Why Evaluating Gen AI Hallucinations, Bias and Toxicity Matters
Generative AI (GenAI) has moved beyond experimental labs into mission-critical enterprise applications, customer interactions, healthcare decision-making, and even financial services. While traditional AI testing prioritized accuracy, F1-scores, and BLEU metrics, these are no longer sufficient for Large Language Models (LLMs). Accuracy measures functional correctness but often ignores risks like manipulation, stereotype amplification, or harmful advice.
The challenge today lies in evaluating bias, toxicity, and hallucinations in generative AI. High accuracy can actually be dangerous, as it creates “over-trust,” making users more vulnerable to biased or fabricated outputs. This guide provides a layered strategy to move beyond functional testing toward a model of real-world safety, fairness, and ethical accountability.
In this blog, we provide a holistic guide that goes beyond accuracy, addressing how leaders, QA teams, and AI practitioners can evaluate, detect, and mitigate bias, toxicity, and hallucinations in generative AI systems.
Learn how Techment helps enterprises implement AI-powered quality assurance at scale to mitigate Hallucinations in Generative AI.
TL; DR: Summary Box
- Bias isn’t accuracy: A model can score high on benchmarks yet amplify stereotypes or discriminate in outputs.
- Toxicity needs detection pipelines: Automated toxicity detection, human-in-the-loop systems, and red-teaming reduce harmful responses.
- Hallucinations in Gen AI are costly: LLMs often “make up facts,” demanding mitigation strategies like retrieval-augmented generation (RAG).
- Responsible evaluation requires layers: Technical, ethical, and business-level reviews must work together.
- AI safety frameworks are maturing: Global organizations like Gartner and Forrester stress explainability, fairness, and accountability for mitigating Hallucinations in Generative AI.
- Actionable practices: Bias testing suites, toxicity filters, fact-checking mechanisms, and domain-specific guardrails are now table stakes.
Discover how low-code test automation can boost QA productivity, cut scripting effort, and speed up releases using Tricentis-powered solutions in our blog on Low-Code Test Automation: Accelerate QA Speed and Quality.
Why Accuracy Metrics Fail for Generative AI
Traditional metrics—accuracy, F1-score, BLEU—capture functional correctness but ignore risks like manipulation, stereotype amplification, or harmful advice.
Expert insight extends this further: Models with excellent benchmark scores can still:
- Generate persuasive but misleading content
- Reinforce harmful narratives
- Mask deeper structural unfairness
The “Safety Tax” of Gen AI
Ensuring safety, truthfulness, and fairness is not optional; it’s a fundamental requirement.
High accuracy can create over-trust, making users more vulnerable to biased or fabricated outputs.
Explore how our automation solutions integrate seamlessly within your DevOps and QA pipelines.
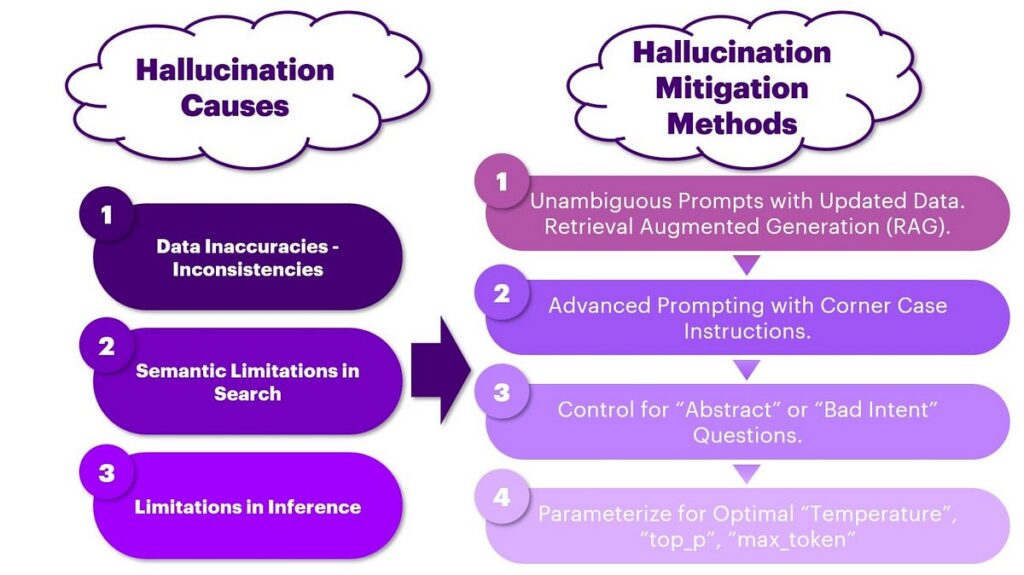
What Causes Hallucinations in Generative AI and Large Language Models
Regulatory & Ethical Pressures
Regulators worldwide (EU AI Act, U.S. AI Bill of Rights, OECD AI Principles) mandate:
- Transparency
- Explainability
- Fairness
- Accountability
Enterprises ignoring these dimensions risk compliance failures, legal challenges, and reputational damage.
Learn how Techment’s QA services are aligned with global test maturity practices.
What Is Generative AI Bias?
Generative AI bias occurs when AI systems reflect, amplify, or even introduce unfairness due to skewed training data, flawed algorithms, or unintended correlations. Such biases can undermine trust, limit adoption, and create ethical and compliance risks in enterprise applications.
Common Sources of Bias
- Training Data Bias
- Historical imbalances (e.g., male-dominated tech forums or Western-centric text corpora) influence the AI’s output.
- Data gaps may exclude underrepresented groups, reinforcing stereotypes or producing irrelevant results.
- Algorithmic Bias
- Reinforcement learning processes and optimization techniques may unintentionally favor one type of response over another.
- Over-optimization for accuracy can ignore fairness constraints, embedding systematic preference.
- User Interaction Bias
- Models fine-tuned on user data inherit the behaviors, language patterns, and cultural skew of those interactions.
- Popularity-based reinforcement (upvotes, likes) amplifies mainstream views while muting minority perspectives.
How to Detect Bias in Generative AI Outputs
Bias arises from the data → model pipeline and is often inherited from social and historical inequalities.
Bias as an Inherited Defect
Models reflect skewed training data—overrepresented groups dominate, underrepresented groups suffer.
This leads to:
- Gender-skewed hiring recommendations
- Unequal lending decisions
- Healthcare misdiagnosis
Measuring Bias with True Fairness Metrics
Beyond traditional benchmarking, enterprises must evaluate fairness using:
- Demographic Parity
- Equal Opportunity
- Disparate Impact Analysis
- Counterfactual Testing
These reveal harms that accuracy metrics overlook.
Why Counterfactuals Matter
Modifying only a protected attribute (e.g., gender → male/female) exposes subtle but harmful response variations.
Key Insight:
Bias is not a technical bug—it is a societal risk. Evaluating and mitigating bias ensures equitable, inclusive, and trustworthy AI.
Find our Step-by-Step Guide: What to Look for in a Test Maturity Assessment Partner blog to learn more on test automation.
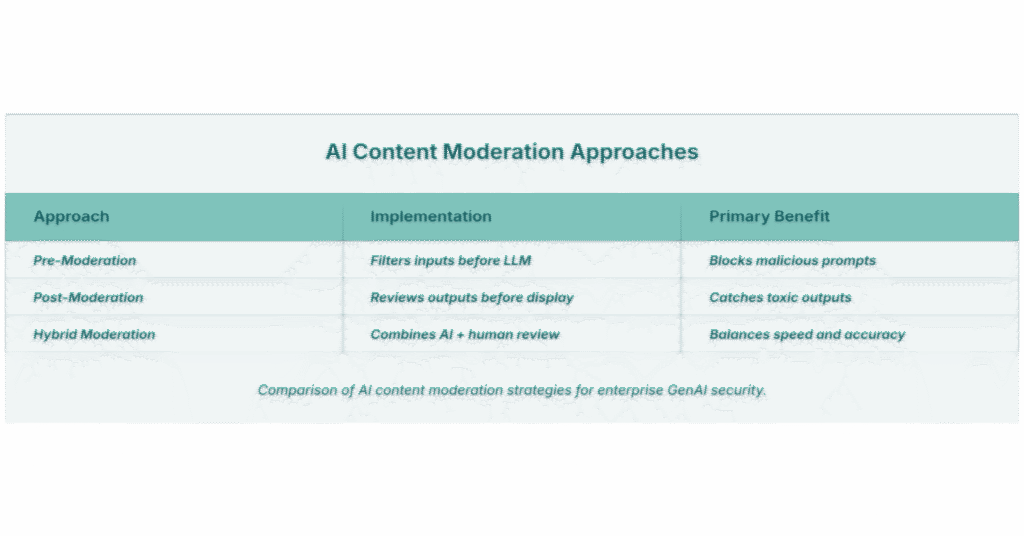
Toxicity Detection in AI Outputs
What Is Toxicity?
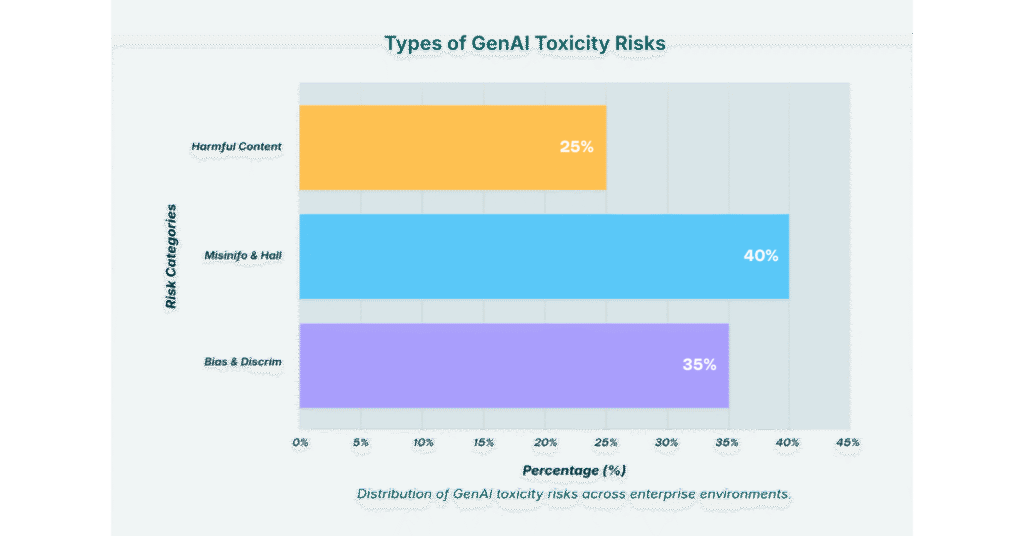
- Definition: Toxicity in AI refers to harmful, offensive, or unsafe outputs generated by models, including hate speech, harassment, and misinformation.
- Risks: Toxic outputs damage user trust, brand reputation, and can even lead to legal or compliance issues in regulated industries.
- Challenge: Unlike simple factual errors, toxicity often requires context-aware detection, as the same phrase may be benign in one scenario but offensive in another.
Practical Approaches to Detect & Reduce Toxicity
- Automated Detection Tools
- Leverage APIs such as Perspective API, or open-source classifiers like Toxic Comment Classification.
- Enable real-time monitoring for high-volume applications.
- Human-in-the-Loop Validation
- Employ content reviewers for edge cases where nuance or cultural context matters.
- Helps avoid false positives that can arise from over-reliance on automation.
- Red-Teaming AI Systems
- Systematically stress-test models with adversarial prompts to uncover hidden vulnerabilities.
- Ensures robustness against malicious attempts to trigger toxic behavior.
Actionable Practices
- Zero-Tolerance Filters
- Enforce strict policies for hate speech, harassment, and violent content.
- Context-Aware Moderation Pipelines
- Layer rule-based systems with ML classifiers for more granular decision-making.
- Continuous Toxicity Scoring
- Implement ongoing evaluations of production outputs.
- Track performance with toxicity benchmarks to ensure ethical AI deployment.
According to Reuters, AI-powered moderation reduced hate speech visibility by 50% on leading social platforms.
Related Read: Agentic AI vs Generative AI (2026): What Enterprise Leaders Must Know
What Are Hallucinations in Gen AI?
Hallucinations occur when generative AI outputs plausible-sounding but factually incorrect or fabricated responses.
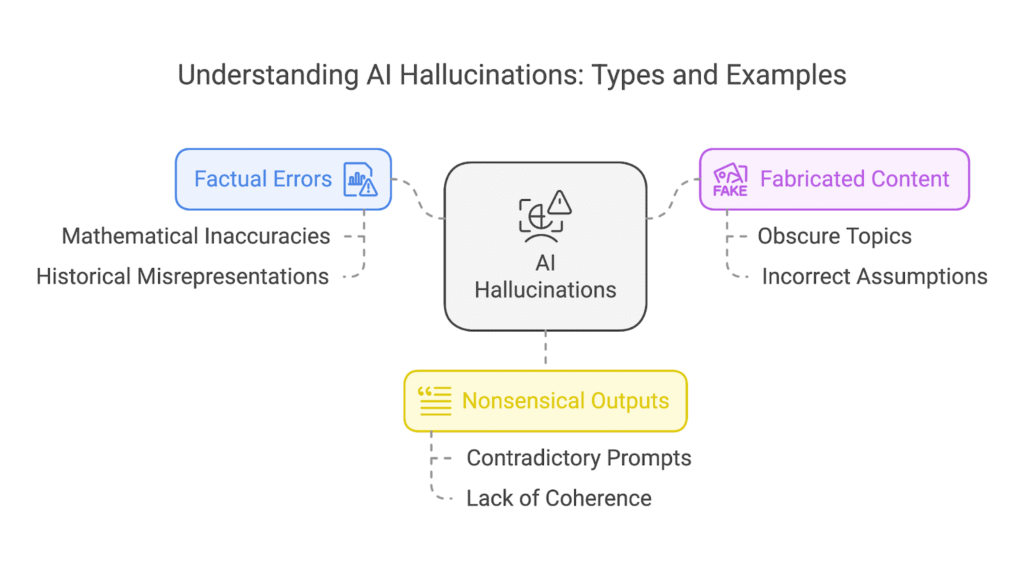
Types of Hallucinations in Generative AI
- Intrinsic Hallucinations: Errors due to flawed reasoning within the model.
- Extrinsic Hallucinations: Confident statements about nonexistent facts, citations, or events.
- Domain-Specific Hallucinations: High-risk in sectors like medicine, finance, and law.
AI Hallucination Mitigation Strategies
- Retrieval-Augmented Generation (RAG): Grounding responses with external knowledge bases.
- Fact-Checking Layers: Cross-verification against trusted APIs or databases.
- Confidence Scoring: Signaling uncertainty in outputs.
Explore real-world governance scaling in production environments: AI in Data Quality Management: Driving Accuracy, Automation, and Enterprise Trust
| Hallucinations | Bias | Toxicity |
|---|---|---|
| When large language models invent or present incorrect information as facts, it is referred to as hallucination. Such outputs can mislead users, rewrite historical context inaccurately, and create serious risks in sensitive domains like healthcare, finance, or law. | Biased responses from LLMs can reinforce misinformation and perpetuate harmful stereotypes, disproportionately affecting underrepresented or marginalized communities. This includes scenarios like discriminatory AI-driven hiring, slanted news narratives, or prejudiced automated responses—outcomes that must be actively prevented. | LLMs may produce offensive or harmful material, including hate speech, abusive language, or false claims. Without strong safeguards, these models can amplify negativity and misinformation, overwhelming credible and truthful content. |
| Common hallucination patterns:• Fabricated facts• Illogical or meaningless responses• Mixing or misattributing sources | Common bias categories:• Gender-based bias• Racial bias• Cultural or regional bias | Key toxicity triggers:• Malicious or leading prompts• Biased or low-quality training data• Data contamination |
Measuring Toxicity in AI-Generated Content
Toxicity exists on a spectrum—from explicit hate speech to subtle stereotyping and persuasive framing.
The Spectrum of Toxicity
The most harmful toxic outputs are often not overt but subtly harmful, shaping opinions or reinforcing bias quietly.
How Enterprises Should Detect & Reduce Toxicity and Hallucinations in Generative AI
Automated Detection Tools – Use APIs or classifiers (Perspective API, Detoxify) for real-time scanning.
Human-in-the-Loop Validation – Critical for:
- Cultural nuance
- Contextual meaning
- Avoiding false positives
The Role of RLHF
Reinforcement Learning from Human Feedback improves alignment, but its effectiveness depends on the diversity, representativeness, and quality of human reviewers.
Red-Teaming: Beyond Benchmarking
Adversarial stress-testing reveals failure modes not visible in standard accuracy tests.
Actionable Practices
- Zero-tolerance toxicity filters
- Multi-layer moderation pipelines
- Continuous toxicity scoring in production
Stat: AI moderation reduced hate speech visibility by 50% on major platforms (Reuters).
Learn how Techment can help define your AI vision, prioritize high-value use-cases, and build a practical, ROI-driven roadmap with its AI services.
Responsible GenAI Evaluation Framework For Removing Hallucinations in Generative AI
A robust evaluation strategy must be layered across technical, ethical, and business dimensions.
Technical Layer
- Quantitative metrics for bias, toxicity, hallucination
- Benchmark datasets for content safety
- Long-tail edge case testing
Ethical Layer
- Fairness across demographics
- Representation in different cultures and contexts
- Transparency using Explainable AI (XAI)
- XAI: The Audit Trail for Safety
XAI reveals why the model behaves as it does, enabling targeted mitigation and compliance reporting.
Business Layer
- Assessing reputational risk
- Ensuring regulatory compliance
- Balancing innovation with safe deployment
The “Harm Tax”
Bias, toxicity, or hallucinations can directly impact:
- Customer trust
- Brand equity
- Financial and legal consequences
Learn how we help organizations evaluate, optimize, and operationalize AI responsibly through our Gen AI evaluation framework.
Learn why AI-enabled test case generation is transforming enterprise application QA through our latest blog.
Conclusion
Bias, toxicity, and hallucinations represent the next frontier of AI quality assurance. Enterprises cannot afford to rely solely on accuracy when deploying generative AI at scale. A holistic framework combining technical, ethical, and business evaluation ensures that systems are both trustworthy and responsible.
Contact us to implement test automation at scale.
FAQs on Hallucinations in Generative AI
1. How do you measure bias in generative AI?
Bias can be measured through fairness datasets, counterfactual testing, and disparate impact analysis across demographic groups. Tools like Bias Benchmark for QA are commonly used.
2. What’s the difference between accuracy and fairness in AI?
Accuracy measures performance on tasks, while fairness ensures equitable treatment across demographics. A model can be accurate but still biased.
3. How can enterprises mitigate hallucinations in Gen AI?
Strategies include retrieval-augmented generation (RAG), integrating fact-checking APIs, and confidence scoring mechanisms to highlight uncertainty.
4. What tools exist for toxicity detection in AI outputs?
Tools include Google’s Perspective API, Detoxify (open-source), and in-house classifiers for contextual toxicity detection.
5. Why is responsible evaluation critical for generative AI?
Responsible evaluation ensures compliance, reduces reputational risks, and aligns with ethical standards while protecting users from harm.
6. Are there industry standards for AI safety?
Yes, frameworks are evolving under organizations like OECD and NIST, focusing on fairness, explainability, and robustness.