
Building RAG (Retrieval-Augmented Generation) applications addresses these limitations by combining LLMs with trusted enterprise data. Instead of relying solely on a model’s pre-trained knowledge, RAG retrieves relevant information from approved sources before generating a response. This improves accuracy, reduces hallucinations, and enables AI systems to deliver grounded, context-aware answers.
Introduction
Large Language Models (LLMs) have transformed how enterprises build AI-powered applications. However, they aren’t designed to deliver accurate, organization-specific answers on their own. They can hallucinate, rely on outdated training data, and lack access to proprietary business knowledge.
While the concept is straightforward, deploying RAG successfully in an enterprise environment is not. Production-ready RAG applications require more than a vector database and an LLM—they demand a strong data foundation, intelligent retrieval, effective prompt engineering, governance, continuous evaluation, and scalable architecture.
This guide outlines 10 effective steps to building RAG applications that are secure, scalable, and enterprise-ready. Whether you’re developing AI copilots, modernizing knowledge management, or enabling domain-specific search, these best practices will help you move confidently from prototype to production.
Strengthen your foundation with our offerings as AI strategy and road-mapping.
TL;DR – Executive Summary
- Building RAG applications for enterprises requires far more than connecting a vector database to an LLM.
- Production-ready RAG systems demand architecture, governance, hybrid retrieval, evaluation frameworks, and MLOps discipline.
- The biggest failures in RAG implementation stem from unclear problem definition, weak retrieval quality, and lack of monitoring.
- Enterprise RAG architecture must address security, cost control, latency, and regulatory compliance.
- Data leaders who treat RAG as infrastructure—not experimentation—unlock durable AI advantage.
Executive Framework: 10 Effective Steps to Building RAG Applications

Step 1: Define the Enterprise Problem Before Choosing the Technology
Every successful RAG implementation starts with a well-defined business problem—not a technology stack.
Before selecting an LLM, vector database, or retrieval framework, identify the business outcome you want to improve. The more clearly the use case is defined, the easier it becomes to design a RAG application that delivers measurable value.
Ask these questions before building your solution:
- Who are the primary users?
- What decisions or tasks are they trying to complete?
- Which enterprise knowledge sources are required?
- What level of accuracy is acceptable?
- What are the business risks of an incorrect response?
Enterprise Insight: RAG is not a generic chatbot solution. It’s a knowledge retrieval system designed to support high-value business decisions.
Common Enterprise RAG Use Cases
Different use cases demand different retrieval strategies and accuracy levels.
| Use Case | Priority |
|---|---|
| Internal knowledge search | Fast and accurate information retrieval |
| Technical documentation assistant | Context-aware support for engineering teams |
| Legal contract analysis | High precision with source citations |
| Regulatory compliance | Explainable and auditable responses |
| Customer support copilots | Consistent, grounded responses from approved knowledge |
For example, an HR assistant may tolerate some ambiguity, while a compliance or legal application requires near-perfect retrieval accuracy and traceability.
Key Takeaway: Clearly defining the problem, users, and success metrics prevents unnecessary complexity and ensures your RAG application solves a real business need
Step 2: Build a Trusted Data Foundation
The quality of a RAG application’s responses depends on the quality of the data it retrieves.
Before focusing on prompts or model selection, ensure your enterprise data is accurate, current, and governed. Poor-quality data leads to poor retrieval, regardless of the sophistication of the underlying LLM.
Evaluate your knowledge sources based on:
- Data quality and consistency
- Source reliability
- Update frequency
- Metadata availability
- Version control
- Access permissions and governance
A well-designed ingestion pipeline should support documents, PDFs, structured databases, knowledge bases, emails, and other enterprise content while preserving metadata and security controls.
Optimize Document Processing
Effective document preparation improves retrieval accuracy and response quality.
Best practices include:
- Extract text accurately using OCR where required.
- Split documents into meaningful semantic chunks.
- Preserve metadata such as author, source, and publication date.
- Maintain document version history.
- Enforce role-based access controls throughout the indexing process.
Why Chunking Matters
Chunking is one of the most important factors affecting retrieval performance.
Large chunks often introduce irrelevant information and increase token costs, while very small chunks lose important context and reduce semantic understanding.
Instead of using a fixed token size, structure chunks around natural document boundaries such as sections, headings, or topics to improve retrieval precision.
Best Practice: Optimize chunk size based on document structure and user intent—not arbitrary token limits.
Key Takeaway: A trusted, well-governed data foundation is the backbone of every successful enterprise RAG application.
Step 3: Choose the Right Retrieval Strategy
Retrieval quality has the greatest influence on answer quality. Even the most advanced LLM cannot generate accurate responses if the wrong information is retrieved.
Enterprise RAG applications typically use one of three retrieval approaches.
Dense Vector Retrieval
Uses embeddings to identify semantically similar content.
Strengths
- Understands meaning and context
- Excellent for natural language queries
- Handles synonyms and paraphrased questions well
Limitations
- May miss exact keywords or regulatory terminology
Sparse Retrieval (BM25)
Ranks documents using keyword relevance.
Strengths
- Excellent for exact-match searches
- Performs well with structured documents and compliance content
Limitations
- Limited semantic understanding
Hybrid Retrieval (Recommended for Enterprise)
Hybrid retrieval combines dense vector search with BM25 and, where appropriate, a reranking model.
This approach delivers more accurate and reliable results by balancing semantic understanding with precise keyword matching.
| Retrieval Strategy | Best For |
| Dense Search | Conversational knowledge discovery |
| Sparse Search (BM25) | Exact keyword and regulatory searches |
| Hybrid Retrieval | Enterprise production environments |
Why Hybrid Retrieval Performs Better?
Enterprise knowledge repositories contain both structured and unstructured information. Hybrid retrieval reduces common retrieval failures by:
- Improving recall for complex queries
- Capturing both semantic intent and exact terminology
- Reducing irrelevant results
- Increasing citation accuracy
- Delivering more consistent responses across diverse content
A production-ready retrieval layer typically includes:
- Vector database
- BM25 or inverted index
- Cross-encoder reranking
- Metadata filtering
- Access-aware retrieval
Enterprise Recommendation: Hybrid retrieval is the preferred architecture for production RAG applications because it provides the accuracy, resilience, and scalability required for enterprise workloads.
Key Takeaway: Strong retrieval architecture is the foundation of trustworthy RAG. Investing in hybrid retrieval and intelligent ranking consistently produces better outcomes than relying on embeddings alone.
For enterprises exploring early-stage AI assistants, this approach is often aligned with modernization efforts such as those described in Techment’s Best Practices for Generative AI Implementation in Business.
Hybrid Retrieval vs. Dense Vector Search: Which Is Better for Enterprise RAG?
| Capability | Dense Vector Search | Hybrid Retrieval (Dense + BM25) |
|---|---|---|
| How it works | Retrieves documents based on semantic similarity using vector embeddings. | Combines semantic vector search with keyword-based retrieval (BM25) and optional reranking. |
| Best suited for | Natural language queries and conceptual search. | Enterprise knowledge bases, compliance, legal, technical documentation, and customer support. |
| Semantic understanding | Excellent | Excellent |
| Exact keyword matching | Limited | Excellent |
| Performance with domain-specific terminology | May miss acronyms, product names, or regulatory terms. | Accurately retrieves documents containing specific terminology and semantic context. |
| Retrieval accuracy | Good for general-purpose applications. | High accuracy across diverse enterprise datasets. |
| Hallucination risk | Higher if relevant documents are not retrieved. | Lower because retrieval combines multiple search techniques. |
| Scalability | Scales well for semantic search workloads. | Scales well with additional indexing and reranking layers. |
| Implementation complexity | Moderate | Higher, but better suited for production environments. |
| Recommended for enterprise AI | Suitable for prototypes and smaller knowledge bases. | Recommended for production-grade enterprise RAG applications. |
Key Takeaway: Dense vector search excels at understanding semantic meaning, while hybrid retrieval combines semantic understanding with precise keyword matching. For enterprise RAG applications, hybrid retrieval delivers more reliable, accurate, and explainable results across complex and regulated knowledge repositories
Step 4: Engineer Context and Prompts for Accurate Responses
Retrieving the right information is only half the equation. The way that information is structured and presented to the LLM has a direct impact on response quality.
Effective context engineering ensures the model uses relevant information, ignores noise, and produces grounded responses.
Best Practices for Context Engineering
Rather than passing all retrieved content to the model, optimize the context by:
- Ranking documents by relevance.
- Removing duplicate or irrelevant content.
- Including document metadata, such as source and publication date.
- Prioritizing the most recent or authoritative documents.
- Providing clear system instructions and response boundaries.
For example:
Use only the information provided in the retrieved documents. If sufficient information is unavailable, state that you cannot answer rather than making assumptions.
This simple instruction significantly reduces hallucinations and improves trust.
Prompt Engineering Best Practices
Enterprise prompts should define:
- The assistant’s role
- Response format
- Citation requirements
- Reasoning constraints
- Escalation behaviour for insufficient information
Well-designed prompts improve consistency without increasing model complexity.
Enterprise Recommendation: Treat prompt engineering as part of your application architecture—not a one-time prompt-writing exercise.
Key Takeaway: High-quality retrieval combined with structured context and disciplined prompting produces more accurate, explainable, and trustworthy AI responses.
Step 5: Measure Performance with Continuous Evaluation
Enterprise RAG applications should be evaluated continuously, not only during development.
Without measurable evaluation, retrieval quality degrades over time as business data, user behaviour, and knowledge sources evolve.
Core Evaluation Metrics
Monitor both retrieval performance and response quality.
| Metric | Why It Matters |
|---|---|
| Retrieval Recall (Recall@k) | Measures whether relevant documents are retrieved |
| Answer Faithfulness | Verifies responses are grounded in retrieved content |
| Answer Relevance | Evaluates whether responses address user intent |
| Citation Accuracy | Confirms responses reference the correct sources |
| Latency | Tracks user experience and operational performance |
| Cost per Query | Measures infrastructure efficiency |
These metrics provide a balanced view of quality, performance, and operational cost.
Build an Enterprise Evaluation Framework
Combine automated testing with expert review to identify issues before they affect users.
Recommended practices include:
- Synthetic question generation
- Benchmark datasets
- Human-in-the-loop validation
- Regression testing
- A/B testing for retrieval and prompt changes
Evaluation should become part of the deployment pipeline, enabling continuous improvement rather than reactive troubleshooting.
Best Practice: Measure retrieval quality first. Even the most capable LLM cannot compensate for poor document retrieval.
Key Takeaway: Continuous evaluation ensures your RAG application remains accurate, reliable, and aligned with evolving enterprise knowledge.
Step 6: Design for Scalability, Performance, and Cost
Many RAG prototypes perform well during testing but struggle in production due to increased data volumes, user traffic, and infrastructure costs.
Enterprise RAG systems should be designed to scale efficiently while maintaining consistent response quality.
Key Architecture Considerations
Plan for:
- Horizontal scalability
- Intelligent caching
- Efficient embedding management
- Query batching
- Context window optimization
- High availability and resilience
Performance expectations vary by use case.
| Application | Typical Response Time |
|---|---|
| Internal knowledge search | Under 3 seconds |
| Customer-facing assistants | Under 1 second |
| Mission-critical workflows | Near real-time, where possible |
Control Operational Costs
As usage grows, infrastructure costs can increase rapidly.
Common cost drivers include:
- Embedding generation
- Vector storage
- LLM inference
- Reranking models
- Token consumption
Strategies to optimize costs include:
- Using smaller domain-specific models where appropriate.
- Limiting retrieved context to the most relevant documents.
- Implementing tiered retrieval pipelines.
- Caching frequently accessed queries.
- Optimizing embedding refresh schedules.
Balancing performance with cost ensures long-term sustainability.
Enterprise Recommendation: Treat RAG as an operational platform with measurable service levels—not simply an AI application.
Key Takeaway: Scalable architecture balances accuracy, latency, resilience, and cost, enabling enterprise RAG systems to deliver consistent value as adoption grows.
Techment’s RAG Models – 2026 Blog emphasizes continuous optimization for enterprise AI ecosystems .
Enterprises building AI under compliance mandates should align retrieval pipelines with broader governance initiatives such as those described in Data Governance for Data Quality.
Step 7: Build Governance, Security, and Compliance into Your RAG Architecture
Enterprise RAG applications often retrieve and process sensitive business information. Without robust governance, they can expose confidential data, violate regulatory requirements, and erode user trust.
Security and compliance should be embedded into the architecture from the outset—not added after deployment.
Governance Best Practices
A production-ready RAG system should include:
- Role-based access control (RBAC)
- Metadata-driven access policies
- Encryption for data at rest and in transit
- Audit logging and traceability
- Data masking for sensitive information
- Compliance with industry and regulatory standards
Secure Retrieval Matters
Retrieval should respect existing enterprise permissions.
Before retrieving documents, the system should verify that users are authorized to access the requested information. Integrating identity management with metadata filtering ensures users only receive content they are permitted to view.
Enterprise Recommendation: Apply the same governance controls to AI retrieval that you use for enterprise data platforms. Security should extend across ingestion, indexing, retrieval, and response generation.
Key Takeaway: Trustworthy RAG applications combine accurate retrieval with strong governance, security, and compliance
Step 8: Keep Humans in the Loop
Enterprise AI should augment human expertise—not replace it.
Human oversight improves response quality, increases user trust, and creates continuous feedback loops that strengthen system performance over time.
Human-in-the-Loop Best Practices
Include mechanisms such as:
- Confidence scores for AI-generated responses
- User feedback (thumbs up/down)
- Expert review workflows
- Escalation paths for low-confidence responses
- Continuous retraining based on validated feedback
These capabilities help identify retrieval gaps, improve prompt design, and refine knowledge sources.
Best Practice: Treat user feedback as operational data. Every interaction provides an opportunity to improve retrieval quality and response accuracy.
Key Takeaway: Human expertise remains essential for validating high-impact decisions and continuously improving enterprise RAG systems.
Step 9: Operationalize RAG with MLOps
Enterprise knowledge changes continuously. Documents are updated, policies evolve, and new information is created every day.
Without ongoing monitoring and maintenance, RAG performance will gradually decline.
Build Continuous Improvement into Your Operations
An enterprise MLOps strategy should include:
- Automated document ingestion and re-indexing
- Scheduled embedding refreshes
- Retrieval quality monitoring
- Drift detection
- Performance dashboards
- Cost and latency monitoring
- Version control for prompts and retrieval pipelines
Operational metrics should be reviewed regularly to identify issues before they impact users.
Monitor the Right Metrics
Track indicators such as:
| Metric | Why It Matters |
|---|---|
| Retrieval success rate | Measures search effectiveness |
| Answer accuracy | Validates response quality |
| User satisfaction | Reflects business value |
| Latency | Ensures a consistent user experience |
| Cost per query | Supports efficient scaling |
Enterprise Recommendation: Treat RAG as a continuously evolving AI platform rather than a one-time implementation project.
Key Takeaway: Continuous monitoring and optimization keep enterprise RAG systems accurate, efficient, and aligned with changing business knowledge.
Step 10: Plan for Enterprise Adoption
The success of a RAG initiative depends on user adoption as much as technical implementation.
Even the most advanced AI solution delivers limited value if employees don’t understand when—or how—to use it.
Drive Successful Adoption
A structured rollout should include:
- User training and onboarding
- Clear usage policies
- Defined governance and ownership
- Communication of AI capabilities and limitations
- Adoption tracking and user feedback
Measure success using business outcomes, not just technical metrics.
Examples include:
- Reduced search time
- Faster decision-making
- Improved employee productivity
- Higher knowledge reuse
- Increased user satisfaction
Enterprise Recommendation: Position RAG as a productivity enabler that complements existing workflows rather than replacing them.
Key Takeaway: Change management, governance, and continuous education are essential for maximizing enterprise AI adoption
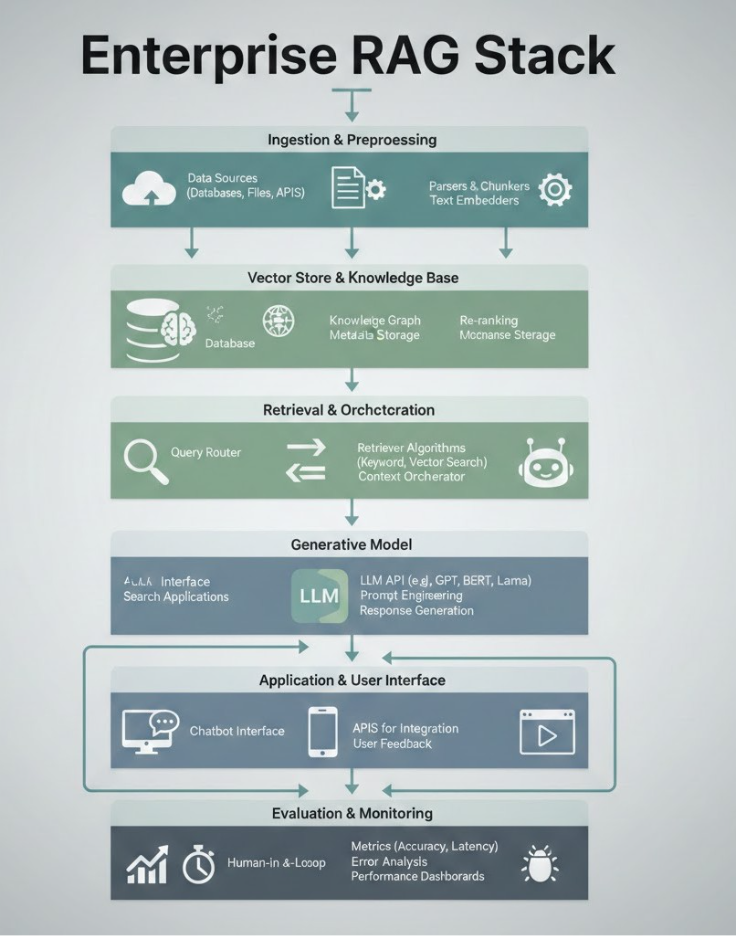
Enterprise RAG Architecture Blueprint
A production-ready RAG architecture typically includes the following layers:
- Data ingestion and preparation
- Storage and indexing
- Hybrid retrieval
- Reranking and filtering
- LLM orchestration
- Response generation with citations
- Evaluation and observability
- Governance and security
This layered architecture improves scalability, accuracy, explainability, and operational resilience.
Common Challenges in Building RAG Applications
Enterprise teams frequently encounter similar implementation challenges.
| Challenge | Recommended Mitigation |
|---|---|
| Poor retrieval quality | Hybrid search and reranking |
| Context overload | Semantic chunking and context optimization |
| Hallucinated responses | Grounded prompting and citation-based generation |
| High latency | Caching, optimized indexing, and efficient inference |
| Rising operational costs | Context optimization and cost monitoring |
| Security and compliance risks | RBAC, metadata filtering, and audit logging |
Recognizing these risks early enables organizations to build more resilient and trustworthy RAG systems.
Why Building RAG Applications Creates Long-Term Business Value
For enterprises, RAG is more than a conversational AI capability. It provides a scalable foundation for trusted, knowledge-driven decision-making.
Organizations that implement enterprise-grade RAG can:
- Break down knowledge silos
- Improve employee productivity
- Accelerate decision-making
- Increase confidence in AI-generated responses
- Strengthen regulatory compliance
- Scale AI initiatives across business functions
As enterprise knowledge continues to grow, retrieval-grounded AI will become a core capability for delivering accurate, explainable, and context-aware intelligence.
Build Production-Ready RAG Applications with Techment
Building enterprise-grade RAG applications requires more than integrating an LLM with a vector database. Success depends on trusted data, intelligent retrieval, scalable architecture, governance, and continuous optimization.
Techment helps organizations design, build, and scale production-ready RAG solutions through:
- Enterprise AI strategy and roadmap development
- Data platform modernization
- Retrieval-Augmented Generation (RAG) architecture and implementation
- Hybrid retrieval optimization
- AI governance and security frameworks
- MLOps and continuous performance monitoring
- Cloud-native deployment and scalability
Whether you’re exploring your first RAG use case or scaling AI across the enterprise, our experts can help you build secure, explainable, and high-performing AI solutions that deliver measurable business value.
Conclusion
Building RAG applications is about designing reliable knowledge systems—not simply integrating an LLM with a vector database.
Successful enterprise implementations combine trusted data, intelligent retrieval, context engineering, governance, continuous evaluation, and operational excellence into a unified architecture.
By following these ten steps, organizations can move beyond proof-of-concept deployments and build secure, scalable, and production-ready RAG applications that deliver measurable business value.
The future of enterprise AI belongs to systems that are retrieval-grounded, governed, explainable, and continuously optimized.
Ready to accelerate your enterprise AI journey? Connect with Techment to design and deploy production-ready RAG applications tailored to your business goals.
FAQs
1. What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an AI architecture that combines a Large Language Model (LLM) with an external knowledge source. Instead of relying only on pre-trained knowledge, the model retrieves relevant enterprise documents before generating a response, improving accuracy, transparency, and contextual relevance.
2. What is the biggest mistake when building RAG applications?
The most common mistake is starting with the technology instead of the business problem. Successful RAG implementations begin with a clearly defined use case, trusted data sources, measurable success criteria, and governance requirements before selecting models or retrieval frameworks.
3. Why is hybrid retrieval recommended for enterprise RAG?
Hybrid retrieval combines semantic vector search with keyword-based search (BM25), delivering better recall and precision than either approach alone. This helps enterprise applications retrieve the right information consistently, especially across large and diverse knowledge repositories.
4. How do you measure the performance of a RAG application?
Enterprise RAG systems should be evaluated using retrieval quality, answer faithfulness, citation accuracy, latency, user satisfaction, and cost per query. Continuous evaluation ensures the application remains accurate and reliable as enterprise knowledge evolves.
5. Can RAG eliminate AI hallucinations?
No. RAG significantly reduces hallucinations by grounding responses in trusted enterprise data, but it cannot eliminate them completely. Combining high-quality retrieval, prompt engineering, governance, and continuous evaluation provides the best results.
6. How long does it take to build a production-ready RAG application?
Implementation timelines vary based on data maturity, governance requirements, and system complexity. Most enterprise RAG initiatives take three to nine months, including data preparation, retrieval optimization, security implementation, testing, and deployment.
7. What are the essential components of an enterprise RAG architecture?
A production-ready RAG architecture typically includes:
Enterprise data ingestion
Document processing and chunking
Hybrid retrieval
Vector database
Reranking layer
Large Language Model (LLM)
Evaluation and observability
Governance and security controls
Together, these components enable accurate, scalable, and secure AI applications.




