Introduction
LLM regression testing is rapidly becoming a critical discipline as enterprises embed generative AI into core systems, products, and decision workflows. Traditional regression testing relied on determinism—given an input, the output remained consistent. That assumption no longer holds true in the era of large language models.
Modern LLMs are inherently probabilistic. The same prompt can produce variations in structure, tone, and even factual interpretation. While this flexibility powers innovation in customer experiences, analytics, and automation, it also introduces ambiguity in testing. What does “correct” mean when outputs are not fixed? And how do enterprises ensure consistency without suppressing the creative strengths of AI?
This shift is not merely technical—it is strategic. According to enterprise AI adoption patterns highlighted in resources like Enterprise AI strategy in 2026 , organizations are moving from experimentation to production-scale deployment. At this stage, reliability, governance, and quality assurance become non-negotiable.
This blog explores two foundational approaches to LLM regression testing—golden datasets and random sampling—and explains how enterprises can combine them into a scalable, future-ready testing framework.
TL;DR Summary
- LLM regression testing requires new strategies due to probabilistic outputs
- Golden datasets provide precision for critical workflows
- Random sampling enables real-world validation and edge-case discovery
- Enterprises should adopt a layered testing strategy combining both approaches
- Human judgment remains essential for evaluating tone, accuracy, and intent
- Continuous feedback loops improve long-term model performance and trust
Why LLM Regression Testing Demands a New Paradigm
From Deterministic Systems to Probabilistic Intelligence
Traditional software systems operate within predictable boundaries. APIs return defined outputs, workflows follow structured logic, and regression testing is essentially a verification exercise. If expected outputs match actual results, the system is considered stable.
LLM regression testing breaks this model entirely.
Large language models generate outputs based on probabilities, context windows, and training distributions. Even minor changes—prompt phrasing, temperature settings, or system updates—can influence outcomes. This introduces variability that traditional testing frameworks are not designed to handle.
In enterprise environments, this variability directly impacts:
- Customer-facing AI assistants
- Automated reporting systems
- Knowledge retrieval platforms
- Decision-support tools
The implication is clear: regression testing must evolve from deterministic validation to probabilistic evaluation.
To understand how enterprises are adapting, refer to Best Practices for Generative AI Implementation in Business — A Practical Guide for Enterprises , which highlights the growing need for structured AI governance and validation frameworks.
The Strategic Impact on Enterprise AI
For CTOs and data leaders, LLM regression testing is not just a QA concern—it is a business risk management function.
Poorly tested models can lead to:
- Inconsistent customer experiences
- Compliance violations
- Brand reputation risks
- Incorrect business insights
As outlined in RAG Models enterprise AI success depends on trust, consistency, and governance—not just model performance.
This is why LLM regression testing must be embedded into the broader enterprise data and AI strategy, rather than treated as an isolated engineering task.
Understanding the Nature of LLM Regressions
What Constitutes a Regression in LLM Systems?
Unlike traditional systems, regressions in LLMs rarely appear as outright failures. Instead, they manifest as subtle degradations in quality, consistency, or relevance.
Common regression patterns include:
- Reduced contextual relevance in responses
- Tone misalignment with brand or persona
- Increased hallucinations or factual inaccuracies
- Structural inconsistencies in outputs
- Emergence of unintended biases
These issues often exist on a spectrum rather than as binary failures. This makes detection significantly more complex.
For example:
A customer service chatbot might still respond correctly but shift tone from professional to overly casual. Technically, it works—but from a business perspective, it has regressed.
Measuring Quality in a Non-Binary World
The challenge of LLM regression testing lies in defining measurable quality metrics.
Enterprises must evaluate:
- Semantic accuracy
- Contextual relevance
- Tone and style consistency
- Completeness of response
- Compliance adherence
Learn more about how we help organizations embed AI-powered testing into their development lifecycle through our AI-testing services.
Why Traditional Testing Fails
Traditional regression testing relies on exact match validation. This approach fails in LLM systems because:
- Multiple valid outputs may exist
- Language is inherently flexible
- Context influences interpretation
Therefore, enterprises must shift toward probabilistic evaluation models that assess distributions, patterns, and trends rather than fixed outputs.
Golden Datasets in LLM Regression Testing: Precision and Control
What Are Golden Datasets?
Golden datasets are curated collections of prompts paired with expected outputs or evaluation criteria. They are designed to represent high-value, business-critical scenarios.
In LLM regression testing, golden datasets act as the “ground truth” baseline.
They are typically:
- Created by domain experts
- Validated through multiple iterations
- Aligned with enterprise objectives
These datasets provide a controlled environment for evaluating model behavior.
Where Golden Datasets Deliver Maximum Value
Golden datasets are particularly effective in scenarios where precision and consistency are essential.
Business-critical workflows
Financial reporting, healthcare summaries, and legal documentation require high accuracy. Even minor deviations can have serious consequences.
Compliance-sensitive environments
Regulated industries demand strict adherence to guidelines. Golden datasets ensure outputs remain compliant over time.
High-visibility user journeys
Customer-facing applications must maintain consistent tone and quality to build trust.
Release validation pipelines
Golden datasets provide clear pass/fail signals, enabling confident deployment decisions.
These use cases align with enterprise governance strategies outlined in Driving Reliable Enterprise Data.
Strengths of Golden Datasets
Golden datasets offer several advantages in LLM regression testing:
- Deterministic validation within probabilistic systems
- High confidence in critical scenarios
- Clear benchmarking for model performance
- Strong alignment with business requirements
They effectively create a “safety net” for enterprise AI systems.
Discover how we helped one of our clients save manual testing efforts, enabling redirection towards strategic planning in our latest case study.
Limitations of Golden Datasets
Despite their strengths, golden datasets have inherent limitations.
Static nature
They represent a snapshot of expected behavior. As models evolve, datasets can become outdated.
Limited coverage
No dataset can fully capture real-world variability.
Risk of overfitting
Models may perform well on curated tests but fail in broader contexts.
Maintenance overhead
Continuous updates are required to maintain relevance.
These limitations highlight why golden datasets alone are insufficient for comprehensive LLM regression testing.
In the comprehensive guide on Golden datasets for GenAI testing, we explore how to build, maintain, and operationalize golden datasets that act as reliable GenAI benchmarks.
Random Sampling in LLM Regression Testing: Breadth and Realism
What Is Random Sampling?
Random sampling involves evaluating LLM performance using diverse, unstructured inputs drawn from:
- Real user interactions
- Synthetic prompt generators
- Hybrid datasets
Unlike golden datasets, random sampling focuses on overall behavior rather than exact output matching.
Why Random Sampling Matters in Enterprise AI
Random sampling introduces variability that mirrors real-world usage.
This approach enables organizations to:
- Discover edge cases
- Detect subtle quality regressions
- Evaluate generalization capabilities
- Monitor performance over time
It provides a broader, more realistic view of model behavior.
As highlighted in Data Discovery Solutions, uncovering hidden patterns and anomalies is essential for scalable AI systems—and random sampling plays a critical role in this process.
Key Advantages of Random Sampling
Real-world coverage
Captures diverse user behaviors and inputs.
Edge case discovery
Identifies scenarios that curated datasets may miss.
Continuous evaluation
Supports ongoing monitoring in production environments.
Scalability
Enables large-scale testing across thousands of prompts.
Challenges of Random Sampling
However, random sampling introduces complexity.
Lack of deterministic evaluation
Without predefined outputs, assessment becomes subjective.
Dependence on scoring models
Requires heuristic or AI-based evaluation methods.
Complex analysis
Results must be interpreted using statistical trends rather than binary outcomes.
Cross-functional collaboration
Requires alignment between engineering, QA, and domain experts.
These challenges make random sampling more suitable for exploratory and monitoring layers rather than strict release gating.
Golden Datasets vs Random Sampling: Why Enterprises Need Both
A False Dichotomy
Many organizations approach LLM regression testing as a choice between golden datasets and random sampling. This is a strategic mistake.
These approaches are not competing—they are complementary.
Golden datasets provide depth.
Random sampling provides breadth.
Together, they form a comprehensive testing strategy.
| Dimension | Golden Datasets | Random Sampling |
|---|---|---|
| Coverage | Limited | Extensive |
| Precision | High | Moderate |
| Scalability | Low | High |
| Evaluation Type | Deterministic | Probabilistic |
| Use Case | Critical workflows | Real-world validation |
| Maintenance | High | Moderate |
Mapping Strengths to Enterprise Needs
Golden datasets excel in:
- Stability
- Precision
- Compliance
- Release validation
Random sampling excels in:
- Discovery
- Adaptability
- Real-world alignment
- Continuous monitoring
This dual approach aligns with modern enterprise AI architectures described in Microsoft Fabric Architecture: CTO’s Guide to Modern Analytics & AI.
Strategic Insight for Leaders
For enterprise leaders, the key takeaway is this:
LLM regression testing is not about eliminating uncertainty—it is about managing it effectively.
Golden datasets reduce risk in known scenarios.
Random sampling uncovers unknown risks.
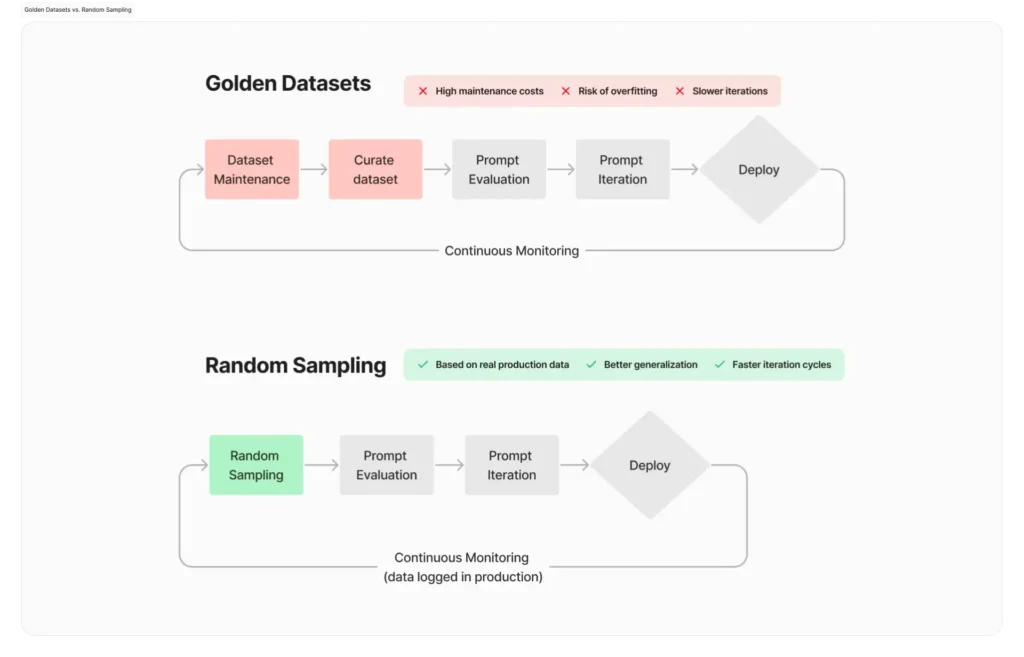
A mature testing strategy integrates both into a unified framework.
A Layered LLM Regression Testing Strategy for Enterprises
Building a Multi-Layer Testing Framework
Successful enterprises adopt a layered approach to LLM regression testing.
This framework typically includes four layers:
Baseline Protection Layer
At the core are golden datasets.
These datasets:
- Cover critical business scenarios
- Act as release gating mechanisms
- Provide deterministic validation signals
Any deviation in this layer is treated as high priority.
Exploratory Evaluation Layer
Random sampling operates in this layer.
Its purpose is to:
- Explore model behavior across diverse inputs
- Identify emerging issues
- Evaluate generalization
This layer is less about pass/fail and more about insight.
Monitoring and Feedback Layer
In production, random sampling extends into continuous monitoring.
This enables organizations to:
- Detect model drift
- Identify new failure patterns
- Track performance trends over time
This aligns with principles discussed in Leveraging Data Transformation for Modern Analytics.
Iterative Refinement Layer
Insights from random sampling feed back into golden datasets.
This creates a continuous improvement loop:
- New edge cases are identified
- They are formalized into curated tests
- The testing framework evolves over time
The Role of Human Judgment in LLM Regression Testing
Why Human Evaluation Remains Irreplaceable
Even the most advanced automated evaluation systems cannot fully capture the nuance of human language. LLM regression testing, by its very nature, involves interpreting meaning, tone, and intent—dimensions that resist purely algorithmic validation.
While enterprises are investing in automated scoring models and evaluation frameworks, human judgment continues to serve as the ultimate arbiter of quality.
This is particularly critical for:
- Tone alignment with brand voice
- Contextual appropriateness in complex queries
- Ethical and bias-sensitive outputs
- Ambiguity resolution in borderline cases
For example, a model may generate factually correct content but fail to align with enterprise communication standards. Automated systems may pass it—but a human reviewer would flag it as a regression.
This reinforces a key principle: LLM regression testing is not just a technical function—it is a human-in-the-loop system.
Where Human Judgment Adds Maximum Value
Golden dataset curation
Domain experts define what “good” looks like, ensuring datasets reflect real business expectations.
Evaluation calibration
Human reviewers help fine-tune scoring models used in random sampling.
Edge case interpretation
Ambiguous outputs require contextual understanding beyond algorithmic scoring.
Continuous quality refinement
Human feedback loops ensure testing frameworks evolve alongside enterprise needs.
Balancing Automation and Human Insight
The goal is not to replace human evaluation but to optimize it.
Enterprises should adopt a hybrid model:
- Automation for scale and consistency
- Human evaluation for depth and nuance
This balance is essential for sustainable LLM regression testing at scale.
Operationalizing LLM Regression Testing in Enterprises
From Strategy to Execution
Designing an LLM regression testing strategy is only the first step. The real challenge lies in operationalizing it across enterprise environments.
This requires aligning people, processes, and platforms.
Key Operational Components
Version Control and Traceability
Every component of the testing framework must be versioned:
- Prompts
- Datasets (golden + sampled)
- Model versions
- Evaluation criteria
This ensures reproducibility and accountability—critical for enterprise governance.
Defined Quality Metrics
Organizations must establish clear metrics for LLM regression testing, such as:
- Relevance score thresholds
- Accuracy benchmarks
- Tone consistency indices
- Hallucination rates
These metrics transform subjective evaluation into measurable outcomes.
Read in detail on how by leveraging modern reporting tools, enterprises can drive both quality and speed at scale in our latest blog.
CI/CD Integration
LLM regression testing should be embedded into development pipelines:
- Golden datasets act as release gates
- Random sampling provides continuous feedback
- Automated alerts flag regressions early
This ensures that quality assurance is not a post-deployment activity but an integral part of development.
Scalability of Evaluation
Random sampling requires infrastructure capable of handling large-scale evaluations.
This includes:
- Distributed testing pipelines
- Scalable scoring systems
- Data storage for evaluation logs
Cross-Functional Collaboration
LLM regression testing is inherently interdisciplinary.
It requires collaboration between:
- Engineering teams
- QA specialists
- Data scientists
- Domain experts
- Product leaders
This cross-functional alignment is critical for meaningful outcomes.
Advanced Enterprise Framework: Metrics, Signals, and Evaluation Models
Moving Beyond Binary Testing
In LLM regression testing, success is not defined by pass/fail outcomes. Instead, enterprises must adopt a signal-based evaluation model.
This involves analyzing:
- Output distributions
- Performance trends
- Statistical deviations
- User feedback signals

Risks, Trade-offs, and Strategic Considerations
The Hidden Risks in LLM Regression Testing
Enterprises that fail to adopt robust LLM regression testing face significant risks:
Over-reliance on golden datasets
Leads to blind spots and poor generalization.
Excessive dependence on random sampling
Results in inconsistent evaluation and lack of control.
Lack of governance
Creates compliance and reputational risks.
Insufficient human oversight
Leads to missed qualitative regressions.
These risks are closely tied to broader enterprise AI challenges discussed in AI Strategy for Enterprises in 2026 .
Trade-offs Leaders Must Navigate
- Precision vs coverage
- Automation vs human judgment
- Speed vs reliability
- Innovation vs risk control
Strategic leaders must balance these dimensions rather than optimizing for a single metric.
How Techment Helps Enterprises
Building Scalable LLM Regression Testing Frameworks
Techment enables enterprises to design and operationalize robust LLM regression testing strategies aligned with business goals.
Data and AI Strategy Alignment
We help organizations align testing frameworks with broader AI initiatives through
AI-Ready Data Foundations
Testing is only as strong as the data behind it. Our expertise in Data Discovery Solutions ensures high-quality datasets for evaluation.
Enterprise Data Reliability and Governance
We integrate testing frameworks with governance models
End-to-End Implementation
From roadmap to execution, Techment delivers:
- Golden dataset design and management
- Random sampling frameworks
- Evaluation pipelines
- Monitoring and feedback systems
This ensures enterprises move beyond experimentation to production-grade AI systems with confidence.
Conclusion
LLM regression testing represents a fundamental evolution in how enterprises approach quality assurance. The shift from deterministic systems to probabilistic models requires new frameworks, new metrics, and a new mindset.
Golden datasets and random sampling are not competing approaches—they are complementary pillars of a robust testing strategy. One ensures precision and control, while the other provides breadth and real-world validation.
Together, they enable organizations to manage uncertainty rather than eliminate it.
As enterprises scale their AI initiatives, the ability to continuously evaluate, refine, and govern LLM behavior will become a defining capability. Those who invest in structured LLM regression testing today will be better positioned to build trustworthy, scalable, and high-performing AI systems tomorrow.
Techment stands as a strategic partner in this journey—helping enterprises design, implement, and optimize AI systems that are not only powerful but also reliable and accountable.
FAQ Section
1. What is LLM regression testing?
LLM regression testing evaluates whether updates to a language model degrade performance, quality, or consistency across scenarios.
2. When should enterprises use golden datasets?
Golden datasets are best for critical workflows, compliance-sensitive use cases, and release validation pipelines.
3. Is random sampling reliable for testing AI models?
Yes, but it requires well-defined evaluation metrics and often human calibration to ensure consistency.
4. Can LLM regression testing be fully automated?
No. While automation plays a major role, human judgment remains essential for evaluating nuance, tone, and context.
5. How often should LLM testing frameworks be updated?
Continuously. Enterprises should refine datasets and evaluation models based on new insights and evolving user behavior.