval pipelines, enabling AI systems to access internal documents, databases, and knowledge sources dynamically. The result is dramatically improved factual accuracy and contextual understanding.
However, while building a basic RAG prototype is relatively straightforward, optimizing RAG systems for production environments is far more complex.
Enterprise AI systems must address challenges such as:
- Massive and constantly evolving knowledge bases
- Query ambiguity and complex reasoning requirements
- Low-latency response expectations
- Governance and compliance constraints
- Scalable infrastructure costs
Without proper design, RAG pipelines can suffer from poor retrieval quality, hallucinations, slow responses, and fragile architecture.
This is why leading AI teams are adopting advanced RAG optimization techniques to transform experimental pipelines into robust, scalable enterprise AI platforms.
In this guide, we explore 12 powerful RAG optimization techniques used by modern enterprises to improve:
- Retrieval accuracy
- System scalability
- Contextual reasoning
- Cost efficiency
- AI reliability
TL;DR — Executive Summary
- Retrieval-Augmented Generation (RAG) is becoming the backbone of enterprise AI applications.
- However, production-grade RAG systems require advanced optimization strategies to ensure accuracy, scalability, and latency control.
- Leading enterprises now implement multi-query retrieval, re-ranking, hybrid search, multi-vector indexing, Graph RAG, and agentic orchestration.
- These RAG optimization techniques dramatically improve retrieval accuracy, reduce hallucinations, and enhance reasoning capabilities.
- Organizations building enterprise AI platforms must treat RAG architecture as a strategic data platform capability—not just an LLM add-on.
Understanding RAG Architecture in Enterprise AI Systems
Retrieval-Augmented Generation (RAG) is emerging as a foundational architecture for enterprise AI systems that require access to dynamic knowledge sources. Before exploring advanced RAG optimization techniques, it’s important to understand the core architecture that powers retrieval-augmented systems.
At its core, a RAG pipeline consists of three major layers:
- Indexing
- Retrieval
- Generation
Each layer introduces its own performance bottlenecks and architectural considerations.
Organizations building enterprise AI solutions must treat RAG not as a simple pipeline but as a data platform capability integrated into enterprise analytics architecture.
For leaders designing scalable AI platforms, resources like What Is Microsoft Fabric? Comprehensive Overview highlight how unified data platforms are increasingly critical for AI readiness.
Indexing: Building the Knowledge Foundation
Indexing is the process of transforming enterprise data into searchable formats.
This typically includes:
- Document ingestion
- Data preprocessing
- Chunking large documents
- Generating embeddings
- Storing vectors in databases
In enterprise environments, knowledge sources include:
- PDFs
- databases
- internal documentation
- analytics reports
- emails
- images and diagrams
Modern RAG architectures rely on vector databases to store embeddings that enable semantic search.
However, indexing quality directly impacts downstream performance.
Poor chunking strategies can fragment context, while overly large chunks increase token costs and reduce retrieval precision.
Leading enterprises now treat indexing pipelines as data engineering workflows, incorporating:
- automated ingestion pipelines
- schema-aware chunking
- metadata enrichment
- multimodal ingestion
This aligns closely with broader enterprise data architecture strategies discussed in Enetrprise AI and Data Strategy 2026.
Retrieval: The Brain of RAG Systems
Retrieval determines which documents are passed to the LLM during generation.
Most early RAG implementations rely on vector similarity search.
However, this approach has limitations:
- It may miss contextually relevant documents.
- It struggles with ambiguous queries.
- It often ignores document structure.
Enterprise AI systems now incorporate hybrid retrieval models combining:
- dense vector search
- keyword search
- metadata filtering
- contextual ranking
These hybrid architectures significantly improve retrieval quality, especially for complex enterprise queries.
In modern AI platforms, retrieval engines are increasingly integrated with enterprise data governance and discovery platforms, ensuring AI systems only access trusted data.
Architectures such as Microsoft Fabric-based analytics ecosystems illustrate how integrated data platforms support enterprise-grade AI retrieval strategies.
Generation: Context-Aware AI Responses
Once relevant documents are retrieved, the LLM generates responses using the provided context.
The generation layer typically includes:
- prompt templates
- context injection
- answer synthesis
- output formatting
The challenge in production environments is balancing context richness with token limitations.
Too little context results in hallucinations.
Too much context increases latency and cost.
This is why many modern architectures integrate re-ranking models, summarization layers, and reasoning pipelines before generation.
Organizations implementing conversational AI platforms often face similar challenges when building enterprise assistants and knowledge copilots.
Why Basic RAG Pipelines Fail in Production
Despite widespread adoption, many organizations discover that basic RAG implementations fail when deployed at scale.
This is because real-world enterprise environments introduce complexity that simple architectures cannot handle.
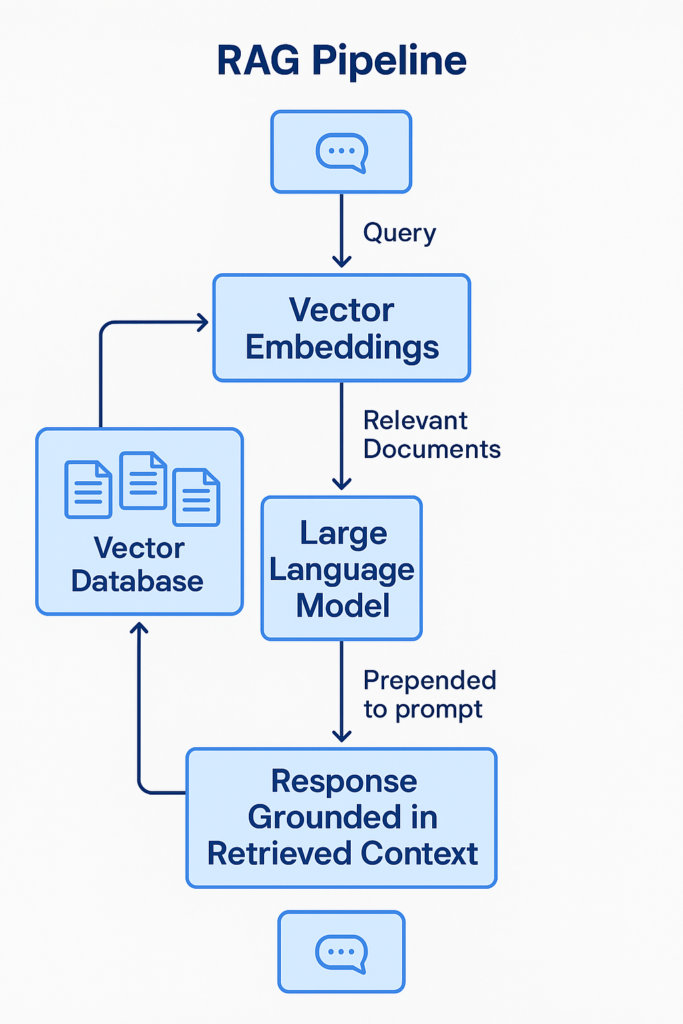
Some of the most common failure points include:
1. Retrieval Inaccuracy
Vector similarity search often retrieves semantically related but contextually irrelevant documents.
This becomes particularly problematic in industries with highly specialized terminology.
2. Context Fragmentation
Traditional chunking methods break documents into small pieces without preserving structure.
As a result, the LLM receives incomplete information.
3. Query Ambiguity
Enterprise queries frequently contain:
- incomplete instructions
- implicit context
- domain-specific terminology
Basic RAG pipelines struggle to interpret these queries correctly.
4. Latency Challenges
As knowledge bases grow, retrieval pipelines become slower.
Without optimization, AI systems cannot meet enterprise response expectations.
5. Scaling Costs
High-frequency retrieval combined with large LLM context windows significantly increases infrastructure costs.
This is why organizations moving from prototypes to production must adopt advanced RAG optimization techniques.
For organizations building AI assistants, copilots, or knowledge management systems, implementing RAG best practices is critical for moving from experimentation to production.
Advanced RAG Optimization Techniques for Enterprise AI
The next generation of AI architectures relies on multiple optimization strategies layered across indexing, retrieval, and reasoning.
These techniques improve:
- contextual understanding
- retrieval accuracy
- reasoning depth
- system scalability
We begin with two foundational techniques used in nearly every modern RAG system.
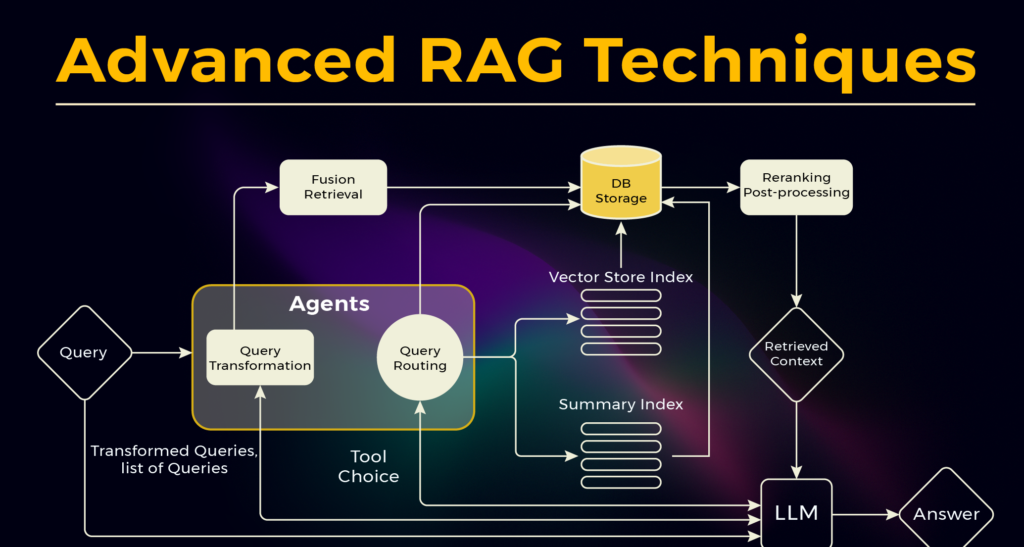
Technique #1 — Multi-Query Retrieval
One of the simplest yet most effective RAG optimization techniques is multi-query retrieval.
Traditional systems generate a single search query from a user prompt.
However, this approach fails when queries are ambiguous or incomplete.
Multi-query retrieval solves this problem by generating multiple reformulated queries from the original input.
Each query explores a different semantic interpretation of the request.
For example:
User Query:
“Applications of transformers in AI”
Generated queries may include:
- transformer models in NLP
- transformer architecture use cases
- transformer deep learning applications
- transformer neural network advantages
Each query retrieves a different set of documents.
The results are then combined to create a richer context for the LLM.
Enterprise Benefits
Multi-query retrieval improves:
- retrieval recall
- context diversity
- answer accuracy
It is particularly effective in:
- research assistants
- enterprise search systems
- knowledge management copilots
From an architectural perspective, this technique introduces a query rewriting layer within the retrieval pipeline.
Technique #2 — Hybrid Retrieval and Re-Ranking
Another essential RAG optimization technique is combining multiple retrieval methods.
Most production systems use hybrid search, which blends:
- vector similarity search
- keyword search (BM25)
- metadata filters
Hybrid retrieval improves precision by leveraging both semantic understanding and exact keyword matching.
After retrieving candidate documents, a re-ranking model evaluates relevance using more computationally expensive models such as cross-encoders.
This two-stage retrieval pipeline dramatically improves answer quality.
Enterprise Advantages
Hybrid retrieval offers several benefits:
- Higher precision search
- Better handling of rare terms
- Reduced hallucinations
- Improved contextual grounding
Many enterprise AI platforms integrate hybrid retrieval directly into their data platforms to ensure scalable knowledge access.
This approach also aligns with enterprise data reliability practices discussed in Driving DataQualityFor AI.
Technique #3 — HyDE (Hypothetical Document Embeddings)
HyDE represents a more advanced method for improving retrieval accuracy.
Instead of embedding the query directly, HyDE generates a hypothetical document that answers the question.
This synthetic document is then embedded and used to retrieve similar real documents.
Why does this work?
Because a generated answer contains richer semantic signals than a short query.
This technique is especially useful when dealing with:
- vague queries
- sparse datasets
- domain-specific knowledge
For example:
User Query:
“Benefits of transformers in NLP”
HyDE generates a paragraph explaining transformer benefits before embedding it.
This richer representation retrieves more relevant documents.
Strategic Implications
For enterprise AI teams, HyDE represents an important shift:
Retrieval pipelines increasingly incorporate LLM reasoning before search, not just after.
This dramatically improves retrieval coverage in complex knowledge domains.
Technique #4 — Multi-Representation Indexing
One of the most powerful RAG optimization techniques used in enterprise AI platforms is multi-representation indexing.
Traditional RAG pipelines typically store a single vector embedding for each document chunk. While this approach works for smaller datasets, it often fails in complex enterprise environments where documents contain:
- structured tables
- diagrams and figures
- long reports
- hierarchical sections
- mixed structured and unstructured data
Multi-representation indexing solves this problem by storing multiple semantic representations of the same document.
These representations may include:
- summarized versions of documents
- paragraph-level chunks
- metadata descriptions
- extracted entity summaries
- multimodal captions for images or tables
Instead of relying on one vector representation, the retrieval system can search across several semantic views of the same information.
Why Multi-Representation Indexing Matters
Enterprise knowledge systems rarely consist of clean, structured documents.
For example:
- financial reports contain tables and commentary
- technical documentation contains diagrams and code
- policy documents contain hierarchical sections
If a RAG pipeline only indexes raw chunks, it may miss critical context embedded in structured components.
Multi-representation indexing improves:
- retrieval precision
- semantic matching
- contextual completeness
Enterprise Impact
Organizations implementing large-scale knowledge copilots benefit significantly from this technique because it enables:
- improved search relevance
- faster retrieval for complex queries
- better context delivery to LLMs
This approach aligns closely with broader enterprise data discovery initiatives, such as those discussed in Data Discovery Solutions.
For enterprises managing thousands of documents across departments, multi-representation indexing becomes a foundational RAG optimization technique.
Technique #5 — RAPTOR Hierarchical Retrieval
As enterprise knowledge bases grow, flat indexing strategies become inefficient.
This is where RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) emerges as one of the most promising RAG optimization techniques.
RAPTOR organizes documents into hierarchical summary trees, enabling multi-level retrieval.
Instead of retrieving isolated document chunks, the system retrieves clusters of semantically related information.
The architecture works in several stages:
- Documents are chunked and embedded.
- Similar documents are clustered together.
- Each cluster is summarized using an LLM.
- Summaries are recursively clustered and summarized again.
The result is a tree structure of knowledge abstraction.
Why Hierarchical Retrieval Works
Enterprise queries often operate at different abstraction levels.
Some users ask:
- detailed operational questions
Others ask:
- strategic questions requiring broader context.
Traditional RAG pipelines struggle to answer both types effectively.
RAPTOR enables retrieval across multiple levels:
- leaf nodes → granular information
- intermediate nodes → contextual summaries
- root nodes → high-level conceptual insights
Enterprise Benefits
Hierarchical retrieval provides several advantages:
- improved contextual reasoning
- better handling of complex questions
- scalable indexing for massive corpora
Organizations deploying enterprise analytics platforms are increasingly adopting hierarchical data structures for knowledge discovery.
These architectural principles align with modern analytics ecosystems described in Microsoft Fabric Architecture: CTO’s Guide to Modern Analytics & AI.
When implemented correctly, RAPTOR can dramatically improve enterprise RAG accuracy.
Technique #6 — ColBERT Token-Level Retrieval
Another breakthrough among modern RAG optimization techniques is ColBERT retrieval.
Traditional embedding models compress entire documents into single vectors.
While efficient, this compression removes important semantic signals.
ColBERT addresses this limitation through token-level embeddings.
Instead of representing a document as one vector, ColBERT stores embeddings for each token within the document.
During retrieval, it performs late interaction scoring between query tokens and document tokens.
This approach allows extremely precise semantic matching.
Why Token-Level Retrieval Matters
Consider the query:
“Impact of transformer attention mechanisms on NLP accuracy”
Traditional vector search may retrieve documents about transformers broadly.
ColBERT, however, matches individual tokens such as:
- transformer
- attention
- NLP
- accuracy
This fine-grained matching dramatically improves retrieval precision.
Enterprise Advantages
ColBERT enables:
- better handling of complex queries
- improved matching for rare terms
- stronger semantic understanding
These capabilities are particularly important in industries with specialized terminology, such as:
- healthcare
- finance
- legal research
- engineering
For enterprise AI platforms, token-level retrieval significantly enhances knowledge system reliability.
Technique #7 — Vision RAG for Multimodal Knowledge
Modern enterprise knowledge repositories increasingly include visual information.
Examples include:
- charts
- architecture diagrams
- scanned documents
- design schematics
- dashboards
Traditional RAG pipelines struggle to interpret visual information because they rely on text-based embeddings.
Vision-enabled RAG systems extend retrieval capabilities to multimodal content.
New architectures combine:
- vision transformers
- multimodal embeddings
- cross-modal retrieval models
These systems enable queries such as:
“Explain the architecture shown in this diagram.”
Why Multimodal Retrieval Matters
In enterprise environments, a significant percentage of critical knowledge exists in visual formats.
For example:
- manufacturing blueprints
- financial dashboards
- engineering diagrams
Without multimodal retrieval, AI systems miss large portions of enterprise knowledge.
Enterprise Benefits
Vision-enabled RAG systems enable:
- diagram interpretation
- chart explanation
- design knowledge retrieval
These capabilities are becoming increasingly important as organizations deploy AI copilots across analytics platforms.
Technique #8 — Graph RAG for Relationship-Aware Retrieval
One of the most transformative RAG optimization techniques emerging today is Graph RAG.
Traditional RAG pipelines treat documents as independent chunks.
However, real-world knowledge contains relationships between entities.
Graph RAG incorporates knowledge graphs into the retrieval process.
Instead of retrieving isolated documents, it retrieves connected subgraphs of knowledge.
How Graph RAG Works
Graph RAG introduces several architectural components:
Graph-based indexing
Documents are converted into graph structures where:
- nodes represent entities or concepts
- edges represent relationships
Graph-guided retrieval
Queries retrieve relevant nodes and expand across connected relationships.
Graph-enhanced generation
The LLM receives both textual context and relational context.
Why Graph-Based Retrieval Matters
Enterprise knowledge often involves multi-hop reasoning.
For example:
“Which product features introduced in version 3 improved customer retention?”
Answering this question requires linking:
product features → release versions → retention metrics.
Traditional RAG systems struggle with such queries.
Graph RAG enables relationship-aware reasoning.
Enterprise Impact
Graph-based retrieval improves:
- reasoning capabilities
- answer explainability
- context coherence
It is particularly valuable for organizations building AI knowledge copilots.
These capabilities align with enterprise data strategy frameworks described in What a Microsoft Data and AI Partner Brings to Your Data Strategy.
Technique #9 — Agentic RAG Systems
One of the most advanced RAG optimization techniques today is Agentic RAG.
Traditional RAG pipelines follow a linear flow:
Query → Retrieval → Generation
Agentic RAG introduces AI agents that dynamically control the pipeline.
Instead of static retrieval logic, agents can:
- decide when retrieval is necessary
- reformulate queries
- call external tools
- perform multi-step reasoning
- verify answers
Why Agentic Architectures Matter
Enterprise queries are rarely simple.
Users may ask questions that require:
- multiple sources
- iterative reasoning
- tool execution
- API integration
Agentic RAG allows AI systems to orchestrate complex workflows.
Enterprise Benefits
Agentic systems enable:
- multi-step problem solving
- tool orchestration
- improved accuracy
- reduced hallucinations
These architectures are rapidly becoming the foundation of enterprise AI assistants and copilots.
Organizations implementing conversational AI platforms often rely on similar agentic frameworks, such as those discussed in Conversational AI on Microsoft Azure: Building Intelligent Enterprise Assistants.
Agentic orchestration represents the next evolution of RAG systems.
Technique #10 — Contextual Compression Retrieval
One of the most practical RAG optimization techniques for enterprise deployments is contextual compression retrieval.
As enterprise knowledge bases grow, retrieval pipelines often return too many documents.
Passing all retrieved documents to the LLM creates several issues:
- higher token costs
- slower responses
- irrelevant context pollution
- reduced answer quality
Contextual compression solves this by filtering and summarizing retrieved documents before generation.
Instead of sending raw document chunks, the system compresses them into highly relevant contextual snippets.
How Contextual Compression Works
The architecture typically includes an additional compression layer between retrieval and generation.
The pipeline becomes:
Query → Retrieval → Compression Layer → Generation
Compression models evaluate each document chunk and extract only the portions relevant to the user query.
This can be implemented using:
- LLM-based summarization
- extractive filtering
- semantic scoring models
For example:
A 1000-token document chunk may be reduced to 200 tokens containing only relevant context.
Enterprise Benefits
Contextual compression delivers several advantages:
- lower token usage
- faster response times
- reduced hallucinations
- improved contextual clarity
For organizations deploying large-scale AI copilots, contextual compression significantly improves RAG system efficiency.
This technique also aligns with enterprise data efficiency principles described in The Anatomy of a Modern Data Quality Framework.
Technique #11 — Query Routing and Intent Classification
Another powerful addition to modern RAG optimization techniques is query routing.
Not every user query requires the same retrieval strategy.
For example:
Some queries require:
- document retrieval
Others require:
- database queries
- API calls
- knowledge graph traversal
- direct LLM reasoning
Query routing systems classify user intent and send queries to the most appropriate retrieval pipeline.
How Query Routing Works
A typical enterprise query routing architecture includes:
- Intent Classification Model
Determines the nature of the query:
- factual lookup
- analytical reasoning
- operational query
- Routing Engine
Based on intent, the query is directed to different pipelines such as:
- vector search
- structured SQL queries
- graph retrieval
- tool execution
- Response Aggregation
Results are combined and passed to the LLM for synthesis.
Enterprise Advantages
Query routing dramatically improves:
- retrieval precision
- response latency
- system scalability
Instead of forcing every query through the same RAG pipeline, the architecture becomes adaptive and intelligent.
This approach is increasingly used in enterprise AI assistants and knowledge copilots.
Technique #12 — Continuous Evaluation and Feedback Loops
Even the most advanced RAG optimization techniques require continuous evaluation.
Enterprise AI systems must evolve as:
- data changes
- user behavior evolves
- models improve
This is why leading organizations implement automated RAG evaluation pipelines.
Key Evaluation Metrics
Production RAG systems are evaluated using several metrics:
Retrieval Precision
Percentage of retrieved documents that are relevant.
Answer Grounding
Degree to which responses are supported by retrieved context.
Hallucination Rate
Frequency of unsupported statements.
Response Latency
Time required to generate answers.
Feedback Loops in Enterprise AI Systems
Advanced platforms incorporate feedback signals such as:
- user ratings
- answer corrections
- human review
These signals feed into continuous optimization pipelines.
For example:
User feedback → retraining retrieval models → improved search ranking.
Strategic Impact
Continuous evaluation ensures enterprise RAG systems remain:
- accurate
- reliable
- trustworthy
Without evaluation pipelines, AI systems degrade over time as data and usage patterns evolve.
For technology leaders, evaluation frameworks are just as important as the RAG architecture itself.
Comparison of RAG Optimization Techniques
| Technique | Category | Key Benefit | Best Enterprise Use Case |
|---|---|---|---|
| Multi-Query Retrieval | Retrieval | Improves recall | enterprise search assistants |
| Hybrid Search + Re-ranking | Retrieval | Higher relevance | knowledge management platforms |
| HyDE | Retrieval | Better semantic matching | complex domain queries |
| Multi-Representation Indexing | Indexing | richer document context | large enterprise document repositories |
| RAPTOR | Indexing | hierarchical knowledge discovery | research assistants |
| ColBERT Retrieval | Retrieval | token-level precision | legal or technical documentation |
| Vision RAG | Multimodal | retrieves visual knowledge | engineering and design systems |
| Graph RAG | Reasoning | multi-hop reasoning | enterprise knowledge graphs |
| Agentic RAG | Orchestration | dynamic workflows | enterprise AI assistants |
| Contextual Compression | Optimization | lower token costs | high-scale AI platforms |
| Query Routing | Architecture | faster responses | enterprise AI copilots |
| Continuous Evaluation | Governance | long-term reliability | enterprise AI operations |
Implementation Blueprint for Enterprise RAG Systems
Adopting advanced RAG optimization techniques requires more than just implementing new algorithms.
Enterprises must design an AI-ready data architecture.
A typical enterprise implementation roadmap includes several phases.
Phase 1 — Data Foundation
Organizations must begin by building a trusted enterprise data layer.
This includes:
- data ingestion pipelines
- governance frameworks
- metadata cataloging
- access control
Without reliable data, AI systems cannot produce trustworthy outputs.
Phase 2 — Retrieval Infrastructure
Next, organizations deploy the retrieval infrastructure:
- vector databases
- hybrid search engines
- knowledge graphs
- indexing pipelines
These systems form the backbone of RAG architecture.
Phase 3 — Reasoning and Orchestration
The next stage introduces:
- prompt engineering frameworks
- agentic orchestration
- query rewriting pipelines
- reasoning chains
These components transform retrieval into intelligent knowledge workflows.
Phase 4 — Evaluation and Optimization
Finally, enterprises must continuously evaluate system performance.
Evaluation metrics typically include:
- retrieval precision
- hallucination rate
- response latency
- user satisfaction
AI systems should evolve continuously as new data and models become available.
Enterprise RAG Performance Comparison
As enterprise knowledge bases grow in size and complexity, the effectiveness of different RAG optimization techniques becomes increasingly important. Various indexing and retrieval strategies deliver significantly different outcomes in terms of precision, recall, and overall answer quality. The comparison below highlights how advanced approaches such as multi-vector indexing and RAPTOR hierarchical retrieval outperform traditional vector search in production environments. These improvements demonstrate why modern enterprises are investing in more sophisticated RAG architectures to improve AI accuracy and reliability.
| Indexing Strategy | Precision | Recall | F1 Score |
|---|---|---|---|
| Basic Vector Search | 70% | 65% | 67.5% |
| Multi-Vector Indexing | 85% | 80% | 82.5% |
| Parent Document Retrieval | 82% | 85% | 83.5% |
| RAPTOR Hierarchical Retrieval | 88% | 87% | 87.5% |
How Techment Helps Enterprises Implement Advanced RAG Systems
Building production-grade RAG systems requires expertise across data architecture, AI engineering, and enterprise governance.
This is where Techment’s data and AI capabilities play a critical role.
Techment helps organizations design and implement scalable AI platforms through:
Enterprise Data Modernization
Techment helps organizations modernize their data ecosystems using platforms like Microsoft Fabric and Azure.
This enables unified access to enterprise data, analytics, and AI workloads.
AI-Ready Data Platforms
Techment ensures enterprise data is clean, governed, and AI-ready.
This includes:
- data quality frameworks
- metadata management
- data lineage tracking
- governance implementation
Advanced AI Architectures
Techment architects advanced AI solutions including:
- enterprise RAG systems
- AI copilots
- knowledge assistants
- agentic AI workflows
End-to-End Implementation
Techment supports the entire AI lifecycle:
- strategy and roadmap
- architecture design
- implementation and deployment
- optimization and scaling
Organizations looking to unlock enterprise AI value can explore Techment insights such as AI-Ready Enterprise Checklist: Microsoft Fabric.
By combining data strategy, AI engineering, and enterprise governance, Techment helps organizations build AI platforms that scale.
Conclusion
Retrieval-Augmented Generation is rapidly becoming the core architecture powering enterprise AI systems.
However, basic RAG pipelines are not sufficient for production environments.
Organizations must adopt advanced RAG optimization techniques to ensure their AI platforms are:
- accurate
- scalable
- reliable
- cost-efficient
Techniques such as below are transforming how enterprises build AI-powered knowledge systems.
- multi-query retrieval
- hybrid search and re-ranking
- multi-representation indexing
- RAPTOR hierarchical retrieval
- Graph RAG
- Agentic RAG
For technology leaders, the key insight is clear:
RAG architecture is not simply an AI feature—it is a strategic enterprise capability that connects data, analytics, and generative AI.
Organizations that invest early in scalable RAG architecture will unlock powerful AI use cases across knowledge management, analytics, and intelligent automation.
With the right architecture, governance, and engineering expertise, enterprises can move beyond experimental AI and build reliable, production-grade intelligent systems.
FAQs — Enterprise RAG Systems
1. What are RAG optimization techniques?
RAG optimization techniques improve the performance of retrieval-augmented generation systems. These techniques enhance retrieval accuracy, scalability, and reasoning capabilities in enterprise AI applications.
2. Why are RAG systems important for enterprise AI?
RAG systems allow AI models to access enterprise knowledge dynamically. This significantly improves accuracy while reducing hallucinations in generative AI systems.
3. What is Graph RAG?
Graph RAG integrates knowledge graphs into retrieval pipelines, enabling AI systems to understand relationships between entities and perform multi-step reasoning.
4. What is Agentic RAG?
Agentic RAG introduces autonomous AI agents that dynamically orchestrate retrieval, reasoning, and tool execution to solve complex tasks.
5, What are the biggest challenges in deploying RAG systems?
Common challenges include:
poor data quality
incomplete indexing strategies
slow retrieval pipelines
lack of governance frameworks
Addressing these challenges requires strong data architecture and AI engineering capabilities
Techment provides end-to-end RAG in 2026 consulting, implementation, and optimization for data-heavy organizations.