
Enterprise data quality and governance have become foundational requirements for organizations scaling analytics, automation, and AI. As data ecosystems grow more complex, enterprises are no longer challenged by data volume alone — they are challenged by trust, accountability, and reliability. Without strong data quality and governance, even the most advanced analytics platforms and AI initiatives fail to deliver value.
This guide explains how enterprises can design a practical, scalable enterprise data quality and governance model that supports analytics accuracy, AI readiness, regulatory compliance, and measurable business outcomes.
Why Enterprise Data Quality and Governance Matter Now
In modern enterprises, data powers everything from executive dashboards to real-time AI-driven decisions. When data quality is poor or governance is unclear, the consequences extend far beyond reporting errors.
Poor enterprise data quality and governance lead to:
- Inaccurate or inconsistent decision-making
- Failed AI and machine learning initiatives
- Regulatory and compliance risk
- Erosion of trust across business teams
- Reduced customer experience ROI
As enterprises adopt AI at scale, the tolerance for unreliable or poorly governed data has effectively dropped to zero.
Data quality is no longer a back-office concern — it is now a board-level risk and revenue issue for enterprises scaling analytics, automation, and AI. As organizations move toward AI-driven decisioning, leaders are no longer asking whether they have enough data, but whether their data is reliable, governed, explainable, and safe to use at scale. Poor data quality directly undermines customer experience ROI, breaks machine-learning pipelines, and exposes organizations to regulatory and reputational risk. This guide explains significance of enterprise data quality and governance operating model — one that embeds quality into data pipelines, enforces accountability, and creates the trust foundation required for analytics, AI, and compliance.
Research supports this shift. IDC’s 2024 analysis revealed that poor-quality data costs enterprises an average of $12.9M per year, while Gartner notes that AI initiatives fail primarily due to inadequate data quality, lineage, and governance. In an age of LLMs, real-time decisioning, and AI copilots, “good enough” data is no longer acceptable.
This is why Microsoft Fabric data quality is emerging as a critical pillar in modern data architecture. Fabric provides a unified analytics platform where data quality can be enforced upstream — at ingestion, transformation, and preparation — rather than relying on downstream fixes.
Yet quality is only half the equation. Governance is the other.
This is where Microsoft Purview is indispensable. Fabric ensures operational quality; Purview ensures organizational trust, accountability, visibility, and compliance. Learn more in our partnership page and understand the strategic benefits we bring as a solutions partner.
TL;DR
- Ensuring enterprise data quality and governance is now a strategic business imperative, not a technical afterthought.
- Fabric provides native capabilities across Lakehouse, Warehouse, Dataflows Gen2, and Notebooks to enforce schema, validate data, detect anomalies, and profile datasets.
- Purview adds enterprise-wide governance — lineage, classification, policies, ownership, and compliance — closing the loop between operational quality and organizational trust.
- Together, Fabric and Purview form an enterprise data quality and governance framework enabling organizations to deliver trustworthy analytics, resilient AI, and regulatory-ready data products.
- Techment, as a Microsoft Partner, brings accelerators and governance frameworks to implement Fabric and Purview at enterprise scale.
Why Data Quality Is Now a Board-Level Priority
As enterprises scale their data platforms to support analytics and AI, data quality has emerged as a foundational concern rather than a downstream cleanup activity. Poor-quality data not only erodes trust in dashboards and reports, but also directly impacts machine learning outcomes, automation reliability, and regulatory compliance. In this context, Microsoft Fabric provides multiple native capabilities to design data quality workflows, while Microsoft Purview adds the governance layer required for enterprise-wide oversight.
Data quality has moved from being a technical hygiene activity to a strategic enabler of enterprise performance. With organizations deploying AI at scale, the quality of data directly influences:
- Decision accuracy
- Model precision
- Automation reliability
- Compliance integrity
- Customer experience
Traditional BI and analytics teams could tolerate imperfections. In AI systems, those imperfections become multiplied risks. A poor-quality attribute in a dataset may slightly distort a dashboard — but the same defect in an ML training pipeline can create discriminatory outcomes, flawed recommendations, or regulatory violations.
Read what Microsoft Fabric is, how it works, why organizations are rapidly adopting it, and what leaders must know in our latest blog – What Is Microsoft Fabric? A Comprehensive Overview for Modern Data Leaders.
Enterprise Data Quality vs. Data Governance: Understanding the Difference
Although closely related, enterprise data quality and governance serve different but complementary roles.
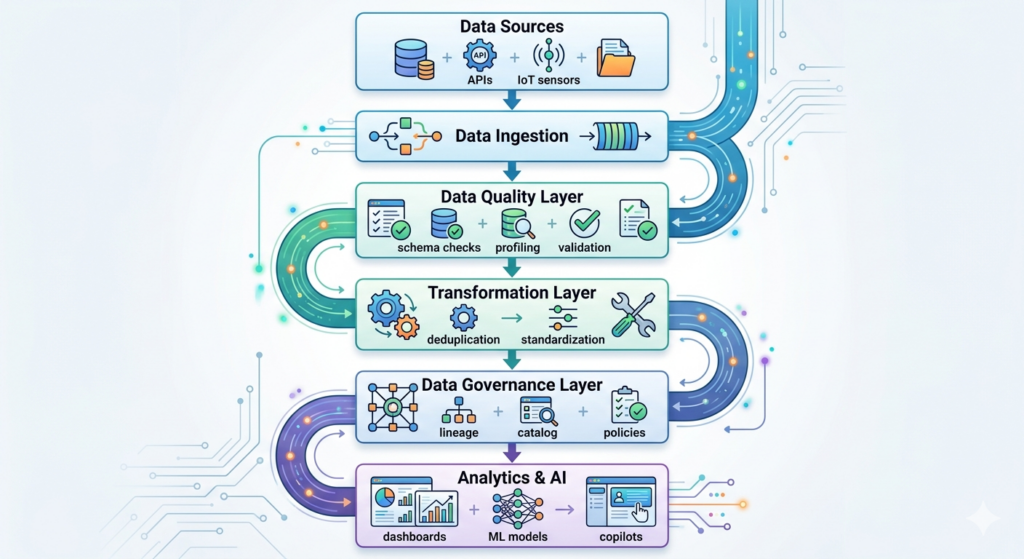
Enterprise data quality focuses on:
- Accuracy, completeness, and consistency of data
- Validation rules and quality checks
- Monitoring freshness, anomalies, and drift
- Ensuring data is fit for analytics and AI use
Enterprise data governance focuses on:
- Ownership and accountability
- Lineage and traceability
- Access controls and security
- Compliance, policies, and standards
Enterprise Data Quality vs Data Governance
| Dimension | Data Quality | Data Governance |
|---|---|---|
| Focus | Data reliability | Data control |
| Objective | Accurate analytics | Trust & compliance |
| Activities | Validation, dedupe, monitoring | Ownership, policies, lineage |
| Ownership | Data engineering | Data governance office |
Enterprises struggle when they treat governance as a substitute for quality, or quality as a one-time cleanup effort. Sustainable success requires both working together.
Why Enterprises Can No Longer Treat Data Quality as a Cleanup Activity
Modern enterprises operate in environments defined by:
1. Hyperconnectivity
Data streams originate from IoT sensors, CRM platforms, SaaS systems, operational apps, and partner ecosystems.
2. High velocity
Business decisions increasingly depend on real-time signals, not weekly batch reports.
3. AI-centric operating models
LLMs, copilots, predictive models, and automated decisions all rely on high-quality, governed, explainable data.
4. Tightening regulations
Regulators expect clear lineage, defensible controls, and accountable data ownership.
Explore frameworks for architecture, implementation, and scaling conversational AI securely and efficiently in our latest blog on Conversational AI on Microsoft Azure: Building Intelligent Enterprise Assistants.
Data Quality Metrics Dashboard
| Metric | Description | Target |
|---|---|---|
| Data completeness | % fields populated | >98% |
| Data accuracy | % records passing validation | >97% |
| Freshness | Data latency | <5 minutes |
| Consistency | Cross-system match rate | >95% |
| Anomaly rate | % abnormal records | <1% |
How Modern Data Platforms Enforce Data Quality by Design
Traditional data quality frameworks depend on standalone tools, disconnected workflows, and external monitoring. Microsoft Fabric integrates quality into:
- Storage (OneLake)
- Transformation (Spark & SQL)
- Pipelines (Data Factory)
- Low-code ingestion (Dataflows Gen2)
- Exploratory analysis (Notebooks & Data Wrangler)
This unification allows enterprises to enforce quality where data lives, where transformations occur, and where analysts consume it.
Explore how unified analytics enhances decisions and why Microsoft solutions partner can accelerate your market growth in our latest blog on Microsoft Data Fabric vs Traditional Data Warehousing: What Leaders Need to Know
Designing an Enterprise Data Quality and Governance Operating Model
A scalable enterprise data quality and governance approach is not tool-driven — it is operating-model driven.
Effective models share five characteristics:
1. Quality Embedded in Data Pipelines
Data validation is enforced at ingestion and transformation stages, not downstream in reports. This prevents bad data from spreading across systems.
2. Governance Aligned to Business Accountability
Clear ownership is defined for data domains, ensuring quality issues have accountable owners and resolution paths.
3. Continuous Monitoring, Not Periodic Audits
Enterprise data quality is measured continuously through completeness, freshness, anomaly detection, and trend analysis.
4. Standardized Definitions and Policies
Governance ensures consistent business definitions, shared metrics, and common standards across analytics and AI workloads.
5. Closed-Loop Feedback
When quality issues arise, governance provides visibility into impact, while quality workflows enable remediation and prevention.
We help enterprises build governance-by-design foundations, know more about our data services here.
Also explore 12 Proven RAG Optimization Techniques for Production AI Systems
Building a Scalable Enterprise Data Quality Operating Model
Microsoft Fabric provides a modern data platform where data quality is engineered into workflows, not bolted on afterward. The platform’s architecture inherently supports quality through:
- Centralized storage
- Consistent metadata
- Multi-experience workloads
- Strong governance primitives
Here’s how Fabric transforms data quality into a repeatable, scalable discipline.
1. Quality at Ingestion: Schema & Format Enforcement
During ingestion into Lakehouse and Warehouse workloads, Fabric enforces:
- Schema validation
- Data type consistency
- Mandatory field checks
- Null value restrictions
- Range and domain validation
Teams can define rules that automatically reject, redirect, or repair bad records.
Example:
If a customer record arrives without a valid ID, the pipeline can:
- Route it to a quarantine folder
- Trigger automated alerts
- Add metadata tags
- Generate anomaly logs
This shifts quality enforcement closer to the source.
2. Transformations with Embedded Quality Logic
Using Spark notebooks or SQL pipelines, organizations can implement:
- Referential integrity checks
- Duplicate detection
- Outlier detection
- Timeliness and freshness checks
- Conformance to business rules
- Standardization workflows (names, formats, codes)
Because Fabric supports Delta Lake, transformations are transactional, auditable, and reversible, ensuring reliability during quality remediation.
3. Operational Monitoring of Quality Metrics
Teams can track:
- % records passing quality rules
- Data drift
- Freshness SLA adherence
- Outlier volumes
- Data completeness
These metrics can feed dashboards, alerts, or automated remediations.
4. Multi-zone Lakehouse Enforcement
Fabric supports layered architectures bronze, silver, gold — ensuring data quality progressively improves:
- Bronze: Raw, unvalidated
- Silver: Cleaned & standardized
- Gold: Business-ready, certified
Each layer reinforces quality standards.
5. Integrated AI for Quality Automation
Fabric integrates with Azure ML, enabling:
- ML-based anomaly detection
- Pattern identification
- Quality scoring models
These capabilities help organizations detect subtle issues that rule-based checks miss.
Read more about Microsoft Fabric architecture, evaluate its advantages, compare it with traditional systems to leverage it to the fullest.
How Enterprise Data Quality and Governance Enable AI Readiness
AI systems amplify data problems. Small quality issues that once caused minor reporting errors can lead to biased models, incorrect predictions, or automated failures.
Strong enterprise data quality and governance enable AI by ensuring:
- Traceable and explainable training data
- Version-controlled, certified datasets
- Clear lineage from source to model
- Controlled access to sensitive attributes
- Compliance-ready AI pipelines
Without these foundations, AI initiatives become high-risk experiments rather than scalable capabilities.
How Enterprise Data Quality And Governance Is Enforced Across Ingestion, Transformation, and Analytics
Microsoft Fabric includes multiple workloads that embed data quality capabilities directly into operational pipelines. These native tools reduce reliance on third-party platforms and provide a unified experience.
Below is a deep dive into Fabric workloads most critical to Microsoft Fabric data quality.
1. Lakehouse & Warehouse Workloads: The Execution Layer of Quality
Lakehouse and Warehouse workloads provide built-in mechanisms to enforce quality during ingestion and transformation:
Key capabilities:
- Schema enforcement at write
- Constraint validation
- SQL-based rules for missing, null, or out-of-range values
- Referential integrity management
- Merge and deduplication logic for record survivorship
- Delta Lake ACID guarantees for safe updates
This ensures quality accompanies the data throughout its lifecycle.
2. Dataflows Gen2: Operational Profiling and Low-Code Quality
Dataflows Gen2 is critical for analysts, citizen developers, and teams building operational data ingestion flows.
It enables:
- Column-level profiling
- Distribution analysis
- Null percentage measurement
- Cardinality and uniqueness checks
- Value frequency detection
- Pattern and outlier detection
This profiling is immediate and operational, offering feedback before data is persisted into analytical stores.
3. Fabric Notebooks & Data Wrangler: Exploratory Quality
Exploratory data quality is essential during early phases of pipeline development.
Data Wrangler provides:
- Guided data cleansing
- Interactive profiling
- Schema recommendations
- Auto-generated transformation code
- Visual anomaly detection
- Spark-backed execution for scalability
This bridges exploratory quality with production pipelines.
4. Pipelines in Data Factory: Integrated Quality Checks
Fabric’s integrated Data Factory supports:
- Quality validation as pipeline steps
- Conditional routing based on quality outcomes
- Alerts and notifications on quality failures
- Orchestration of remediation workflows
Teams can build sophisticated rule sets and automate quality governance.
5. Lakehouse Medallion Architecture as a Quality Framework
The Bronze → Silver → Gold model provides a structured, scalable pathway for improving data quality:
- Bronze: Capture raw data with basic validations
- Silver: Ensure conformance, remove duplicates, enforce business rules
- Gold: Transform into certified, governed datasets
This model accelerates trust-building and reduces rework.
Learn how Microsoft differs from other platforms, read Microsoft Fabric vs Power BI: A Strategic, Future-Ready Analytics Comparison
How Governance Enables Trust, Compliance, and Accountability
Even the most sophisticated Microsoft Fabric data quality workflows are incomplete without an enterprise-wide governance layer. Fabric ensures data is clean, validated, and fit for use, but only Microsoft Purview ensures that:
- The right people consume the right data
- The data is used correctly
- The data is traceable, classifiable, and compliant
- There is clear ownership and accountability
Gartner emphasizes that data quality cannot exist in isolation; it must be tied to governance practices that offer transparency, lineage, and policy control across all enterprise systems. This is precisely where Purview excels.
Learn how Techment helps organizations build conversational and generative AI capabilities through our Conversational AI offerings.
1. Centralized Metadata & Business Glossary
Purview serves as the intelligent catalog for all Fabric assets — datasets, tables, files, dashboards, pipelines. With automated scanning and discovery:
- Business users understand data meaning
- Engineers inherit standardized definitions
- AI developers rely on governed data for modeling
- Executives trust dashboards backed by verifiable data sources
For organizations struggling with inconsistent definitions, Purview becomes the source of truth for terminology.
2. Automated Data Lineage for Trust & Compliance
Lineage is no longer a convenience — it is a regulatory requirement.
Purview automatically tracks:
- Source-to-target mappings
- Pipeline transformations
- AI feature engineering steps
- Power BI lineage and report dependencies
When a quality issue arises in Fabric, Purview shows:
- Where it originated
- Where the corrupted data flows
- Who is accountable
- Which reports, KPIs, or models are impacted
This closes the loop between execution (Fabric) and oversight (Purview).
3. Sensitivity Labels, Access Controls & Compliance Policies
Purview integrates with Microsoft Entra (Azure AD), enabling:
- Row/column-level security
- Role-based access control (RBAC)
- Attribute-based access control (ABAC)
- Sensitivity labeling (Confidential, PII, Financial, etc.)
- DLP classification policies
- GDPR, HIPAA, SOC2 alignment
With Purview, organizations can enforce policy-driven governance, ensuring that even high-quality data is accessed safely and ethically.
4. Regulatory & Audit Readiness
Purview’s governance capabilities support audit trails required by regulators across BFSI, Healthcare, Manufacturing, and Logistics.
Audit-ready enterprises can:
- Provide lineage reports instantly
- Identify how data supports KPIs
- Track transformations for ML features
- Prove adherence to retention & deletion policies
This makes Purview indispensable for organizations adopting AI and analytics at scale.
Lay the groundwork for AI readiness, identify ROI-positive use cases, and build a prioritized execution roadmap designed for value, feasibility, and governance with our AI strategy and road mapping services.
Closing the Loop Between Data Pipelines and Governance
The most successful enterprises today are not those with the largest datasets — but those with the highest confidence in their datasets. Combining Microsoft Fabric data quality with Purview governance creates a unified operating model that transforms raw data into governed, trustworthy intelligence.
This combined architecture introduces a dual operating system for enterprise data:
- Fabric = Execution quality (profiling, validation, transformation, remediation)
- Purview = Governance quality (ownership, lineage, compliance, control)
Here is what this operating model looks like in practice.
1. Quality by Design, Not by Exception
Rules are no longer applied as downstream patches.
Quality is embedded:
- At ingestion (schema validation)
- During transformation (business rules, dedupe, conformance)
- Across zones (Bronze → Silver → Gold)
- Before consumption (profiling, certification)
Fabric enforces quality upstream so the enterprise does not suffer downstream.
2. Governed Quality, Not Unsupervised Pipelines
Purview assigns ownership:
- Data Owners
- Data Stewards
- Data Custodians
- Data Consumers
This ensures all quality issues link back to accountable roles — a crucial requirement in any regulated organization.
3. Consistent Policies & Standards
Purview ensures that:
- Quality rules are standardized
- Sensitivity labels travel across systems
- Data products adhere to organizational policies
- Semantic definitions remain consistent across Fabric workloads
This eliminates the biggest barrier to scaling AI: inconsistent data semantics.
4. Closed-Loop Feedback Between Pipelines & Governance
When quality checks fail:
- Fabric triggers alerts
- Purview shows the impact on downstream assets
- Stewards validate and resolve discrepancies
- Policies update automatically for future protection
This creates a continuous improvement loop, something analysts at Gartner call critical for “data-driven operational resilience.”
Learn how we modernize your technology stack, integrate AI into enterprise systems, and migrate legacy applications to AI-enabled architectures with our AI-modernization services.
Why AI and Analytics Fail Without Quality Foundations
AI has transformed the expectations placed on enterprise data. In traditional analytics, bad data might lead to incorrect dashboards. In AI systems, bad data leads to:
- Biased predictions
- Regulatory violations
- Broken automations
- Incorrect recommendations
- Failed customer experiences
This is why Microsoft Fabric data quality must evolve beyond traditional rules into AI-grade data preparation.
1. AI Requires Explainable, Traceable Data
LLMs and predictive models demand:
- Clear lineage (Purview)
- Standardized features
- Quality metrics
- Version-controlled datasets
- Certified data products
Fabric + Purview provides this transparency.
2. ML Pipelines Amplify Bad Data
Data issues such as:
- Skewed distributions
- Extreme outliers
- Missing values
- Incorrect labels
- Data drift
- Leakage
…can degrade models rapidly.
Fabric workloads — especially Data Wrangler, Notebooks, and Delta Lake — allow teams to detect and remediate these issues early.
3. Real-Time AI Demands Real-Time Quality
With enterprise AI becoming real-time (fraud detection, dynamic pricing, IoT anomaly detection), quality can no longer be assessed hours or days later.
Fabric’s real-time ingestion combined with Data Activator allows:
- Continuous validation
- Real-time alerts
- Automated remediation
- Proactive drift detection
4. AI Governance is Impossible Without Purview
Purview ensures:
- Responsible AI use
- Sensitivity protection
- Retention policies
- Compliance-aware ML pipelines
- Clear accountability
AI without governance is a liability.
AI with Fabric + Purview becomes a competitive edge.
Enhance your analytics outcomes and turn fragmented data with our data engineering solutions and MS Fabric capabilities.
Measuring the ROI of Enterprise Data Quality and Governance
Implementing Microsoft Fabric data quality and Purview governance requires more than tools — it requires a unified strategy, expert-led architecture, and a partner who understands the intersection of data engineering, governance, and AI.
Techment is uniquely positioned to lead this transformation.
Techment: Microsoft Partner & Enterprise AI Enablement Specialist
As a certified Microsoft Partner, Techment helps enterprises modernize data estates, operationalize AI, and build future-ready analytics platforms. We bring a full-stack Microsoft capability, covering:
- Microsoft Fabric
- Azure Synapse
- Azure ML
- Azure OpenAI
- Power Platform
- Purview governance
- Microsoft 365 & Copilot integrations
This enables organizations to unify data, democratize AI, and strengthen governance across hybrid and multi-cloud environments.
1. End-to-End Modernization with Fabric and Azure
Techment architected solutions that unify data from:
- Legacy systems
- ERPs & CRMs
- IoT & telemetry systems
- Data lakes & warehouses
- Third-party SaaS data
Our solutions focus on:
- Hybrid ingestion & pipeline orchestration
- Lakehouse architectures following medallion patterns
- Real-time analytics capabilities
- Semantic modeling and Direct Lake optimization
2. Enterprise-Grade Governance with Purview
Techment deploys governance frameworks using:
- Automated lineage
- Sensitivity labeling
- Policy enforcement
- Access controls
- Business glossaries
- Data product governance
We embed governance as-code into CI/CD pipelines to prevent policy drift.
3. AI-Ready Data Quality Frameworks
Techment equips enterprises with:
- Feature quality monitoring
- ML-ready datasets
- Drift detection workflows
- Automated quality scoring
- AI compliance and risk mitigation
This ensures AI systems are trained on reliable, ethical, compliant data.
4. Accelerators & Methodologies
Techment brings reusable accelerators for:
- Fabric migration
- Purview onboarding
- Quality rule templates
- Data product certification
- AI data readiness assessments
These accelerators reduce implementation time by 30–50%.
5. Proven 4-Stage Implementation Blueprint
Step 1 — Vision & Discovery
Assess data landscape, governance maturity, AI opportunities.
Step 2 — Roadmap & Strategy
Design Fabric + Purview architecture, governance models, and data quality rules.
Step 3 — Implementation & Adoption
Deploy lakehouses, pipelines, governance catalogs, quality frameworks, and ML-ready datasets.
Step 4 — Run, Optimize & Scale
Monitor governance KPIs, optimize costs, improve quality workflows, scale across business domains.
Explore the emergence of new AI-driven roles, platforms, and ecosystem players in our latest whitepaper.
Common Enterprise Data Quality Pitfalls (and How to Avoid Them)
- Treating data quality as a downstream cleanup task
Many enterprises rely on reports or dashboards to “fix” data issues after they surface. This leads to repeated rework and unreliable insights.
Avoid it by embedding quality checks at ingestion and transformation stages so issues are detected before data is consumed. - Confusing data quality with data governance
Organizations often assume governance tools automatically ensure clean data. In reality, governance provides oversight, not validation.
Avoid it by implementing operational data quality rules in pipelines while using governance to manage ownership, lineage, and compliance. - Relying on manual or ad hoc quality checks
Spreadsheet audits and one-off scripts do not scale and quickly break as data volumes and velocity increase.
Avoid it by automating quality validation, monitoring completeness, freshness, and anomalies as part of standard data workflows. - Ignoring data quality until AI or analytics fail
Poor data may produce tolerable dashboards but catastrophic AI outcomes, including biased models and incorrect predictions.
Avoid it by treating data quality as an AI-readiness requirement, not a troubleshooting step. - Lacking clear ownership and accountability for data assets
When no one owns data quality, issues persist without resolution.
Avoid it by assigning explicit data owners and stewards and linking quality failures to accountable roles.
Conclusion: Enterprise Data Quality and Governance as a Competitive Advantage
Enterprise data quality and governance are no longer optional — they are the foundation of trustworthy analytics, scalable AI, and regulatory confidence. Organizations that invest early in embedding quality into pipelines and aligning governance with accountability gain a durable competitive edge.
In the coming years, enterprises will not compete on how much data they have, but on how reliable, governed, and usable that data is at scale.
Enterprises cannot scale AI, analytics, or automation without strong foundations in Microsoft Fabric data quality and Purview-driven governance. Fabric ensures data is validated, profiled, transformed, and monitored. Purview ensures data is governed, classified, compliant, and trustworthy.
Together, they create a resilient, transparent, and AI-ready data ecosystem.
Future-ready organizations use Fabric + Purview to:
- Build governed data products
- Accelerate AI model deployment
- Improve analytics reliability
- Reduce compliance risk
- Enable real-time intelligence
- Democratize data safely
In the next decade, businesses will not compete on data volume — they will compete on data trustworthiness and governance maturity. Those who invest now will lead the AI-first revolution.
Learn how Techment utilizes advanced technologies to modernize legacy systems and deliver a future-ready, scalable platform in our latest case study.
FAQs: Ensuring Enterprise Data Quality and Governance
1.What is the difference between data quality and data governance?
Data quality focuses on whether data is accurate, complete, consistent, and fit for use in analytics and AI. Data governance focuses on how data is managed — including ownership, access control, lineage, policies, and compliance. Enterprises need both: data quality ensures data is usable, while data governance ensures data is trusted, accountable, and compliant.
2. How does data quality affect AI and machine learning outcomes?
AI and machine learning systems directly reflect the quality of the data they are trained on. Poor data quality leads to biased models, inaccurate predictions, unstable performance, and regulatory risk. High-quality, well-governed data improves model accuracy, explainability, and reliability, making AI systems safer and more effective at scale.
3. Why do enterprises need a data quality operating model?
Enterprises need a data quality operating model to move beyond manual fixes and isolated checks. An operating model embeds quality rules into data pipelines, assigns clear ownership, enables continuous monitoring, and creates repeatable processes that scale across domains. Without this model, data quality efforts remain reactive and unsustainable.
4. How can organizations measure ROI from data quality initiatives?
Organizations can measure ROI from data quality initiatives by tracking improvements in decision accuracy, reduced rework, faster analytics delivery, improved AI performance, lower compliance risk, and higher customer experience outcomes. These benefits translate into cost savings, revenue protection, and more reliable business decisions.
5. Can data governance exist without data quality?
Data governance can exist without data quality, but it provides limited value on its own. Governance defines rules, ownership, and controls, but it does not correct inaccurate or incomplete data. Without strong data quality, governed data may still produce unreliable analytics and AI outcomes. Effective enterprises integrate governance and quality as a single operating discipline.
Related Reads
- Data Governance for Data Quality: Future-Proofing Enterprise Data
- Microsoft Fabric Architecture: A CTO’s Guide to Modern Analytics and AI
- Microsoft Fabric vs Power BI: Understanding the Difference
- Microsoft Fabric vs Snowflake: Data Management Showdown
- AI-Ready Enterprise Checklist for Microsoft Fabric




