Data has become the lifeblood of the modern enterprise — but it’s trapped in complexity. Most organizations today face data engineering as their “breaking-point infrastructure”. As data volumes surge 10× every two years (IDC), teams struggle to maintain quality, trust, and speed across decentralized environments.
AI-powered data engineering is emerging as the next strategic frontier — where autonomous intelligence layers replace human-heavy orchestration. This transformation goes far beyond efficiency; it redefines how enterprises create value from data.
McKinsey notes that AI-native data infrastructure can cut cycle times by 50% and improve data availability by 80%, unlocking exponential returns across analytics, ML, and digital transformation initiatives.
This shift repositions the data platform as a strategic moat — not a support function. When AI models directly influence ingestion, curation, and governance, enterprises move from data-informed to data-intelligent operations.
TL;DR
- AI-powered data engineering marks a fundamental shift — not just automation but intelligence built into data pipelines.
- Legacy ETL/ELT models are breaking under the pressure of real-time, multi-modal, and AI-driven workloads.
- Enterprises embracing AI-native architectures see 10× faster time-to-insight and 70% lower operational toil.
- Learn how to build an AI-first data engineering blueprint and what leadership actions matter now.
Explore how Techment transforms enterprise analytics in How Techment Transforms Insights into Actionable Decisions Through Data Visualization?
The Legacy Data Engineering Paradigm — What’s Broken
Legacy data stacks are manual, brittle, and reactive. Most pipelines depend on static scripts, manual schema mapping, and batch transformations — all symptoms of human-centric orchestration. These approaches fail to handle real-time, multi-cloud, and compliance-heavy applications.
Research shows that nearly 62% of enterprises experience pipeline failures due to manual dependencies and lack of automated metadata intelligence.
Key Pain Points:
- Human-intensive orchestration: 45% of data engineers spend more than half their time firefighting pipeline issues.
- Unscalable for AI-driven workloads: Generative AI and large language models (LLMs) demand near-instant ingestion and contextual enrichment — impossible with static ETL.
- 53% of organizations cite anomalies as their biggest data reliability challenge.
- Hidden operational costs: Slow SLAs, frequent outages, and rework drain productivity and inflate cloud costs by up to 40%.
As enterprises deploy GenAI apps, these limitations become existential. The old paradigm simply cannot sustain AI-native operations, where data must be dynamic, contextual, and explainable.
Read how Techment drives trust in data pipelines in Data Integrity: The Backbone of Business Success
The Core of AI-Powered Data Engineering
AI-powered data engineering transforms code-centric pipelines into autonomous, self-optimizing systems. The foundation lies in embedding intelligence across every layer of the data lifecycle — from ingestion to governance.
Core Primitives:
- AI Copilots (Human-in-the-loop): Provide context-aware assistance to engineers, generating transformations, schema suggestions, and validation scripts.
- Autonomous Data Agents (Human-off-the-loop): Self-manage routine tasks — anomaly detection, lineage tracking, and retry mechanisms.
- LLM-Native Metadata Intelligence: Large language models interpret metadata semantics, enabling automated schema alignment and data catalog generation.
- Reinforcement Learning for Pipeline Optimization: Models learn from operational feedback to improve performance autonomously.
- Accenture highlights that Generative AI is enhancing coding accessibility, boosting developer productivity by nearly 30% in the first year.
- AI agents are helping with tasks like translating legacy code and reverse engineering business rules.
This shift demands a new mindset — “intelligence-layered” over traditional ETL/ELT thinking. Instead of orchestrating steps, teams now curate autonomous behaviors that continuously adapt to new data realities.
Dive deeper into intelligent automation in AI-Powered Automation: The Competitive Edge in Data Quality Management
Key Capabilities That Define Next-Gen AI Data Engineering
Next-gen AI data engineering systems exhibit adaptive intelligence — systems that sense, decide, and act with minimal human intervention.
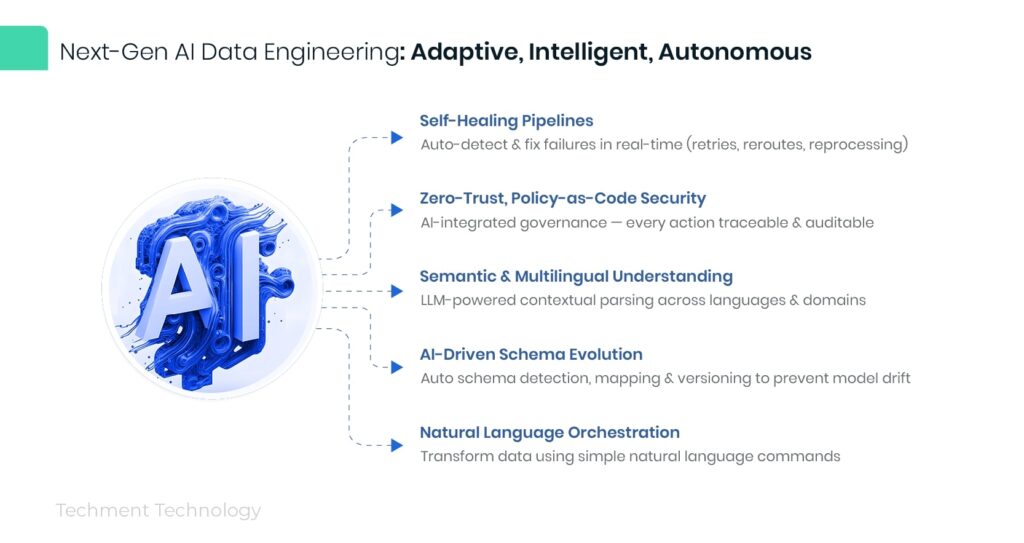
Core Capabilities Include:
- Self-Healing Pipelines: Auto-detect and resolve failures (retries, re-routes, reprocessing) in real-time.
- Zero-Trust, Policy-as-Code Security: Integrates AI explainability with governance — every decision traceable and auditable.
- Semantic & Multilingual Understanding: Contextual data parsing using LLMs to unify multi-lingual, multi-domain datasets.
- AI-Driven Schema Evolution: Automatic schema detection, mapping, and versioning to prevent model drift.
- Natural Language Orchestration: Enables business users to trigger complex transformations using simple natural language queries.
Forrester’s 2024 and 2025 reports discusses in detail on AI-native orchestration and its role in improving IT operations and incident response.
These advancements democratize data engineering — empowering product managers, analysts, and even non-technical leaders to leverage data directly. Future-proof your architecture in The Anatomy of a Modern Data Quality Framework: Pillars, Roles & Tools Driving Reliable Enterprise Data – Techment
Strategic Business Outcomes & Competitive Edge
AI-powered data engineering delivers quantifiable business impact — not just operational efficiency.
Tangible Outcomes:
- 10× faster time-to-insights: Autonomous pipelines continuously optimize ingestion and transformation.
- 70% reduction in data engineering toil: Automated monitoring, lineage, and quality validation remove manual burden.
- Regulatory advantage: AI-powered governance ensures proactive compliance readiness for frameworks like GDPR, HIPAA, and the EU AI Act.
- Resilience and innovation: Real-time intelligence supports predictive decision-making across sectors like healthcare, fintech, manufacturing, and retail.
In healthcare, predictive data fabrics accelerate clinical analytics. In fintech, anomaly-detection agents prevent fraud in milliseconds. In manufacturing, AI-driven telemetry enables autonomous production adjustments — creating data-intelligent value chains.
Gartner predicts that:
“By 2026, 40% of enterprise applications will feature task-specific AI agents, up from less than 5% in 2025.” This reflects a rapid shift toward AI-native systems, which are expected to enhance operational efficiency and agility. Discover how Techment enhances reliability and compliance in Data-cloud Continuum Brings The Promise of Value-Based Care
AI-Powered Architecture Blueprint
Modern data platforms are shifting from monolithic ETL stacks to intelligence-first architectures where AI governs ingestion, orchestration, and governance. The goal is a self-learning, policy-driven data ecosystem that scales autonomously.
Architecture Layers
- Copilot Layer (Human-in-the-Loop):
- AI copilots assist engineers with real-time code generation, quality validation, and policy checks.
- Integrates seamlessly with existing CI/CD pipelines.
- Agent Layer (Human-off-the-Loop):
- Autonomous agents monitor data health, lineage, and anomaly correction without manual triggers.
- Reinforcement learning models continuously fine-tune performance based on feedback loops.
- Governance & Quality Layer:
- Embeds AI explainability, metadata intelligence, and zero-trust security by design.
- Retrieval-Augmented AI (RAAI) & Data Products:
- Combines API economy and data product thinking to allow re-use of curated data assets across business domains.
According to report by Accenture “Accelerating reinvention to support growth with AI-powered operations”, organizations that have fully modernized, AI-led processes achieve:
- 2.5× higher revenue growth
- 2.4× greater productivity
- 3.3× greater success at scaling generative AI use cases
Compared to peers who have not adopted AI-native architectures Explore more in Cloud-Native Data Engineering: The Future of Scalability for the Enterprise
Build vs Buy: Enterprise AI Data Engineering Playbook
Enterprises face a strategic decision: build AI-native capabilities internally or leverage platform partnerships. A successful roadmap depends on data maturity and organizational readiness.
Maturity Archetypes
- Crawl (Foundational): Manual ETL, basic cataloging, limited automation.
- Walk (Emerging): Hybrid automation, modular orchestration, early AI copilots.
- Run (Advanced): Full AI agents managing reliability, cost, and lineage autonomously.
- Autonomous (Intelligent Fabric): End-to-end self-optimizing systems with proactive remediation.
Organizational Shift
- Move from data plumbers to AI-native data-product builders.
- Establish platform squads that own data domains end-to-end.
- Implement governance guardrails to maintain human control over AI decisions.
Forrester’s 2024 Predictions for Data and Analytics reports that AI and data leaders must work in lockstep to unlock value from data and analytics in support of generative AI. See how Techment operationalized this model in Unleashing the Power of Data: Building a winning data strategy
Future State: The Autonomous Data Fabric
The next 36 months will usher in agentic AI pipelines capable of predicting data needs and healing themselves before incidents occur. Data will evolve into a living, adaptive system that senses organizational context.
Defining Traits
- Predictive Data Ops: AI agents forecast ingestion spikes, schema drift, or governance risks proactively.
- Adaptive Schemas: Systems auto-restructure models as business contexts evolve.
- Revenue Intelligence: Embedded AI identifies monetization opportunities hidden in data flows.
- Trust and Transparency: Explainable AI ensures traceability and compliance across global regulations.
McKinsey Digital (2025) forecasts that companies already seeing 20% of EBIT contributed by AI are more likely to adopt advanced data practices and architectures. Explore how Techment drives reliability by diving deeper into Data-cloud Continuum Brings The Promise of Value-Based Care
Implementation Roadmap (CIO/CTO Action Plan)
Leaders must act with precision and urgency. Below is a pragmatic 90/180/365-day roadmap for transitioning from traditional pipelines to AI-powered data engineering.
0–90 Days — Assessment & Foundation
- Audit current data maturity and automation gaps.
- Prioritize quick-win automation in ingestion and quality validation.
- Upskill teams on LLM copilots and AI Data Ops principles.
Use Techment’s Unlock Your Data Potential: Assess Your Data Maturity Now | Techment
90–180 Days — Platformization
- Introduce AI copilots for schema evolution and pipeline optimization.
- Implement policy-as-code frameworks and start agentic governance pilots.
- Define data-product SLAs across business domains.
180–365 Days — Autonomization
- Transition critical workloads to self-healing pipelines.
- Adopt AI-driven metadata management and lineage visualization.
- Establish continuous feedback loops between data-engineering AI agents and business KPIs.
Gartner’s 2025 Data & Analytics predictions emphasize that nearly 60% of D&A leaders will face critical failures in managing synthetic data, highlighting the need for robust, automated data operations.
See how Techment implemented scalable data automation in The Anatomy of a Modern Data Quality Framework: Pillars, Roles & Tools Driving Reliable Enterprise Data – Techment
Conclusion — The Strategic Imperative
This is not infrastructure modernization — it is a survival advantage.
AI-powered data engineering defines the foundation of the AI-native enterprise, where decisions, insights, and value are generated autonomously.
Organizations that delay this transformation risk data debt, governance fragmentation, and innovation paralysis.
Those that act now will unlock predictive, self-optimizing data ecosystems capable of fueling next-generation AI and analytics.
Explore how Techment can accelerate your AI-data transformation through architecture modernization, automation frameworks, and data-quality intelligence.
FAQs
- How is AI-powered data engineering different from traditional ETL?
AI data engineering introduces autonomous agents and reinforcement learning to optimize pipelines, replacing manual, static ETL scripts with self-healing intelligence. - What are the quickest ways to adopt AI in data engineering?
Start with AI copilots for data quality and metadata management, then progress to agent-based governance and pipeline automation. - Can AI data engineering help with regulatory compliance?
Yes — policy-as-code security and explainable AI make auditing automatic and traceable across GDPR, HIPAA, and AI Act requirements. - What skills will data engineers need in this era?
Engineers must shift from ETL coding to AI ops, data product ownership, and ML observability skills. - Where should enterprises begin their AI data engineering journey?
Start with a maturity assessment, define an AI-first data strategy, and partner with experts like Techment to accelerate implementation.
Related Reads on Techment.com
- Data Management for Enterprises: Roadmap
- Future-Proof Your Data Infrastructure: Benefits of Using MySQL HeatWave for SMEs
- Top 6 Cultural Benefits of Using AI in Enterprise
- AI-Powered Automation: The Competitive Edge in Data Quality Management
- How Data Visualization Revolutionizes Analytics in the Utility Industry?
- Business Intelligence (BI) and Automation: Using Big Data to create