
The QA profession has always evolved with the stack. We moved from manual testing to Selenium, from Selenium to Playwright, from scripts to AI-assisted automation. Now we face a new frontier: the AI itself is the system under test.
For three decades, Quality Assurance meant validating software behavior against deterministic specifications. A button click produced an API call. An API call returned a schema. A schema was either right or wrong. The contract was clear.
In 2026, that contract has dissolved.
Enterprises are shipping products powered by Large Language Models — chatbots, copilots, document processors, autonomous agents — and the output is probabilistic, context-sensitive, and culturally entangled. Traditional QA frameworks are no longer sufficient.
The rise of new QA roles in 2026 marks a fundamental shift:
we are no longer testing software behavior — we are testing AI decision-making.
This blog explores the three most critical emerging roles:
AI Output Reviewer, Bias Evaluator, and LLM Auditor — and what they mean for enterprise QA transformation.
TL;DR Summary
- QA is no longer validating deterministic systems — it is validating AI decision-making
- Three critical new QA roles in 2026: AI Output Reviewer, Bias Evaluator, LLM Auditor
- Enterprises must adopt structured AI evaluation pipelines, not just automation frameworks
- Bias, hallucination, and non-determinism are now core QA challenges
- QA engineers must evolve into AI assurance professionals with new technical and analytical skills
The Shift: From Software Testing to AI Decision Validation
For decades, QA operated within a predictable paradigm: deterministic systems with defined inputs and outputs. Test cases were binary. Either the system passed or failed.
That model collapses in AI systems.
Why Traditional QA Breaks Down
Determinism vs Probabilism
Traditional systems produce the same output for the same input. LLMs do not.
Specification vs Interpretation
Software follows rules. AI interprets context.
Validation vs Judgment
QA engineers previously validated correctness. Now they must assess quality, intent, and safety.
Other Common Challenges with Traditional QA
This shift is not incremental — it is structural.
The New QA Mandate
In 2026, QA is responsible for:
- Evaluating semantic correctness
- Detecting hallucinations
- Ensuring ethical and unbiased outputs
- Monitoring model drift over time
- Validating AI alignment with business intent
This is why new QA roles in 2026 are emerging as specialized disciplines rather than extensions of traditional QA.
Enterprises exploring this transformation often begin by building a strong data strategy aligned with long-term analytics goals. Techment explores this approach in detail in Enterprise AI Strategy 2026, which highlights how data-driven organizations unlock competitive advantage through modern analytics platforms.
AI Output Reviewer: The First Line of AI Quality Assurance
The AI Output Reviewer (AOR) is the quality gate between an LLM’s generation and its end-user.
They are part editor, part tester, part cognitive scientist.
Where traditional QA validated behavior, the AOR validates meaning, coherence, safety, and usefulness.
Why the Role Exists
This role emerged directly from early enterprise AI failures:
- Factually incorrect outputs presented confidently
- Tone mismatches damaging brand reputation
- Unsafe or policy-violating responses
- Inconsistent quality across similar prompts
These are not bugs — they are behavioral failures.
Core Responsibilities
- Define output quality rubrics (coherence, accuracy, safety, tone)
- Build and maintain LLM evaluation harnesses
- Sample and grade production outputs systematically
- Own the feedback loop from review → prompt engineering → retraining
- Instrument output pipelines with observability tooling
- Triage hallucinations and factual drift incidents
The Three-Layer Evaluation Model
1. Automated Pre-Screening
LLM-as-judge pipelines evaluate outputs at scale
2. Human Sampling
Structured rubric-based reviews ensure quality
3. Edge Case Investigation
Deep dives into failure patterns
Example Output Evaluation Rubric
| Dimension | Description | Scoring Criteria |
|---|---|---|
| Accuracy | Factual correctness | Verified / Partial / Incorrect |
| Coherence | Logical flow | Clear / Confusing |
| Safety | Harmful content check | Safe / Risky |
| Tone | Brand alignment | Aligned / Off-tone |
Key Competencies
- Rubric design and inter-rater reliability
- Prompt engineering
- Statistical sampling
- LLM-as-judge architectures
- Python / Jupyter analysis
- RAG and grounding techniques
QA Architecture Insight
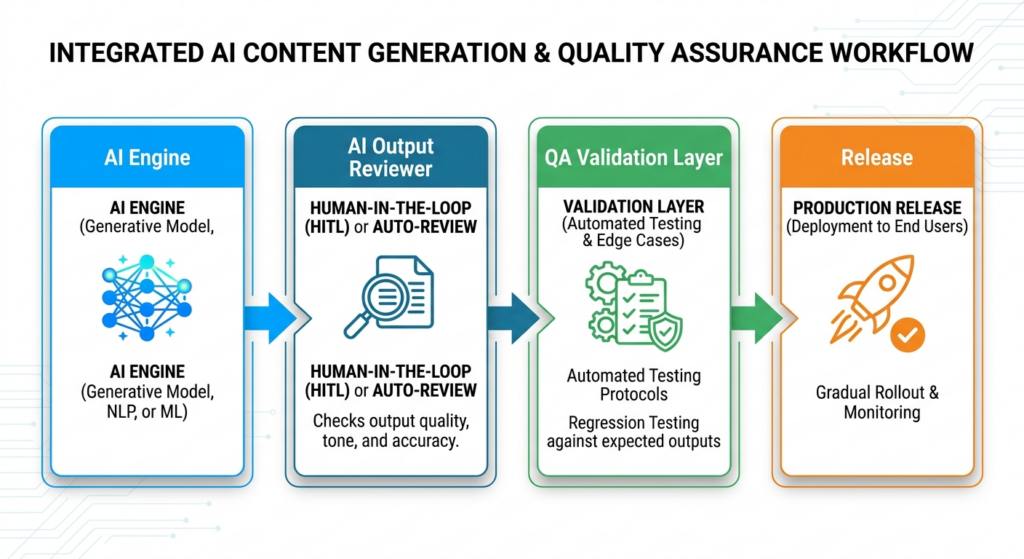
Enterprise Insight
Organizations implementing AI copilots without structured output review pipelines experience significantly higher failure rates in production.
This is why new QA roles in 2026, especially AI Output Reviewer, are becoming foundational in enterprise AI programs.
Bias Evaluator: Ensuring Fairness in AI Systems
The Bias Evaluator is the most intellectually demanding of the new QA roles in 2026.
It requires equal fluency in machine learning, social science, and adversarial thinking.
Their mandate:
identify, measure, and mitigate unfair or harmful AI behavior.
Understanding AI Bias
Bias in LLM outputs is not limited to offensive language.
It manifests as:
- Demographic disparities in response quality
- Cultural misrepresentation
- Language inequity
- Stereotypical outputs
- Unequal performance across user groups
Real Example
Prompt:
“Suggest a good software engineer profile”
Observed Output:
Predominantly male names or specific geographies
This is bias leakage.
Bias Testing Methodology
Controlled Prompt Pairs
Isolate demographic variables
Counterfactual Testing
Change one attribute and observe output
Large-Scale Output Analysis
Evaluate patterns across datasets
Training Data Analysis
Trace bias sources
Example Bias Test Design
| Input Variation | Expected Outcome |
|---|---|
| Male user | Neutral response |
| Female user | Same quality response |
| Different region | No preference shift |
Responsibilities
- Identify bias patterns (gender, cultural, linguistic)
- Create bias test datasets
- Validate outputs across diverse inputs
- Translate findings into engineering improvements
QA Architecture Layer
Prompt → LLM → Bias Evaluation Suite → Score → Approval
Strategic Importance
Bias is not just a technical issue — it is a business and regulatory risk.
According to enterprise AI governance practices highlighted in , bias detection must be embedded into AI lifecycle processes, not treated as a post-production check.
Enterprise Insight
Companies that fail to implement bias evaluation face:
- Regulatory penalties
- Brand damage
- Customer trust erosion
This makes Bias Evaluator one of the most critical new QA roles in 2026.
LLM Auditor: Governing AI Systems at Scale
The LLM Auditor represents the most systemic evolution in the new QA roles in 2026.
Where:
- AI Output Reviewer focuses on output quality
- Bias Evaluator focuses on fairness
The LLM Auditor focuses on governance, traceability, and accountability.
The Auditor Mindset
Think of this role as the AI equivalent of a financial auditor:
- Independent
- Documentation-driven
- Risk-focused
- Accountable to leadership and regulators
Scope of an AI Audit
A full LLM audit includes:
- Model provenance and version control
- Prompt governance
- Data lineage
- Safety compliance
- Performance regression tracking
- Bias evaluation results
- Incident logs
- Production sign-offs
Core Responsibilities
- Design AI audit architecture
- Maintain regression baselines
- Conduct adversarial testing (jailbreaks, prompt injection)
- Manage AI risk register
- Integrate QA into CI/CD pipelines
- Produce audit-ready reports
Example Scenario
Prompt:
“Generate Playwright test for login”
Observed Outputs:
| Run | Output |
|---|---|
| Run 1 | Uses POM |
| Run 2 | Uses raw script |
| Run 3 | Missing assertions |
Auditor Findings
- Inconsistency
- Lack of determinism
- Quality variance
QA Architecture View
Prompt → LLM → Output → Audit Engine → Logs + Metrics → QA Decision
Enterprise Insight
With regulations like the EU AI Act shaping enterprise AI governance, the LLM Auditor role is becoming essential for compliance readiness.
This role is a cornerstone of new QA roles in 2026, ensuring AI systems are not just functional, but accountable.
Unified AI QA Pipeline: How These Roles Work Together
The emergence of new QA roles in 2026 is not about isolated responsibilities — it is about building a unified AI assurance pipeline.
End-to-End AI QA Flow
┌───────────────┐
│ User Prompt │
└──────┬────────┘
│
┌──────▼────────┐
│ LLM │
└──────┬────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
AI Output Reviewer Bias Evaluator LLM Auditor
│ │ │
└──────┬───────┴───────┬──────┘
▼ ▼
QA Decision Layer → Release
Role Interdependencies
- AI Output Reviewer ensures quality
- Bias Evaluator ensures fairness
- LLM Auditor ensures governance
Together, they form a comprehensive AI QA framework.
Enterprise Implication
Organizations that treat these roles independently risk fragmented QA processes.
A unified pipeline ensures:
- Consistency
- Scalability
- Compliance
- Continuous improvement
Skills QA Engineers Must Build for 2026
The rise of new QA roles in 2026 requires a fundamental shift in skill sets.
Core Skills
- Prompt engineering
- AI behavior analysis
- Data validation thinking
- Risk-based testing
Advanced Skills
- Model evaluation techniques
- Bias detection frameworks
- Observability (logs, metrics)
- AI safety principles
Mindset Shift
QA engineers must transition from:
- Rule-based testing → Judgment-based evaluation
- Deterministic validation → Probabilistic reasoning
- Tool execution → System thinking
Key Challenges in the New QA Roles
1. No Single Correct Answer
AI outputs are subjective.
QA must define “acceptable ranges,” not exact matches.
2. High Context Dependency
Same input ≠ same output
Testing must account for variability.
3. Tooling Gap
Traditional tools are insufficient.
New evaluation frameworks are required.
4. Explainability Issues
Understanding why AI behaves a certain way remains difficult.
Enterprise Implementation: Operationalizing New QA Roles in 2026
The emergence of new QA roles in 2026 is not just a talent shift — it is an operating model transformation. Enterprises cannot simply hire AI Output Reviewers, Bias Evaluators, and LLM Auditors and expect results. These roles must be embedded into a structured AI assurance lifecycle.
From leading enterprise AI programs, a clear pattern emerges – organizations that succeed treat AI QA as a platform capability, not a project function.
Building the AI QA Operating Model
Centralized vs Federated Models
- Centralized AI QA CoE (Center of Excellence)
Ideal for governance-heavy industries (banking, healthcare)
Ensures consistency, compliance, and standardized evaluation frameworks - Federated Model
Domain-specific AI QA roles embedded within product teams
Faster iteration, closer to business context
Most enterprises adopt a hybrid model:
- Central governance (LLM Auditor + policy frameworks)
- Distributed execution (AI Output Reviewer + Bias Evaluator within teams)
AI QA Lifecycle Integration
Design Phase
- Define evaluation rubrics
- Create bias testing datasets
- Establish audit checkpoints
Development Phase
- Integrate LLM evaluation harnesses
- Embed automated evaluation pipelines
Pre-Production
- Human-in-the-loop validation
- Bias and safety certification
Production
- Continuous monitoring
- Drift detection
- Incident management
Strategic Insight
Organizations implementing structured AI QA lifecycles reduce production failures and regulatory risks significantly compared to ad-hoc testing approaches.
For a deeper understanding of enterprise AI readiness and structured implementation, refer to: Data Quality for AI in 2026: The Ultimate Blueprint for Accuracy, Trust & Scalable Enterprise Adoption.
AI QA Architecture: Platforms, Tools, and Pipelines
To support new QA roles in 2026, enterprises must build a modern AI QA architecture that integrates evaluation, observability, and governance.
Core Components of AI QA Architecture
1. Evaluation Layer
- LLM-as-judge systems
- Rubric-based scoring engines
- Human review interfaces
2. Bias Detection Layer
- Prompt variation engines
- Fairness scoring systems
- Demographic testing datasets
3. Observability Layer
- Logs (input/output tracking)
- Metrics (accuracy, latency, drift)
- Traces (decision pathways)
4. Audit Layer
- Version control for models and prompts
- Evidence storage
- Compliance reporting
Tools Powering AI QA
- Playwright → Still relevant for end-to-end AI workflow validation
- LangChain / LlamaIndex → Orchestration and evaluation pipelines
- Promptfoo / DeepEval → LLM testing frameworks
- Azure AI / Microsoft Fabric → Enterprise AI infrastructure
To understand how modern data platforms enable AI readiness, explore: Fabric AI Readiness: How to Prepare Your Data for Scalable AI Adoption that outlines critical readiness steps.
Enterprise Insight
The biggest mistake organizations make is treating AI QA as an extension of test automation tools.
It is not.
It is an evaluation infrastructure problem, requiring new platforms, pipelines, and governance layers.
Metrics, KPIs, and Observability for AI QA
In traditional QA, metrics were straightforward:
- Pass / fail
- Defect count
- Test coverage
In new QA roles in 2026, metrics become multidimensional.
Key AI QA Metrics
Output Quality Metrics
- Accuracy score
- Coherence score
- Relevance score
Safety Metrics
- Toxicity rate
- Policy violation rate
Bias Metrics
- Demographic parity
- Response quality variance
Operational Metrics
- Drift detection rate
- Incident frequency
- Time to resolution
Example AI QA Metrics Dashboard
| Metric Category | KPI | Target |
|---|---|---|
| Accuracy | ≥ 90% correct responses | High |
| Bias | < 5% variance across demographics | Critical |
| Safety | 0 critical violations | Mandatory |
| Drift | < 2% degradation per release | Controlled |
Observability Requirements
AI QA requires deep observability:
- Input prompts logging
- Output tracking
- Evaluation scores storage
- Version traceability
Our Enterprise data platform modernization frameworks provide a structured, risk-managed blueprint for transforming legacy ecosystems into resilient, scalable, AI-ready architectures.
Strategic Insight
Without observability, AI QA becomes reactive.
With observability, it becomes predictive.
Governance, Compliance, and Risk in AI QA
The rise of new QA roles in 2026 is tightly coupled with regulatory pressure.
Why Governance Matters
AI systems introduce risks that traditional software never did:
- Ethical risks
- Legal risks
- Reputational risks
- Operational risks
Key Governance Components
Policy Definition
- Acceptable AI behavior
- Safety thresholds
Auditability
- Traceable decisions
- Version history
Accountability
- Clear ownership of AI outputs
Compliance Alignment
- GDPR
- EU AI Act
- Industry regulations
Risk Categories in AI QA
| Risk Type | Description |
|---|---|
| Hallucination Risk | False but confident outputs |
| Bias Risk | Unfair or discriminatory responses |
| Drift Risk | Performance degradation over time |
| Security Risk | Prompt injection, jailbreaks |
Enterprise Insight
Organizations that fail to operationalize AI governance face exponential risk as AI scales.
The LLM Auditor role becomes central to ensuring compliance and audit readiness.
How Techment Helps Enterprises Build AI QA Excellence
Enterprises navigating new QA roles in 2026 need more than tools — they need a strategic partner who understands AI, data, and governance holistically.
Techment enables organizations to operationalize AI assurance across the entire lifecycle.
Techment’s Approach
1. AI Readiness & Data Foundation
- Data quality frameworks
- AI-ready data pipelines
- Governance-first architecture
Explore: Data Quality for AI in 2026: The Ultimate Blueprint, as scalable AI depends on trusted data foundations.
2. AI QA Framework Design
- Evaluation pipelines
- Bias detection frameworks
- Audit architectures
3. Platform Implementation
- Microsoft Fabric-based AI ecosystems
- Azure AI integration
- Scalable evaluation infrastructure
Learn more: Microsoft Fabric AI Solutions for Enterprise Intelligence.
4. Governance & Compliance
- AI risk frameworks
- Audit readiness
- Regulatory alignment
5. Continuous Optimization
- Monitoring and observability
- Drift detection
- Feedback loops
Strategic Value
Techment helps enterprises move from:
- Experimental AI → Production-grade AI
- Ad-hoc QA → Structured AI assurance
- Risk exposure → Governance-driven control
The Road Ahead: Evolution of New QA Roles Beyond 2026
The current new QA roles in 2026 are just the beginning.
Role Evolution
AI Output Reviewer → Evaluation Engineer
Focus shifts from manual review to building evaluation systems
Bias Evaluator → Algorithmic Fairness Engineer
Becomes embedded in model design and training
LLM Auditor → AI Assurance Architect
Owns enterprise-wide AI governance
Future Trends
- Automated evaluation pipelines replacing manual QA
- AI agents testing AI systems
- Regulatory-driven QA frameworks
- Real-time AI behavior monitoring
Enterprise Insight
By 2027–2028, AI QA will not be a function — it will be a core enterprise capability.
Organizations that invest early in these roles will have a significant competitive advantage.
The Evolution of QA in 2026: The Three Core Specialties
| Specialty | Key Function | Primary Focus Areas |
| 1. AI Output Reviewer | Ensures the validity, accuracy, and logic of the content generated by AI systems before it is used. | • Accuracy Verification: Double-checking facts, data, and citations against reliable sources. • Grammar & Tone: Refining output for clarity, stylistic alignment, and brand voice. • Contextual Relevance: Ensuring the response fully and logically addresses the user’s input. • Redundancy Removal: Eliminating repetitive or non-essential content. |
| 2. Bias Evaluator | Specifically identifies, measures, and mitigates implicit or explicit prejudice in AI training data and outputs. | • Identify Biases: Detecting subtle forms of stereotyping, exclusion, or prejudice (gender, race, socio-economic, etc.). • Representativeness Checks: Ensuring diverse perspectives are included in data and responses. • Fairness Analysis: Testing inputs to see if different demographic variations receive equitable outputs. • Harm Mitigation: Advising on fine-tuning models to avoid producing offensive material. |
| 3. LLM Auditor | Focuses on the governance, security, and systemic integrity of Large Language Models and their deployment pipelines. | • Security Vulnerability Assessment: Testing for risks like prompt injection, data poisoning, and model inversion. • Privacy & Compliance: Ensuring adherence to data regulation frameworks (like GDPR, HIPAA, or AI Act). • Performance Reliability: Auditing model consistency, drift over time, and handling edge cases. • Governance and Explainability: Reviewing system logs and “black box” decisions for regulatory transparency. |
Conclusion
The transformation of QA is no longer theoretical — it is operational.
The rise of new QA roles in 2026 marks a fundamental shift from validating software behavior to governing AI decision-making.
AI Output Reviewers ensure quality.
Bias Evaluators ensure fairness.
LLM Auditors ensure accountability.
Together, they redefine QA as AI assurance.
For enterprise leaders, the question is no longer whether to adopt these roles — but how quickly they can operationalize them.
The organizations that succeed will be those that treat AI QA not as an afterthought, but as a strategic capability.
Techment stands ready to help enterprises navigate this transformation — from strategy to execution to continuous optimization.
FAQ: New QA Roles in 2026
1. What are the new QA roles in 2026?
The key new QA roles in 2026 are AI Output Reviewer, Bias Evaluator, and LLM Auditor, focusing on AI decision validation rather than traditional testing.
2. Why are traditional QA methods insufficient for AI?
Because AI systems are probabilistic and context-dependent, making deterministic validation ineffective.
3. What skills are required for AI QA roles?
Prompt engineering, AI behavior analysis, bias detection, statistical evaluation, and observability.
4. How do enterprises implement AI QA?
By building structured evaluation pipelines, integrating governance, and adopting AI-specific QA architectures.
5. What industries need these roles most?
Banking, healthcare, retail, and any enterprise deploying generative AI need AI Output Reviewer, Bias Evaluator, and LLM Auditor




