Enterprise adoption of generative AI has accelerated dramatically since the release of large language models (LLMs). Yet while many organizations have experimented with copilots and chatbots, far fewer have moved beyond pilots into scalable, production-grade AI systems.
The reason is architectural.
Choosing the wrong implementation strategy can create expensive AI initiatives that fail to deliver measurable business impact. For technology leaders evaluating enterprise generative AI investments, the real question is no longer whether to deploy LLMs—it is which architecture to deploy.
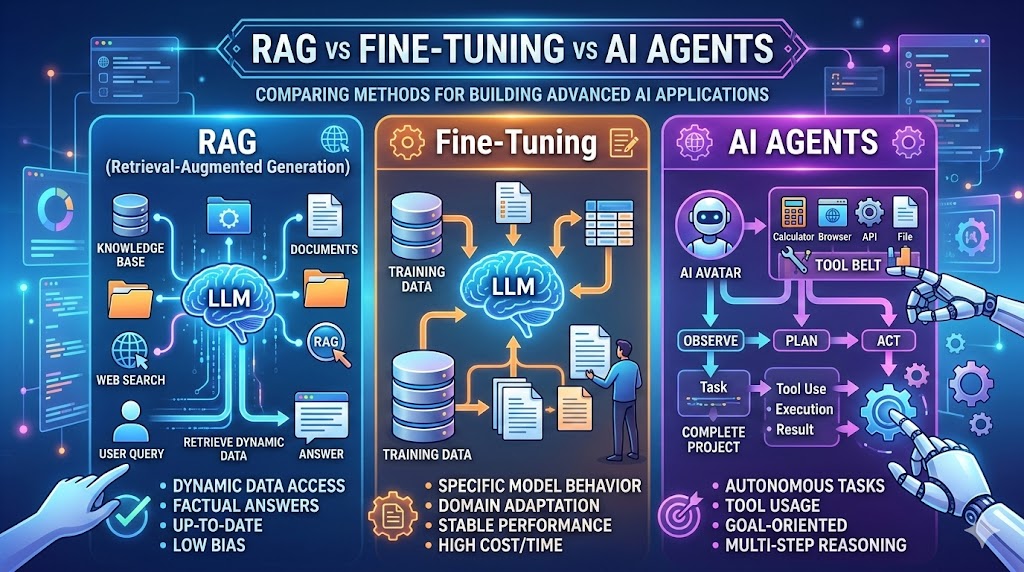
This is where the debate around RAG vs Fine-Tuning vs AI Agents becomes critical.
Each approach solves a different dimension of the enterprise AI challenge:
- Accessing trusted enterprise knowledge
- Embedding deep domain expertise
- Automating complex business workflows
Understanding how these strategies differ—and when to use each—is essential for CTOs, CDOs, and enterprise architects designing next-generation AI platforms.
This guide provides a strategic framework for evaluating RAG, fine-tuning, and AI agents, including architectural trade-offs, cost considerations, implementation timelines, and hybrid deployment patterns used by leading enterprises.
TL;DR (Executive Summary)
- RAG vs Fine-Tuning vs AI Agents represents the three core architectural approaches to implementing enterprise LLM systems.
- RAG connects LLMs to enterprise knowledge bases for real-time, trustworthy responses without retraining.
- Fine-tuning embeds deep domain expertise directly into model weights for specialized tasks and consistent outputs.
- AI agents orchestrate reasoning, decision-making, and tool execution to automate end-to-end workflows.
- Most successful enterprises combine all three approaches, creating hybrid architectures that balance accuracy, specialization, and automation.
The 2025 LLM Strategy Landscape: Why Architecture Matters
Enterprise leaders often begin their generative AI journey by experimenting with foundation models through APIs. But quickly, a major limitation emerges: general-purpose models lack enterprise context.
They cannot access proprietary knowledge, follow internal processes, or execute workflows across enterprise systems.
This gap explains why the conversation around RAG vs Fine-Tuning vs AI Agents has become central to enterprise AI strategy.
Industry research highlights the magnitude of the shift:
- The agentic AI market is projected to grow from $7B in 2025 to $93B by 2032, representing one of the fastest-growing segments in enterprise technology.
- Nearly 80% of enterprises have deployed generative AI, yet many report limited measurable ROI.
- Hybrid LLM architectures combining retrieval, specialized models, and agents are emerging as the dominant pattern.
These trends indicate a transition from experimental AI assistants toward AI systems embedded into enterprise workflows and data ecosystems.
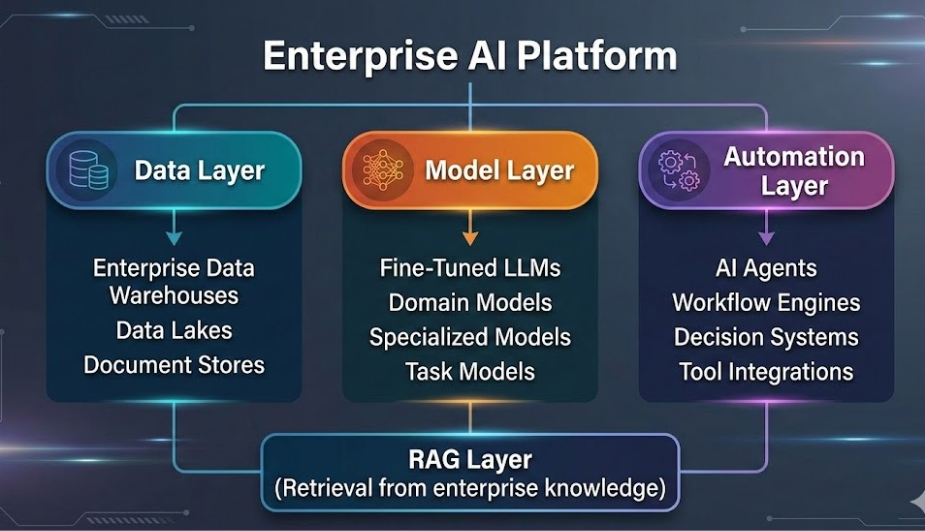
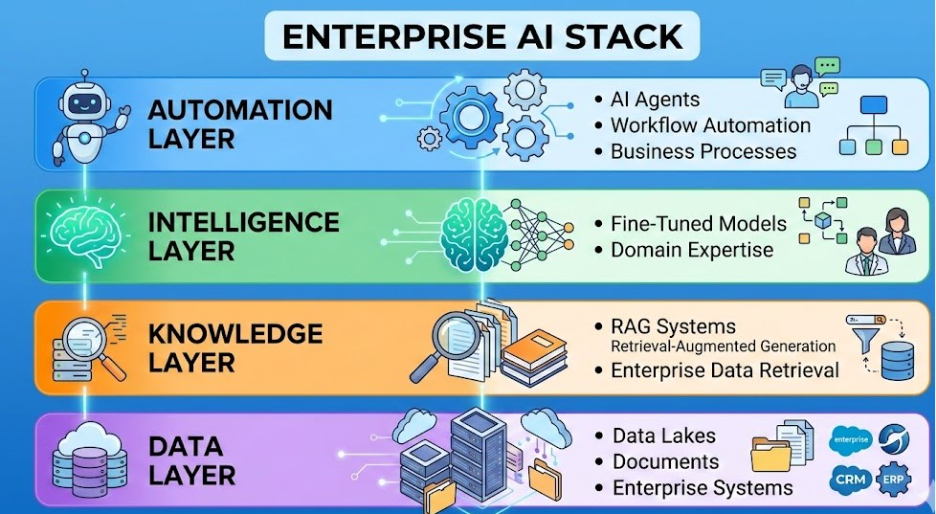
Organizations that succeed with generative AI typically build platforms that combine:
- Enterprise data architecture
- Knowledge retrieval systems
- Specialized models
- Autonomous automation layers
This evolution closely aligns with modern data platform strategies discussed in Techment’s guide to enterprise AI readiness and data strategy.
Without the right architectural approach, AI remains a novelty. With the right architecture, it becomes a core enterprise capability.
As explored in internal AI strategy and road-mapping, improving retrieval precision directly improves generation reliability.
Retrieval-Augmented Generation (RAG): The Foundation of Enterprise AI
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is an architectural approach that enables LLMs to access external knowledge sources during inference.
Instead of relying solely on training data embedded in model weights, a RAG system retrieves relevant information from enterprise repositories and provides that information to the model as context.
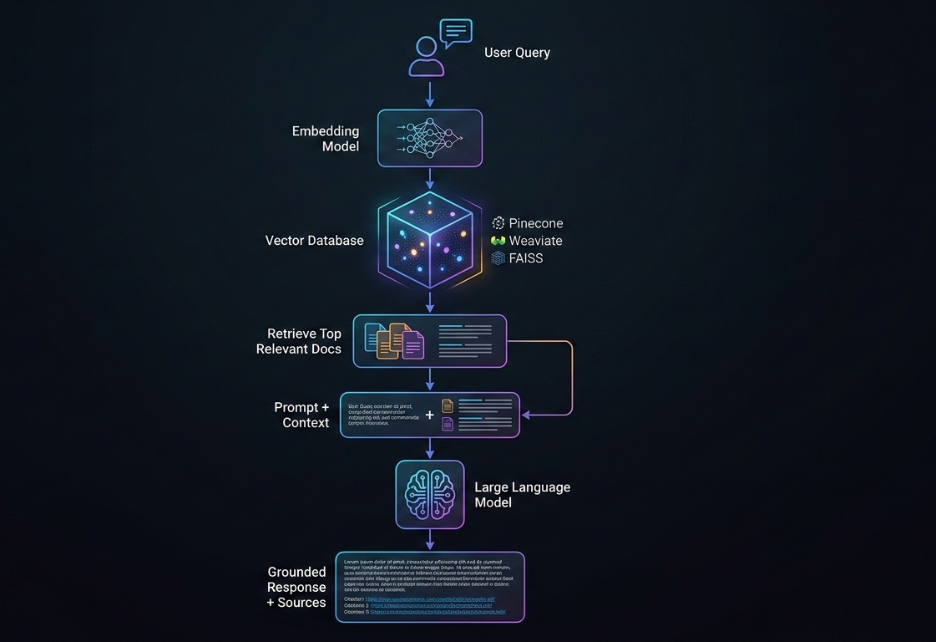
The architecture typically includes four core components:
Vector Embedding Layer
Enterprise documents are converted into vector embeddings using embedding models. These vectors represent semantic meaning rather than keywords.
Vector Database
The embeddings are stored in specialized vector databases such as Pinecone, Weaviate, or FAISS, enabling fast similarity search.
Retrieval Layer
When a user query arrives, the system retrieves the most relevant documents or data fragments.
LLM Generation Layer
The retrieved context is combined with the user prompt, allowing the LLM to generate grounded responses.
This architecture effectively turns an LLM into a knowledge-aware system capable of referencing enterprise data in real time.
For organizations building AI roadmaps, see: Enterprise AI Strategy in 2026
Why RAG is Dominating Enterprise AI Strategies
The primary reason RAG has become central to RAG vs Fine-Tuning vs AI Agents discussions is that it solves the biggest challenge in enterprise AI: access to proprietary knowledge.
Most enterprise information lives in:
- knowledge bases
- internal documents
- product documentation
- CRM systems
- regulatory databases
- internal wikis
- data warehouses
Foundation models cannot access this information.
RAG bridges the gap by connecting LLMs directly to enterprise knowledge ecosystems.
This approach also aligns closely with modern data platform architectures such as data fabrics and unified analytics platforms, which consolidate enterprise data for AI and analytics workloads.
Read our guide on 10 Effective Steps To Building RAG Applications: From Prototype to Production-Grade Enterprise Systems that provides a step-by-step enterprise roadmap for building RAG applications.
Strategic Benefits of RAG for Enterprises
1. Real-Time Knowledge Access
Unlike fine-tuned models, RAG systems retrieve information dynamically.
If new documents are added to a knowledge base, the system immediately incorporates that knowledge without retraining.
This is essential in industries where information changes frequently:
- regulatory compliance
- healthcare guidelines
- product documentation
- financial markets
2. Reduced Hallucinations
Generative models sometimes fabricate information when uncertain.
RAG significantly reduces hallucinations because responses must be grounded in retrieved documents.
Many enterprises report 60–80% accuracy improvements when using RAG architectures compared to standalone models.
3. Transparent AI Outputs
RAG systems can cite sources used to generate responses.
This transparency is critical for:
- regulatory compliance
- auditability
- trust in AI systems
4. Faster Deployment
Compared to model training, RAG implementations are relatively fast.
Typical deployment timelines:
- 4–8 weeks for a production pilot
This makes RAG an attractive entry point for organizations beginning their enterprise AI journey.
Get a comprehensive view about how RAG in 2026 in Enterprise AI scenario has shifted from experimentation to a production-critical architecture to ensure accuracy, compliance, and real-time intelligence.
RAG Use Cases in Enterprise Environments
Customer Support Automation – RAG systems retrieve information from product documentation and knowledge bases to answer customer questions accurately.
Enterprise Knowledge Search – Employees can query internal documentation using natural language rather than navigating complex knowledge repositories.
Compliance and Legal Research – AI systems retrieve relevant regulations, case law, and policy documents.
Healthcare Decision Support – Clinical systems access research papers, treatment guidelines, and patient history.
These implementations closely resemble enterprise conversational AI solutions built on modern cloud platforms.
Read our blog that breaks down 10 critical RAG architectures shaping 2026, their trade-offs, and the enterprise use cases they unlock.
Limitations of RAG
Despite its advantages, RAG is not a universal solution.
Retrieval Quality Determines Output Quality – If the retrieval system returns irrelevant information, the model will produce incorrect responses.
Maintaining high-quality knowledge bases becomes essential.
Latency – Retrieval adds additional processing steps. This typically increases response times by 20–40% compared to standalone LLM inference.
Limited Behavioral Customization – RAG can inject information but does not fundamentally change how the model reasons or writes. If you need consistent tone or specialized reasoning, fine-tuning becomes necessary.
For enterprises exploring early-stage AI assistants, this approach is often aligned with modernization efforts such as those described in Techment’s Best Practices for Generative AI Implementation in Business.
Fine-Tuning LLMs: Embedding Enterprise Expertise
What is Fine-Tuning?
Fine-tuning is the process of training an existing LLM on a curated dataset to specialize the model for a particular domain or task.
Instead of retrieving external information, the model learns domain knowledge directly through parameter updates.
This process typically involves:
- Selecting a base foundation model
- Preparing domain-specific training data
- Training the model on task-specific examples
- Evaluating performance improvements
Fine-tuning effectively teaches the model how experts in a particular domain think and communicate.
Organizations modernizing their data architecture must consider how graph-driven RAG architectures integrate with broader data fabric initiatives such as Microsoft Fabric deployments. Techment’s perspective on modern analytics foundations provides additional context in Microsoft Data Fabric vs Traditional Data Warehousing.
Why Fine-Tuning Matters in Enterprise AI
Fine-tuning addresses a limitation of retrieval-based systems: deep domain expertise.
For example:
A legal model trained on thousands of legal documents will learn:
- legal reasoning patterns
- terminology
- document structures
- argumentation styles
Similarly, a healthcare model trained on clinical documentation learns:
- medical terminology
- diagnostic reasoning
- clinical reporting standards
This type of specialization allows models to produce high-precision outputs for complex tasks.
Strategic Benefits of Fine-Tuning
Deep Domain Expertise – Fine-tuned models internalize domain knowledge rather than retrieving it. This leads to stronger performance on specialized tasks.
Consistent Tone and Style – Organizations often require AI systems to match specific communication styles. Fine-tuning allows models to consistently produce outputs aligned with brand voice.
Faster Inference – Unlike RAG, fine-tuned models do not require retrieval steps. This results in faster response times.
High Accuracy in Narrow Tasks – For tasks like contract analysis or medical report generation, fine-tuned models often outperform general models.
Get an in-depth understanding of the architectural components of Microsoft Fabric with our Microsoft Fabric Architecture Guide.
Challenges of Fine-Tuning
Fine-tuning also introduces several trade-offs.
High Initial Cost
Training models requires:
- GPU compute
- data labeling
- machine learning expertise
Enterprise fine-tuning projects often cost $10,000 to $100,000+.
Static Knowledge
Fine-tuned models cannot dynamically access new information.
When knowledge changes, retraining is required.
Data Requirements
Effective fine-tuning typically requires thousands of labeled examples.
Collecting and preparing this data is often the most time-consuming step.
Enterprises deploying hybrid retrieval must ensure data quality foundations are robust. Retrieval quality is only as strong as the underlying data discipline. Techment’s blueprint on Data Quality for AI in 2026 offers critical insight into this alignment.
When Enterprises Choose Fine-Tuning
Fine-tuning is particularly valuable when organizations need:
- consistent brand voice
- specialized reasoning patterns
- low-latency inference
- domain-specific outputs
Examples include:
- legal contract analysis
- financial reporting automation
- technical documentation generation
- clinical note generation
Many organizations combine fine-tuning with retrieval systems to balance specialization and data freshness.
Enterprises building AI under compliance mandates should align retrieval pipelines with broader governance initiatives such as those described in Data Governance for Data Quality.
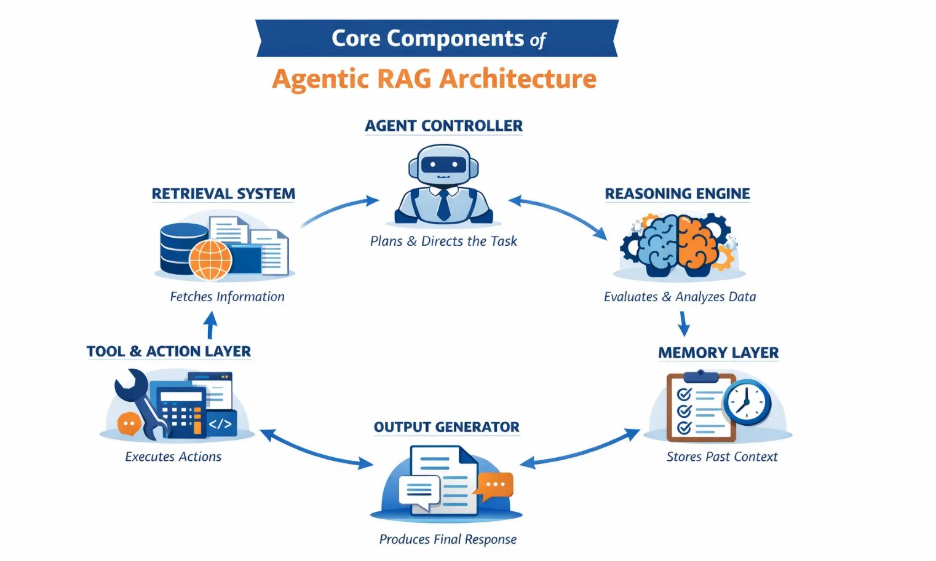
AI Agents: The Rise of Autonomous Enterprise AI
What Are AI Agents?
AI agents represent the next stage in the evolution of enterprise generative AI.
Instead of simply generating responses, agents can:
- plan multi-step tasks
- make decisions
- interact with tools
- execute workflows across systems
An AI agent typically includes:
- an LLM reasoning engine
- memory systems
- tool integrations
- workflow orchestration logic
This allows agents to move beyond answering questions to executing real business processes.
Why AI Agents Are Transforming Enterprise Automation
Agentic AI is gaining momentum because it addresses a key limitation of earlier generative AI systems.
Most copilots assist humans.
Agents replace entire workflows.
For example, in a customer support scenario an agent might:
- analyze the support request
- retrieve relevant information using RAG
- update CRM records
- trigger refund approvals
- notify the customer
All without human intervention.
This shift is why agent-based AI has become a strategic priority for CIOs worldwide.
Explore scalable architectures in AI-Powered Automation: The Competitive Edge in Data Quality Management
Key Capabilities of AI Agents
Autonomous Decision Making
Agents can reason through complex scenarios and determine appropriate actions.
Tool Integration
Agents can interact with APIs and enterprise systems.
Examples include:
- CRM platforms
- ERP systems
- analytics platforms
- communication tools
Workflow Automation
Agents can execute multi-step business processes.
Continuous Learning
Feedback loops allow agents to improve performance over time.
In our enterprise guide on Agentic AI, explore the precise definition and how it differs from generative AI.
Enterprise Use Cases for AI Agents
AI agents are particularly valuable in operational workflows such as:
IT Operations – Agents can detect incidents, analyze logs, and resolve infrastructure issues.
Sales Automation – Agents qualify leads, schedule meetings, and update CRM systems.
Claims Processing – Insurance agents can validate claims and trigger approvals automatically.
Finance Operations – Agents analyze invoices, detect anomalies, and trigger payment workflows.
Read more on how Microsoft Fabric AI solutions fundamentally transform how enterprises unify data, automate intelligence, and deploy AI at scale in our blog.
Challenges with AI Agents
Despite their promise, agent implementations are complex.
Key challenges include:
Reliability – Autonomous systems must achieve extremely high accuracy.
Governance – Agents must comply with enterprise policies and regulatory requirements.
Integration Complexity – Agents require integration with multiple enterprise systems.
Monitoring – Organizations must track agent decisions and outcomes to ensure safe operation.
Side-by-Side Comparison: RAG vs Fine-Tuning vs AI Agents
Understanding the differences between these approaches is critical for enterprise architects designing scalable AI platforms. While discussions around RAG vs Fine-Tuning vs AI Agents often frame them as competing options, in reality they solve distinct layers of the enterprise AI stack.
| Dimension | RAG | Fine-Tuning | AI Agents |
| Purpose | Access enterprise knowledge | Embed domain expertise | Automate workflows |
| Data Freshness | Real-time | Static until retraining | Real-time via integrations |
| Implementation Time | 4–8 weeks | 8–16 weeks | 12–24 weeks |
| Upfront Cost | Low | Medium–High | Medium–High |
| Operational Cost | Moderate | Low | High but scalable |
| Latency | Moderate | Fast | Variable |
| Best Use Case | Knowledge assistants | Domain specialization | Process automation |
| Example | Enterprise search | Legal analysis | Claims processing |
Architectural Roles of the Three Approaches
Retrieval-Augmented Generation (RAG) primarily addresses the knowledge access layer. It ensures AI systems can retrieve and reason over enterprise information such as documentation, policy records, and operational data.
Fine-tuning addresses the intelligence specialization layer. It allows models to adopt domain-specific reasoning patterns, communication styles, and task-specific expertise.
AI agents represent the execution layer. They orchestrate LLM reasoning, enterprise data retrieval, and tool usage to complete end-to-end workflows.
Together, they form the building blocks of modern enterprise AI platforms.
Explore how Techment enables organizations to operationalize AI through RAG architectures and autonomous AI Agents.
Enterprise Comparison Across Key Dimensions
Purpose
RAG connects LLMs to proprietary enterprise knowledge. Fine-tuning embeds specialized expertise into model parameters. AI agents automate workflows using LLM reasoning combined with tools.
Knowledge Freshness
RAG delivers the most current information because knowledge is retrieved dynamically. Fine-tuned models contain static knowledge snapshots until retrained. AI agents typically rely on real-time integrations with enterprise systems.
Implementation Complexity
RAG implementations are typically the fastest to deploy because they require data indexing rather than model training. Fine-tuning introduces additional complexity due to dataset preparation and model training pipelines. Agent systems are the most complex because they involve orchestration, tool integrations, and safety frameworks.
Performance Characteristics
Fine-tuned models typically offer the fastest inference speeds since no retrieval step is required. RAG introduces additional latency due to document retrieval. AI agents vary depending on workflow complexity and number of system interactions.
Best Enterprise Applications
RAG excels in knowledge-heavy applications such as enterprise search and compliance queries. Fine-tuning performs best for specialized domain tasks requiring consistent outputs. AI agents excel in multi-step workflows such as claims processing or IT operations.
For enterprises implementing conversational AI at scale: Conversational AI on Microsoft Azure
Decision Framework: How Enterprises Choose the Right LLM Strategy
Selecting the right approach requires evaluating several strategic factors rather than focusing solely on technical capabilities.
Enterprise technology leaders evaluating RAG vs Fine-Tuning vs AI Agents should consider three primary dimensions:
- Data characteristics
- Business objectives
- organizational readiness
Data Characteristics
The nature of enterprise data strongly influences which LLM architecture delivers the best results.
Frequently Changing Data
When knowledge updates frequently—such as regulatory requirements, product documentation, or operational metrics—RAG becomes the preferred architecture.
Retrieval systems dynamically access updated information without requiring model retraining.
Stable Domain Knowledge
Domains with relatively static information—such as legal frameworks or scientific terminology—often benefit from fine-tuning because specialized reasoning patterns remain stable over time.
Workflow-Oriented Data
When the objective involves executing business processes rather than answering questions, AI agents become essential. Agents can interpret data, make decisions, and initiate actions across systems.
Learn how our Microsoft Fabric Readiness Assessment explores your full data lifecycle across five critical dimensions.
Business Objective Alignment
Different AI architectures support different types of business outcomes.
Information Access
Organizations aiming to improve knowledge discovery and internal decision-making often start with RAG systems.
Examples include:
- enterprise search
- internal knowledge assistants
- regulatory research tools
Specialized Task Performance
Fine-tuning becomes valuable when the objective is high performance on specialized tasks such as contract analysis, medical documentation, or technical report generation.
Process Automation
AI agents deliver the greatest value when enterprises want to automate complex processes involving multiple steps and systems.
Examples include:
- order processing
- claims validation
- IT incident response
- financial reconciliation workflows
Organizational Readiness
Enterprise maturity in AI engineering also influences architectural decisions.
Early AI Maturity
Organizations beginning their generative AI journey often adopt RAG because it requires less machine learning expertise and delivers rapid results.
Mature AI Engineering Teams
Companies with dedicated AI engineering capabilities can invest in fine-tuning models and building custom training pipelines.
Advanced Automation Initiatives
Enterprises pursuing digital transformation and workflow automation are well positioned to adopt agentic AI systems.
Read about AI, data and analytics trends to rule in 2026 for better insights and strategy road mapping.
Cost Analysis and Total Cost of Ownership
Cost considerations are another critical factor in the RAG vs Fine-Tuning vs AI Agents decision.
Each architecture has a different cost structure that affects both short-term budgets and long-term operational expenses.
Know more about data migration steps in our in-depth guide to transform your data into a gold mine for your enterprise.
RAG Cost Structure
Initial Implementation
RAG deployment typically includes:
- vector database setup
- document ingestion pipelines
- embedding generation
- LLM integration
Typical setup costs range between $5,000 and $50,000 depending on infrastructure scale and data complexity.
Operational Costs
Ongoing expenses include:
- vector database hosting
- embedding generation for new documents
- LLM inference costs
- maintenance and monitoring
Monthly operational costs typically range between $1,000 and $10,000, scaling with usage volume.
| Approach | Setup Cost | Monthly Cost |
| RAG | $5K–$50K | $1K–$10K |
| Fine-Tuning | $10K–$100K | $1K–$5K |
| AI Agents | $10K–$100K | $5K–$50K |
Fine-Tuning Cost Structure
Fine-tuning requires higher upfront investment because organizations must prepare training datasets and run model training jobs.
Training Costs
Common cost components include:
- data labeling
- GPU compute resources
- machine learning engineering
- model evaluation and testing
Total project costs typically range between $10,000 and $100,000+.
Ongoing Costs
Operational expenses include:
- model inference
- periodic retraining
- monitoring for model drift
Retraining cycles often occur every 6–12 months depending on domain evolution.
AI Agent Cost Structure
AI agent implementations involve both model usage and system orchestration.
Development Costs
Initial development typically includes:
- workflow mapping
- agent framework implementation
- API integrations
- safety guardrails
Typical development costs range between $10,000 and $100,000+ depending on workflow complexity.
Operational Costs
Ongoing costs include:
- LLM token usage
- orchestration platform fees
- system integrations
- monitoring and maintenance
Monthly costs often range between $5,000 and $50,000 depending on automation scale.
However, agent systems often deliver the largest ROI because they replace manual processes and reduce operational overhead.
Get a clear, enterprise-grade comparison of agentic vs copilot AI, grounded in process maturity, risk tolerance, and operational readiness.
Hybrid LLM Architectures: Why Most Enterprises Combine All Three
In practice, the debate around RAG vs Fine-Tuning vs AI Agents often leads to a single conclusion: the most successful implementations combine all three approaches.
Research suggests that nearly 60% of enterprise AI deployments use hybrid architectures.
Hybrid systems allow organizations to balance specialization, real-time knowledge access, and automation.
Hybrid Architecture Pattern 1: Fine-Tuning + RAG
In this pattern, the model is fine-tuned for domain expertise while RAG provides real-time data access.
Example: Healthcare clinical decision support systems.
The model understands medical terminology and diagnostic reasoning through fine-tuning, while RAG retrieves current research papers and patient records.
This approach combines expertise with currency.
Hybrid Architecture Pattern 2: RAG + AI Agents
This architecture uses RAG for knowledge access while agents execute workflows.
Example: Insurance claims automation.
The system retrieves policy documentation using RAG, then agents validate claims and trigger approvals.
This pattern enables data-driven automation.
Hybrid Architecture Pattern 3: Full Enterprise AI Stack
The most advanced architectures combine:
- fine-tuned domain models
- RAG knowledge retrieval
- AI agents for automation
Example: enterprise customer success platforms.
These systems analyze customer data, retrieve support history, generate recommendations, and automatically trigger engagement workflows.
This architecture represents the future of intelligent enterprise platforms.
See how insights become decisions in Enterprise Data Quality Framework: Best Practices for Reliable Analytics and AI
Implementation Roadmap for Enterprise LLM Strategies
Deploying enterprise AI successfully requires structured implementation rather than isolated experimentation.
Below is a strategic roadmap commonly used by organizations adopting hybrid LLM architectures.
Phase 1: RAG Foundation (Months 1–3)
Enterprises typically begin by implementing RAG systems because they deliver immediate value.
Key activities include:
- identifying high-impact knowledge use cases
- auditing enterprise data sources
- building document ingestion pipelines
- deploying vector search infrastructure
This phase establishes the knowledge layer for enterprise AI.
Phase 2: Model Specialization (Months 4–9)
After establishing knowledge access, organizations begin specializing models through fine-tuning.
Activities include:
- identifying specialized tasks
- collecting training datasets
- running fine-tuning experiments
- evaluating performance improvements
This stage improves accuracy and domain expertise.
Phase 3: Workflow Automation (Months 10–18)
Finally, organizations introduce AI agents to automate workflows.
Key steps include:
- mapping business processes
- integrating enterprise systems
- implementing safety guardrails
- deploying monitoring systems
This phase transforms AI from an assistant into an operational system.
How Techment Helps Enterprises Implement LLM Strategies
Implementing enterprise AI architectures requires more than selecting technologies. It requires aligning data strategy, governance, and AI engineering to build scalable AI platforms.
Techment helps organizations design and implement modern AI architectures across several critical areas.
Enterprise Data Modernization
Successful AI initiatives depend on well-structured enterprise data platforms. Techment helps organizations modernize data architectures to support analytics, machine learning, and generative AI initiatives.
AI-Ready Data Foundations
Data quality and governance are essential prerequisites for reliable AI systems. Techment’s expertise in data quality frameworks and governance strategies ensures enterprise data is trustworthy and compliant before being integrated into AI platforms.
These practices are detailed in Techment’s guidance on building AI-ready data ecosystems and enterprise data governance frameworks.
LLM Architecture Design
Techment supports organizations in designing hybrid architectures that combine:
- retrieval systems
- fine-tuned models
- agent orchestration frameworks
This approach ensures AI solutions scale across enterprise environments.
Cloud and AI Platform Implementation
From Azure-based AI platforms to modern analytics architectures, Techment helps enterprises deploy scalable infrastructure capable of supporting advanced AI workloads.
Governance and Responsible AI
Enterprise AI initiatives require strong governance frameworks. Techment helps organizations implement responsible AI practices, ensuring transparency, compliance, and ethical AI deployment.
Through this holistic approach, Techment enables organizations to move from AI experimentation to enterprise-scale AI transformation.
Lay the groundwork for AI readiness, identify ROI-positive use cases, and build a prioritized execution roadmap designed for value, feasibility, and governance with our AI services.
Conclusion
The discussion around RAG vs Fine-Tuning vs AI Agents reflects a broader shift in enterprise AI strategy.
Organizations are moving beyond standalone AI models toward integrated AI platforms capable of reasoning, accessing enterprise knowledge, and executing workflows.
Each architectural approach plays a unique role:
- RAG enables AI systems to access trusted enterprise data in real time.
- Fine-tuning embeds domain expertise and specialized reasoning patterns.
- AI agents transform AI systems into autonomous operators capable of executing business processes.
The most successful enterprises do not treat these approaches as mutually exclusive. Instead, they design hybrid architectures that combine retrieval, specialized models, and agent orchestration.
As enterprise AI adoption accelerates, the ability to design and implement the right LLM architecture will become a critical competitive advantage.
Organizations that invest in scalable AI foundations today will be best positioned to unlock the full potential of intelligent automation and data-driven decision-making in the years ahead.
See how your enterprise can develop self-service capabilities and integrate augmented analytics/AI modules in our solution offerings.
Frequently Asked Questions
1. What is the difference between RAG and fine-tuning?
RAG retrieves relevant data from external knowledge sources during inference, allowing models to generate responses based on current information. Fine-tuning modifies the model itself by training it on specialized datasets, embedding domain expertise directly into model parameters.
2. When should enterprises use AI agents instead of RAG?
AI agents should be used when the goal is to automate multi-step workflows rather than simply retrieve information. Agents can analyze data, make decisions, and execute actions across enterprise systems.
3. Can RAG and fine-tuning be used together?
Yes. Many enterprises combine fine-tuned models with RAG architectures to balance domain expertise and real-time knowledge access.
4. How long does it take to implement enterprise LLM systems?
Typical implementation timelines vary by architecture:
RAG systems: 4–8 weeks
Fine-tuned models: 8–16 weeks
AI agent systems: 12–24 weeks
5. Which approach offers the best ROI?
ROI depends on the business objective. RAG often delivers the fastest ROI through improved knowledge access, while AI agents typically deliver the highest long-term ROI through workflow automation.