Introduction
Generative AI is no longer experimental—it is becoming a core enterprise capability. However, as organizations scale large language models (LLMs) across customer service, analytics, and internal workflows, a new challenge emerges uncontrolled cost escalation.
Cost optimization strategies for LLM deployments are now a top priority for CTOs, CDOs, and AI leaders. Unlike traditional software systems, LLMs introduce variable, usage-based costs driven by tokens, compute cycles, latency requirements, and data processing pipelines. Without strategic planning, enterprises risk turning AI innovation into an unsustainable financial burden.
According to industry estimates, poorly optimized LLM deployments can inflate operational costs by 30–70%, especially in high-scale environments. This makes cost optimization not just a technical concern—but a board-level strategic imperative.
This blog provides a comprehensive enterprise playbook for cost optimization strategies for LLM deployments, covering architecture, governance, infrastructure, and operational best practices. It also explores how organizations can balance performance, scalability, and cost efficiency without compromising business outcomes.
TL;DR Summary
- LLM deployments can become the largest hidden cost center in enterprise AI initiatives
- Token usage, infrastructure scaling, and model selection drive most expenses
- Strategic cost optimization requires architectural, operational, and governance alignment
- Techniques like caching, model routing, and RAG significantly reduce costs
- Enterprises must adopt FinOps-style governance for AI to ensure sustainable ROI
Why Cost Optimization for LLM Deployments Is a Strategic Imperative
The Shift from Experimentation to Scale
In early AI adoption phases, cost was secondary to innovation. Enterprises focused on proof-of-concepts, pilots, and experimentation. However, as LLMs move into production, cost dynamics fundamentally change.
At scale, LLM deployments involve:
- Continuous API calls or inference workloads
- Large-scale data ingestion and retrieval systems
- High-performance compute environments (GPUs/TPUs)
- Real-time user interactions requiring low latency
Each of these layers introduces compounding costs.
To operationalize such capabilities, organizations need robust foundations in data reliability—explored in Microsoft Fabric Architecture: CTO’s Guide to Modern Analytics & AI
The Hidden Cost Drivers in LLM Ecosystems
Token consumption is the most visible cost factor, but it is not the only one. Enterprises often underestimate:
- Prompt inefficiency leading to excessive token usage
- Over-provisioned infrastructure for peak loads
- Redundant inference requests due to lack of caching
- Inefficient model selection, using large models for simple tasks
- Data pipeline costs, especially in RAG-based architectures
This creates a fragmented cost structure that is difficult to manage without a unified strategy. As highlighted in Gartner’s guidance on managing generative AI costs, enterprises that fail to implement structured cost governance and optimization frameworks for large language models risk significant budget overruns, with AI-related operational expenses increasing unpredictably as usage scales—making cost optimization strategies for LLM deployments a critical pillar of sustainable, enterprise-wide AI adoption.
Business Impact: From ROI to Risk
Unoptimized LLM deployments can impact enterprises in three critical ways:
- Eroded ROI: High operational costs reduce the value of AI investments
- Budget unpredictability: Variable usage leads to inconsistent spending
- Scaling limitations: Cost constraints restrict enterprise-wide adoption
Organizations that fail to implement cost optimization strategies for LLM deployments risk slowing down innovation at the exact moment when AI is becoming a competitive differentiator.
To align cost efficiency with business outcomes, enterprises must rethink their approach to AI architecture and governance. A strong foundation begins with a clear data strategy, as outlined in Techment’s guide: Enterprise AI Strategy in 2026
Understanding the Cost Structure of LLM Deployments
Breaking Down the LLM Cost Stack
To implement effective cost optimization strategies for LLM deployments, enterprises must first understand where costs originate.
Core cost components include:
- Model Inference Costs
- Charged per token (input + output)
- Varies by model size and provider
- Infrastructure Costs
- GPU/CPU usage for self-hosted models
- Cloud compute for scaling workloads
- Data Processing Costs
- Storage, transformation, and retrieval
- Vector databases in RAG pipelines
- Networking & Latency Costs
- Data transfer between services
- Edge vs centralized processing trade-offs
- Operational Overhead
- Monitoring, logging, and orchestration
- DevOps and MLOps complexity
Advanced Cost Drivers in Enterprise LLM Deployments
Beyond token usage and infrastructure, enterprise-scale LLM deployments introduce multi-dimensional cost drivers that are often overlooked.
Critical cost multipliers include:
- Model Complexity: Larger parameter models exponentially increase inference costs
- Concurrency Levels: High parallel usage drives compute spikes
- Fine-Tuning Cycles: Continuous retraining increases compute and storage costs
- Data Transfer Overhead: Cross-region or multi-cloud architectures increase latency and cost
- Idle Resource Allocation: Over-provisioned environments lead to wasted spend
Sample Enterprise Cost Distribution
| Cost Component | % Contribution | Optimization Potential |
|---|---|---|
| Token Usage | 30–50% | High |
| Infrastructure (GPU/CPU) | 20–35% | High |
| Data Pipelines (RAG) | 10–20% | Medium |
| Monitoring & Ops | 5–10% | Medium |
| Networking | 5–10% | Low–Medium |
Why Cost Visibility Is the First Step
Many enterprises lack granular cost observability across AI systems. Without visibility:
- Optimization becomes reactive instead of proactive
- Cost anomalies go undetected
- Scaling decisions are based on incomplete data
This is where data governance and observability frameworks become critical. Enterprises must integrate cost tracking into their broader data ecosystem, similar to approaches outlined in: Best Practices for Generative AI Implementation in Business
Core Cost Optimization Strategies for LLM Deployments
Strategy 1: Optimize Token Usage
Token inefficiency is the single largest cost driver in LLM deployments.
Key techniques include:
- Prompt compression and refinement
- Eliminating redundant context
- Using structured prompts instead of verbose instructions
- Limiting output length where possible
Even a 10–20% reduction in token usage can translate into significant cost savings at scale.
Strategy 2: Model Selection and Routing
Not every task requires a large, expensive model.
Best practice:
Implement model routing architectures where:
- Simple queries → smaller models
- Complex reasoning → larger models
This reduces unnecessary expenditure on high-cost models.
Strategy 3: Retrieval-Augmented Generation (RAG)**
RAG reduces dependency on large models by grounding responses in enterprise data.
Benefits:
- Lower token usage
- Improved accuracy
- Reduced hallucinations
However, RAG introduces its own cost layer (vector search, storage), which must be optimized carefully.
Strategy 4: Caching and Reuse
A significant percentage of LLM queries are repetitive.
Caching strategies include:
- Response caching for identical queries
- Semantic caching for similar queries
- Embedding reuse
This can reduce inference costs by up to 40% in high-volume systems.
Strategy 5: Infrastructure Optimization
For self-hosted models:
- Use auto-scaling clusters
- Optimize GPU utilization
- Leverage spot instances where feasible
For API-based models:
- Optimize request batching
- Reduce latency overhead
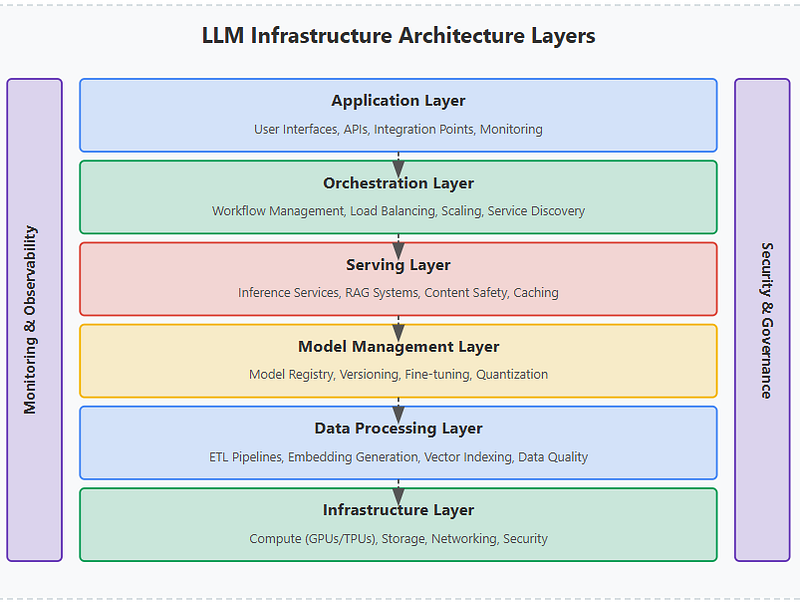
Enterprise Insight
Cost optimization strategies for LLM deployments are not isolated tactics—they must be implemented as part of a holistic architecture. This aligns closely with modern data platform strategies such as those discussed in:
Advanced Architectural Patterns for Cost Efficiency
Multi-Model Architectures
Enterprises are increasingly adopting multi-model ecosystems instead of relying on a single LLM.
Advantages:
- Cost control through workload distribution
- Vendor flexibility
- Performance optimization
Edge vs Cloud Processing
Deciding where inference happens can significantly impact cost.
- Cloud inference: scalable but expensive at scale
- Edge inference: lower latency and cost for specific use cases
Asynchronous Processing
Not all LLM workloads require real-time responses.
Batch processing can:
- Reduce compute costs
- Improve system efficiency
Observability-Driven Optimization
Modern AI systems must integrate:
- Cost monitoring dashboards
- Token usage analytics
- Performance-cost trade-off metrics
Visualization Suggestion
Infographic Recommendation:
Decision tree for selecting optimal architecture based on latency, cost, and workload type
Strategic Takeaway
Architecture decisions define up to 60% of long-term LLM costs. Enterprises must design systems with cost efficiency as a core principle—not an afterthought.
For deeper insights into aligning architecture with enterprise AI strategy, refer to: Fabric AI Readiness: How to Prepare Your Data for Scalable AI Adoption
Governance, FinOps, and Cost Control Frameworks for LLM Deployments
Why FinOps for AI Is No Longer Optional
As enterprises scale generative AI, traditional cloud FinOps models are proving insufficient. LLM deployments introduce non-linear, usage-based cost patterns that require a new discipline: AI FinOps.
Cost optimization strategies for LLM deployments must evolve from ad hoc cost-cutting to continuous financial governance.
Key challenges include:
- Unpredictable token consumption patterns
- Rapid scaling of AI use cases across departments
- Lack of standardized cost attribution models
- Difficulty aligning cost with business value
Without governance, AI costs become opaque and uncontrollable.
Building an AI Cost Governance Framework
An enterprise-grade governance model should include:
1. Cost Allocation Models
Assign AI costs to business units, products, or use cases to ensure accountability.
2. Budget Guardrails
Set thresholds for:
- Token usage
- API calls
- Compute consumption
3. Usage Policies
Define acceptable usage patterns, including:
- Maximum context lengths
- Allowed models per use case
- Rate limits
4. Real-Time Monitoring
Implement dashboards tracking:
- Cost per request
- Cost per user/session
- Cost per business outcome
To build robust governance frameworks, enterprises should explore Data Governance for Data Quality: Future-Proofing Enterprise Data.
AI FinOps Operating Model
| Layer | Responsibility | Outcome |
|---|---|---|
| Finance | Budgeting, forecasting | Cost predictability |
| Engineering | Optimization, architecture | Efficiency |
| Data/AI Teams | Model usage governance | Controlled scaling |
| Leadership | ROI alignment | Strategic value realization |
Enterprise Insight
Organizations that integrate AI cost governance into their broader data governance strategy achieve significantly better outcomes. This aligns with principles outlined in: Data Quality for AI in 2026: The Ultimate Blueprint for Accuracy, Trust & Scalable Enterprise Adoption
Balancing Cost, Performance, and Accuracy: Trade-Offs Enterprises Must Navigate
The Cost vs Performance Dilemma
One of the most critical aspects of cost optimization strategies for LLM deployments is managing trade-offs.
Enterprises must constantly balance:
- Cost efficiency vs model accuracy
- Latency vs user experience
- Scalability vs infrastructure investment
For example:
- Using a smaller model reduces cost but may impact response quality
- Reducing context size lowers token usage but may reduce accuracy
Strategic Trade-Off Framework
High-Value Use Cases (e.g., decision intelligence):
- Prioritize accuracy and reliability
- Accept higher costs
High-Volume Use Cases (e.g., chatbots):
- Prioritize cost efficiency
- Optimize aggressively
Latency-Sensitive Use Cases (e.g., real-time assistants):
- Balance cost with performance
Risk Considerations
Cost optimization should not introduce:
- Increased hallucinations
- Compliance risks due to reduced context
- Poor user experience
Model Selection Trade-Offs in LLM Deployments
| Model Type | Cost per Token | Accuracy | Latency | Ideal Use Case |
|---|---|---|---|---|
| Large LLM (GPT-4 class) | Very High | Very High | Medium | Complex reasoning, decision AI |
| Mid-size Models | Medium | High | Low | Enterprise copilots |
| Small Models | Low | Medium | Very Low | Chatbots, FAQs |
| Fine-tuned Models | Medium | Very High | Low | Domain-specific use cases |
| Open-source LLMs | Variable | Medium–High | Medium | Cost-sensitive deployments |
Strategic Takeaway
Cost optimization strategies for LLM deployments must be context-aware. A one-size-fits-all approach leads to suboptimal outcomes.
For leaders evaluating platform strategies, Microsoft Fabric vs Snowflake Data Management Showdown provides a comparative perspective.
Implementation Roadmap: A Step-by-Step Enterprise Approach
Phase 1: Baseline Assessment
Before optimization, enterprises must establish a baseline:
- Current LLM usage patterns
- Cost per use case
- Infrastructure utilization
- Token consumption metrics
Phase 2: Quick Wins
Immediate cost reduction opportunities include:
- Prompt optimization
- Output length control
- Caching implementation
- Model downgrading for simple tasks
These can deliver 10–30% cost savings within weeks.
Phase 3: Architectural Optimization
- Implement RAG pipelines
- Introduce model routing
- Optimize infrastructure scaling
- Redesign data pipelines
Phase 4: Governance & Automation
- Deploy cost monitoring dashboards
- Implement budget controls
- Automate scaling policies
- Integrate AI FinOps
Phase 5: Continuous Optimization
- Regular cost audits
- Performance-cost benchmarking
- Model updates and tuning
Enterprise Insight
Organizations that treat cost optimization as a continuous lifecycle—rather than a one-time initiative—achieve sustainable AI scalability.
This aligns with best practices discussed in: Best Practices for Generative AI Implementation in Business
Comparative Analysis of Cost Optimization Strategies for LLM Deployments
| Strategy | Cost Impact | Complexity | Best Use Case | Trade-offs |
|---|---|---|---|---|
| Prompt Optimization | High | Low | All LLM workloads | May reduce context richness |
| Model Routing | High | Medium | Multi-use case systems | Requires orchestration logic |
| RAG (Retrieval-Augmented Generation) | Medium–High | High | Knowledge-heavy applications | Adds infra + latency |
| Caching (Semantic + Exact) | High | Medium | High-volume repetitive queries | Cache invalidation complexity |
| Output Control | Medium | Low | Chatbots, assistants | May impact completeness |
| Infrastructure Scaling | Medium | High | Self-hosted deployments | Requires DevOps maturity |
| Batch Processing | Medium | Medium | Non-real-time workloads | Increased latency |
Future Trends: The Next Frontier of LLM Cost Optimization
Model Innovation and Cost Reduction
The rapid evolution of LLMs is driving:
- Smaller, more efficient models
- Open-source alternatives reducing dependency on expensive APIs
- Specialized domain models with lower compute requirements
AI Hardware Advancements
Emerging hardware innovations include:
- AI-optimized chips
- Energy-efficient GPUs
- Edge AI accelerators
These will significantly impact cost structures.
Autonomous Optimization Systems
Future AI platforms will include:
- Self-optimizing prompt systems
- Automated model selection
- Dynamic cost-performance tuning
Strategic Outlook
Cost optimization strategies for LLM deployments will increasingly become automated, intelligent, and integrated into enterprise AI platforms.
Enterprises that invest early in optimization frameworks will gain a long-term competitive advantage.
To understand how modern platforms enable scalable AI, refer to: Microsoft Fabric Architecture: A CTO’s Guide to Modern Analytics & AI
How Techment Helps Enterprises Optimize LLM Costs
Techment enables enterprises to move beyond fragmented optimization efforts and adopt a holistic, enterprise-grade cost optimization strategy for LLM deployments.
Strategic Capabilities
1. AI & Data Strategy Alignment
Techment helps organizations align LLM initiatives with business outcomes, ensuring cost efficiency is embedded from the start.
2. Modern Data Platform Implementation
Using platforms like Microsoft Fabric and Azure, Techment builds scalable, cost-efficient AI ecosystems.
3. RAG and Intelligent Architectures
Design and implementation of retrieval-augmented systems that reduce token dependency and improve accuracy.
4. AI Governance & FinOps Enablement
Establishing frameworks for:
- Cost monitoring
- Budget control
- Usage governance
5. Performance-Cost Optimization
Balancing latency, accuracy, and cost through advanced architecture and model strategies.
To understand how unified analytics can drive enterprise value, explore Microsoft Fabric AI Solutions for Enterprise Intelligence
End-to-End Approach
Techment supports enterprises across:
- Strategy → Architecture → Implementation → Optimization
This ensures that cost optimization strategies for LLM deployments are not isolated initiatives but part of a sustainable AI transformation journey.
Conclusion
Cost optimization strategies for LLM deployments are no longer optional—they are foundational to enterprise AI success. As organizations scale generative AI, the ability to control costs while maintaining performance and accuracy will define competitive advantage.
From token optimization and architectural design to governance and FinOps, enterprises must adopt a multi-layered approach to cost efficiency. The most successful organizations will treat cost optimization not as a constraint, but as a strategic enabler of scalable AI innovation.
Looking ahead, advancements in models, infrastructure, and automation will further transform the cost landscape. Enterprises that invest in robust optimization frameworks today will be best positioned to capitalize on the next wave of AI-driven transformation.
Techment stands as a trusted partner in this journey—helping organizations design, implement, and optimize enterprise AI systems that are not only powerful, but also financially sustainable.
FAQs
1. What are the biggest cost drivers in LLM deployments?
Token usage, infrastructure costs, and data pipelines (especially RAG systems) are the primary contributors.
2. How can enterprises reduce LLM costs quickly?
Quick wins include prompt optimization, caching, and using smaller models for simple tasks.
3. Is RAG always cost-effective?
RAG reduces token costs but introduces infrastructure overhead. It is cost-effective when optimized properly.
4. How important is governance in LLM cost optimization?
Critical. Without governance, costs become unpredictable and difficult to control at scale.
5. Can open-source models reduce costs?
Yes, but they introduce infrastructure and maintenance complexity. Trade-offs must be evaluated carefully.