Introduction
Enterprises today are not struggling with a lack of data—they are overwhelmed by it. From transactional systems and IoT streams to customer interactions and AI-driven insights, the volume, velocity, and variety of data have reached unprecedented levels. Traditional monolithic systems are no longer sufficient to support this complexity.
This is where scalable data architecture becomes a strategic imperative. Modern enterprises require architectures that not only handle massive data loads but also adapt dynamically to evolving business demands, analytics use cases, and regulatory requirements.
As highlighted in research such as the IJFMR paper on enterprise data platforms , scalability is no longer just a technical concern—it directly impacts decision-making speed, innovation capacity, and competitive advantage.
This blog explores how to design scalable data architecture for enterprise data platforms, covering architectural patterns, governance strategies, performance optimization, and implementation best practices. More importantly, it frames these elements through a strategic enterprise lens—helping CTOs and data leaders make informed, future-ready decisions.
TL;DR Summary
- Scalable data architecture is foundational to enterprise data platforms handling modern data complexity
- Hybrid architectures combining data lakes and warehouses dominate enterprise strategies
- Modularity, elasticity, governance, and interoperability are key design principles
- Cloud-native platforms are essential for performance and scalability
- Poor governance leads to “data swamps” and operational inefficiencies
- Enterprises must align architecture with AI readiness and real-time analytics demands
Why Scalable Data Architecture Is a Strategic Imperative
Modern enterprises operate in a landscape where data is both an asset and a liability. Without the right architecture, data becomes fragmented, inaccessible, and unreliable.
The Explosion of Enterprise Data
Industry research from organizations like Gartner and IDC consistently highlights exponential data growth. Enterprises are now dealing with:
- Petabyte-scale datasets
- Real-time streaming data from IoT and applications
- Multi-cloud and hybrid environments
- AI and machine learning workloads
This creates pressure on data platforms to scale not just storage, but also compute, governance, and accessibility.
The Cost of Poor Scalability
When scalable data architecture is absent, organizations face:
- Performance bottlenecks in analytics
- Delayed decision-making
- Increased infrastructure costs
- Data silos and duplication
- Governance and compliance risks
These challenges directly impact business agility and innovation.
Strategic Shift: From Systems to Platforms
The enterprise mindset is shifting from isolated systems to unified data platforms. This aligns with insights from Techment’s perspective on Why Microsoft Fabric AI Solutions Are Changing the Way Enterprises Build Intelligence where data architecture is positioned as a core business enabler rather than a backend function.
Executive Insight
Scalable data architecture is no longer an IT investment—it is a business capability. Organizations that design for scale early gain a significant advantage in AI adoption, real-time analytics, and customer experience transformation.
Core Principles of Scalable Data Architecture
Designing a scalable data architecture requires more than selecting tools—it demands adherence to foundational principles that ensure long-term adaptability.
Modularity: Building Independent Components
Modularity allows each component of the architecture—ingestion, processing, storage, and analytics—to operate independently.
Why it matters:
- Enables independent scaling
- Reduces system-wide failures
- Accelerates innovation cycles
For example, separating ingestion pipelines from transformation layers ensures that changes in one do not disrupt the other.
Elasticity: Scaling on Demand
Elasticity ensures that systems dynamically allocate resources based on workload demands.
Cloud platforms such as AWS, Azure, and GCP enable:
- Auto-scaling compute clusters
- Serverless processing
- Cost optimization through usage-based pricing
This is critical for handling unpredictable workloads, especially in real-time analytics.
Data Governance: Trust as a Foundation
As emphasized in the IJFMR research , governance is central to scalable architecture.
Key governance components include:
- Data quality management
- Access control and security
- Compliance (GDPR, CCPA)
- Data lineage tracking
Without governance, scalability leads to chaos rather than value.
For deeper insights, explore Techment’s Data Governance for Data Quality: Future-Proofing Enterprise Data.
Interoperability: Integrating Diverse Data Sources
Enterprises must integrate:
- Structured data (databases)
- Semi-structured data (JSON, logs)
- Unstructured data (images, videos)
Interoperability ensures seamless data flow across systems and platforms.
Core Principles of Scalable Data Architecture
| Principle | Description | Business Impact | Risk if Ignored |
|---|---|---|---|
| Modularity | Independent components for ingestion, processing, and storage | Faster innovation and easier scaling | System-wide failures and slow deployments |
| Elasticity | Dynamic resource scaling based on demand | Cost optimization and performance stability | Over-provisioning or system bottlenecks |
| Data Governance | Policies for quality, security, and compliance | Trustworthy analytics and regulatory compliance | Data inconsistencies and compliance risks |
| Interoperability | Integration across structured and unstructured data sources | Unified enterprise insights | Data silos and fragmented analytics |
Executive Insight
These principles are not optional—they are interdependent. Ignoring one (e.g., governance) undermines the effectiveness of others (e.g., scalability and interoperability).
Architectural Patterns for Enterprise Data Platforms
Choosing the right architectural pattern is one of the most critical decisions in designing scalable data architecture.
Data Lakes: Flexibility at Scale
Data lakes are designed to store vast amounts of raw data in its native format.
Advantages:
- Supports structured and unstructured data
- Enables advanced analytics and machine learning
- Cost-effective storage
Challenges:
- Risk of becoming a “data swamp”
- Requires strong governance
- Complex data discovery
Technologies commonly used include Apache Spark, Hadoop, and cloud-native storage solutions.
Data Warehouses: Performance and Structure
Data warehouses are optimized for structured data and analytical queries.
Advantages:
- High-performance querying
- Strong support for BI tools
- Structured schema ensures consistency
Challenges:
- Limited flexibility
- Requires predefined schema
- Less suitable for unstructured data
They are ideal for reporting, dashboards, and business intelligence workloads.
Hybrid Architecture: Best of Both Worlds
Modern enterprises increasingly adopt hybrid architectures combining data lakes and warehouses.
How it works:
- Raw data ingested into data lakes
- Processed and transformed into warehouses
- Unified analytics layer on top
Advantages:
- Flexibility + performance
- Supports diverse workloads
- Enables AI and BI simultaneously
Challenges:
- Increased complexity
- Requires orchestration
- Governance across systems
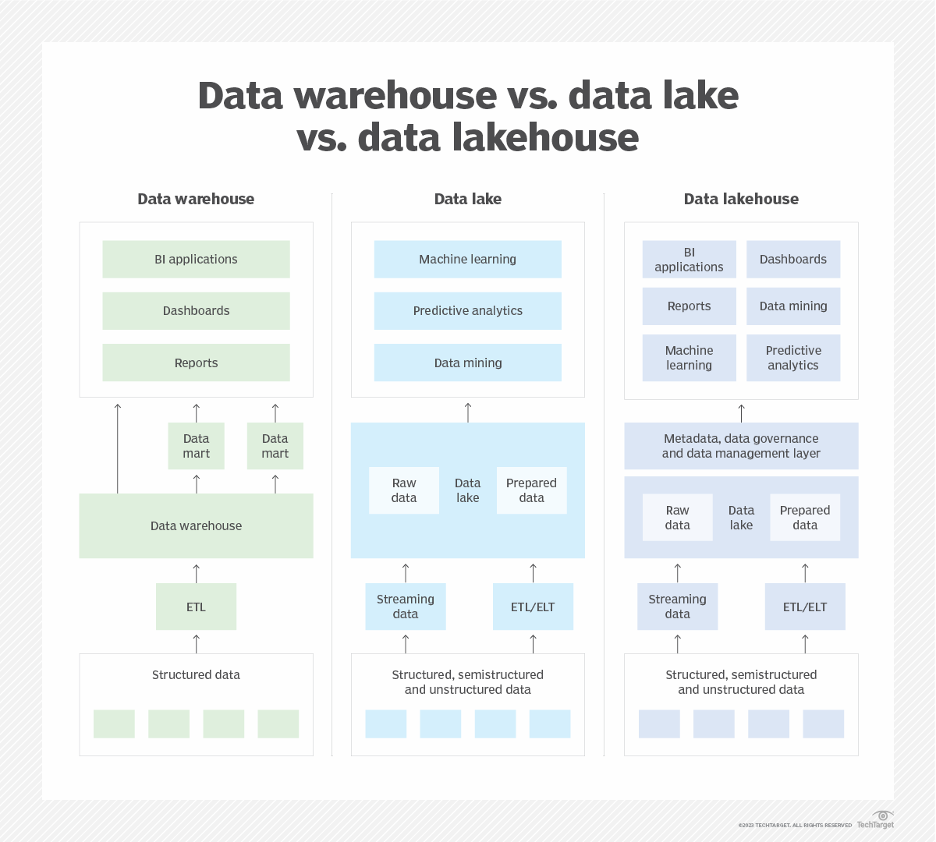
Data Lake vs Data Warehouse vs Hybrid
| Feature | Data Lake | Data Warehouse | Hybrid Architecture |
|---|---|---|---|
| Data Type | Structured + Unstructured | Structured only | Both |
| Schema | Schema-on-read | Schema-on-write | Flexible |
| Performance | Moderate | High | High (optimized layers) |
| Use Case | ML, AI, raw storage | BI, reporting | Enterprise-wide analytics |
| Cost | Lower storage cost | Higher compute cost | Balanced |
| Complexity | Medium | Low | High |
For a deeper comparison, refer to Techment’s Microsoft Data Fabric vs Traditional Data Warehousing.
Executive Insight
Hybrid architectures are not just a trend—they are becoming the default enterprise model. However, success depends on orchestration, governance, and integration.
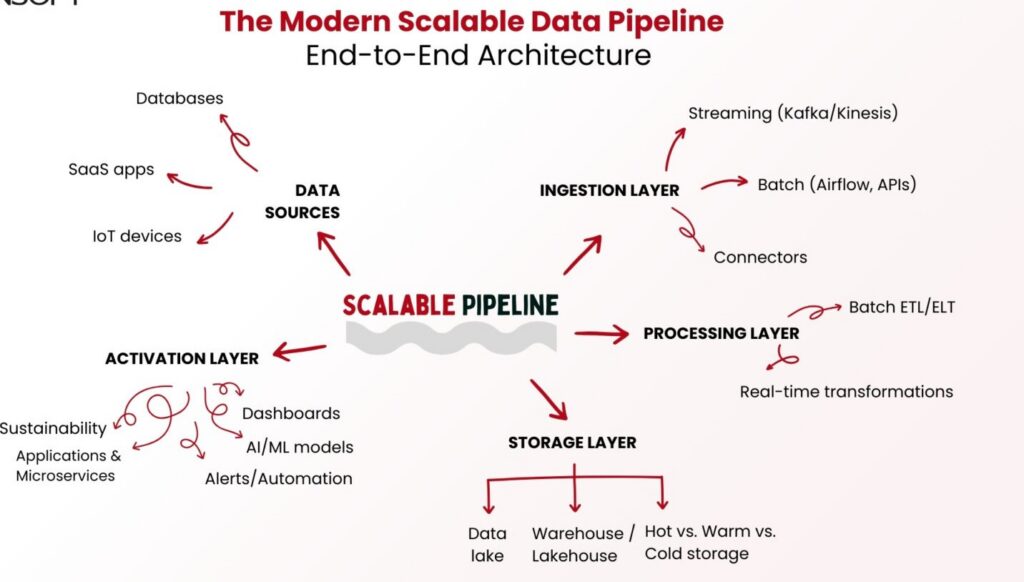
Data Flow Architecture and Ingestion Strategy
Scalable data architecture must handle both real-time and batch data efficiently.
Understanding Data FlowA typical data flow includes:
- Data ingestion (streaming or batch)
- Data processing and transformation
- Storage in data lake or warehouse
- Analytics and consumption
Streaming vs Batch Processing
Streaming Data:
- Real-time ingestion
- Used for IoT, fraud detection, monitoring
- Requires low-latency systems
Batch Data:
- Periodic processing
- Used for reporting and analytics
- More cost-efficient
Pseudocode Perspective
The IJFMR paper provides a simple ingestion model :
- Streaming data → data lake
- Batch data → transformation → data warehouse
This separation ensures efficiency and scalability.
Enterprise Implications
- Real-time systems require event-driven architectures
- Batch systems must optimize for cost and throughput
- Unified pipelines reduce redundancy
Internal Strategy Alignment
Organizations should align ingestion strategies with broader data transformation initiatives like Leveraging Data Transformation for Modern Analytics.
Executive Insight
The real differentiator is not ingestion capability—but orchestration. Enterprises must ensure that data flows are governed, observable, and aligned with business outcomes.
Streaming vs Batch Processing
| Criteria | Streaming Processing | Batch Processing |
|---|---|---|
| Data Latency | Real-time | Delayed |
| Use Cases | Fraud detection, IoT, monitoring | Reporting, historical analysis |
| Infrastructure Cost | Higher | Lower |
| Complexity | High | Moderate |
| Scalability | Requires event-driven systems | Easier to scale |
Best Practices for Designing Scalable Data Architecture
Designing scalable data architecture requires a disciplined approach combining technology, governance, and operational strategy.
Microservices-Based Architecture
Breaking data platforms into microservices enables:
- Independent scaling
- Faster deployment cycles
- Fault isolation
For example:
- Ingestion service
- Transformation service
- Storage service
Each can scale independently.
Data Partitioning and Optimization
Partitioning improves performance by dividing datasets based on:
- Time
- Geography
- Business units
This reduces query load and improves efficiency.
Cloud-Native Design
Cloud platforms provide:
- Infinite scalability
- Managed services
- Cost efficiency
Enterprises should adopt cloud-native architectures rather than lifting legacy systems.
Performance Optimization Techniques
- Indexing frequently accessed data
- Using optimized formats (Parquet, ORC)
- Implementing caching mechanisms
Governance-Driven Architecture
Governance must be embedded, not added later.
Explore Techment’s Data Quality for AI in 2026 for deeper insights.
Executive Insight
Best practices are not static—they evolve with business needs. Continuous optimization and monitoring are essential.
Advanced Performance Optimization in Scalable Data Architecture
As enterprises scale their data platforms, performance optimization becomes a continuous discipline rather than a one-time effort. Poorly optimized architectures can negate the benefits of scalability by introducing latency, inefficiencies, and excessive costs.
Query Optimization Strategies
Modern data platforms must support complex analytical queries across massive datasets. Optimization techniques include:
- Columnar storage formats such as Parquet and ORC to reduce I/O
- Predicate pushdown to filter data early in the query process
- Materialized views for frequently accessed aggregations
- Distributed query engines (e.g., Presto, Spark SQL)
These techniques significantly improve query execution times while reducing compute overhead.
Caching and Acceleration Layers
Caching plays a critical role in scalable data architecture:
- In-memory caching for frequently accessed datasets
- Result caching for repeated queries
- Edge caching for distributed analytics environments
This is especially important for executive dashboards and real-time analytics.
Workload Isolation
Enterprises often struggle with competing workloads:
- BI queries
- Data science workloads
- ETL pipelines
Without isolation, these workloads can impact each other.
Solution:
- Separate compute clusters
- Use workload management policies
- Implement resource governance
Storage Optimization
Efficient storage design is essential for scalability:
- Tiered storage (hot, warm, cold)
- Compression techniques
- Lifecycle management policies
Internal Strategy Alignment
Performance optimization must align with broader enterprise data reliability initiatives such as Driving Reliable Enterprise Data.
Executive Insight
Performance is not just a technical metric—it directly impacts business agility. Faster insights lead to faster decisions, which translate into competitive advantage.
Data Governance Operating Model for Scalable Systems
Scalability without governance leads to disorder. As highlighted in the IJFMR research , governance is a foundational pillar of scalable data architecture.
Governance as a Strategic Capability
Modern governance extends beyond compliance:
- Enables trust in data
- Supports AI and analytics
- Reduces operational risk
Key Components of a Governance Framework
Data Quality Management
- Automated validation rules
- Data profiling
- Continuous monitoring
Data Lineage and Traceability
- Track data from source to consumption
- Ensure auditability
- Support regulatory compliance
Access Control and Security
- Role-based access control (RBAC)
- Attribute-based access control (ABAC)
- Encryption and masking
Metadata Management
- Centralized data catalog
- Data discovery capabilities
- Business glossary alignment
Governance Challenges at Scale
- Managing distributed data environments
- Ensuring consistency across platforms
- Balancing accessibility with security
Techment Perspective
Enterprises must adopt governance frameworks aligned with The Anatomy of a Modern Data Quality Framework to ensure scalability does not compromise trust.
Executive Insight
Governance should not slow down innovation—it should enable it. The most successful enterprises embed governance into their architecture rather than treating it as an afterthought.
AI-Ready Scalable Data Architecture
AI is no longer experimental—it is becoming a core enterprise capability. However, AI success depends heavily on the underlying data architecture.
Why AI Demands Scalable Architecture
AI workloads require:
- Massive datasets
- High-performance processing
- Real-time data pipelines
- High-quality, governed data
Without scalable data architecture, AI initiatives fail to deliver value.
Key Architectural Requirements for AI
Unified Data Platforms
- Break down data silos
- Enable cross-functional analytics
Real-Time Data Processing
- Streaming pipelines for AI inference
- Event-driven architectures
Feature Engineering Pipelines
- Reusable data transformation pipelines
- Scalable feature stores
Data Quality and Consistency
- Critical for model accuracy
- Requires automated validation
Integration with Modern Platforms
Platforms like Microsoft Fabric and cloud-native ecosystems are enabling unified analytics and AI.
Explore Techment’s insights on Microsoft Fabric Architecture: CTO’s Guide to Modern Analytics & AI.
Enterprise Implications
- AI readiness is a data problem, not just a model problem
- Poor architecture leads to unreliable AI outcomes
- Investment in scalable data architecture accelerates AI ROI
Executive Insight
The future of scalable data architecture is AI-driven. Enterprises that design for AI today will lead tomorrow.
Implementation Roadmap for Enterprise Data Leaders
Designing scalable data architecture is not a one-time project—it is a transformation journey.
Phase 1: Assessment and Strategy
- Evaluate current architecture
- Identify scalability gaps
- Define business objectives
Key questions:
- Can current systems handle future data growth?
- Are data silos limiting insights?
- Is governance sufficient?
Phase 2: Architecture Design
- Choose architectural patterns (lake, warehouse, hybrid)
- Define data flows and pipelines
- Establish governance framework
Phase 3: Platform Modernization
- Migrate to cloud or hybrid environments
- Implement scalable storage and compute
- Integrate modern data tools
Phase 4: Operationalization
- Deploy pipelines
- Monitor performance
- Implement observability
Phase 5: Continuous Optimization
- Regular performance tuning
- Governance updates
- Adoption of new technologies
| Phase | Key Activities | Outcome |
|---|---|---|
| Assessment | Evaluate current architecture | Identify gaps and opportunities |
| Design | Define architecture and governance | Blueprint for scalable platform |
| Modernization | Cloud migration, tool implementation | Scalable infrastructure |
| Operationalization | Deploy pipelines and monitoring | Production-ready system |
| Optimization | Continuous tuning and innovation | Sustained performance and scalability |
Internal Alignment
This roadmap aligns with enterprise strategies outlined in Enterprise AI Strategy in 2026.
Executive Insight
Transformation should be incremental, not disruptive. Enterprises must balance innovation with operational stability.
Future Trends in Scalable Data Architecture
The evolution of scalable data architecture is accelerating, driven by emerging technologies and changing business needs.
Data Fabric and Data Mesh
- Data Fabric: Unified architecture integrating data across environments
- Data Mesh: Decentralized data ownership
Both approaches aim to improve scalability and accessibility.
Serverless Data Architectures
- Eliminate infrastructure management
- Enable automatic scaling
- Reduce operational overhead
Real-Time Analytics as Default
Batch processing is no longer sufficient. Real-time analytics is becoming the norm.
AI-Driven Data Management
- Automated data quality checks
- Intelligent data routing
- Predictive performance optimization
Multi-Cloud and Hybrid Architectures
Enterprises are adopting multi-cloud strategies to:
- Avoid vendor lock-in
- Improve resilience
- Optimize costs
Strategic Alignment
Explore Techment’s perspective on Microsoft Azure for Enterprises: Cloud AI Modernization.
Executive Insight
The future of scalable data architecture is autonomous, intelligent, and deeply integrated with business processes.
How Techment Helps Enterprises Build Scalable Data Architecture
Designing scalable data architecture requires more than technology—it requires strategic alignment, execution expertise, and continuous optimization.
Techment partners with enterprises to deliver end-to-end data platform transformation.
Data Strategy and Modernization
- Define enterprise data strategy
- Align architecture with business goals
- Enable data-driven decision-making
Cloud and Platform Implementation
- Implement scalable cloud architectures
- Leverage platforms like Microsoft Fabric
- Optimize storage and compute
Governance and Compliance
- Establish governance frameworks
- Ensure regulatory compliance
- Implement data quality systems
AI and Analytics Enablement
- Build AI-ready data platforms
- Enable real-time analytics
- Accelerate innovation
End-to-End Execution
From strategy to implementation to optimization, Techment ensures that enterprises achieve sustainable scalability.
Conclusion
Scalable data architecture is no longer optional—it is a strategic necessity for enterprises navigating the complexities of modern data ecosystems. From architectural patterns and governance to AI readiness and future trends, every aspect of data architecture must be designed with scalability in mind.
The insights from IJFMR research reinforce a critical point: scalability is not just about handling more data—it is about enabling better decisions, faster innovation, and sustainable growth.
As enterprises move toward AI-driven futures, the importance of scalable data architecture will only increase. Organizations that invest in the right architecture today will be better positioned to lead in tomorrow’s data-driven economy.
Techment stands as a trusted partner in this journey—helping enterprises design, implement, and optimize scalable data platforms that drive real business impact.
FAQ Section
1. What is scalable data architecture in enterprise platforms?
Scalable data architecture refers to designing systems that can handle increasing data volumes, users, and workloads without performance degradation.
2. What is the difference between data lakes and data warehouses?
Data lakes store raw, unstructured data, while data warehouses store structured data optimized for analytics.
3. Why is governance critical in scalable data architecture?
Governance ensures data quality, security, and compliance, which are essential for reliable analytics and decision-making.
4, How does cloud computing enable scalability?
Cloud platforms provide elastic resources, allowing systems to scale dynamically based on demand.
5. How long does it take to implement scalable data architecture?
Implementation timelines vary but typically range from a few months to over a year, depending on complexity.
Related Reads
- Ultimate Guide to Optimizing Spark Workloads in Microsoft Fabric for Data Engineers
- Microsoft Fabric Architecture: CTO’s Guide to Modern Analytics & AI
- Data Governance for Data Quality: Future-Proofing Enterprise Data
- Data Quality for AI in 2026: Enterprise Guide
- Microsoft Fabric vs Power BI: Understanding the Difference
- Microsoft Fabric vs Snowflake: Data Management Showdown
- AI-Ready Enterprise Checklist for Microsoft Fabric Microsoft Fabric vs Power BI: Understanding the Difference
- Microsoft Fabric vs Snowflake: Data Management Showdown
- AI-Ready Enterprise Checklist for Microsoft Fabric





