
Enterprise AI leaders are no longer debating whether to use retrieval augmentation. The real question in 2026 is far more strategic: which RAG architectures align with your enterprise workload, governance model, and risk tolerance?
As AI agents mature and generative systems move from experimentation to production, naive retrieval pipelines are proving insufficient. Enterprise environments require accuracy, relationship awareness, cost efficiency, explainability, and architectural flexibility. That is where modern RAG architectures diverge into specialized patterns.
From Hybrid RAG that combines lexical and semantic search, to Agentic Graph RAG that autonomously explores knowledge networks, the retrieval layer has become the strategic backbone of enterprise AI systems.
This blog breaks down 10 critical RAG architectures shaping 2026, their trade-offs, and the enterprise use cases they unlock. More importantly, it provides a decision framework for CTOs, CDOs, and AI leaders determining which architecture fits their next AI initiative.
TL;DR Summary
- RAG architectures are no longer one-size-fits-all; specialization defines 2026 enterprise AI systems.
- Hybrid RAG is becoming the production baseline for accuracy and robustness.
- Graph and Agentic RAG architectures enable multi-hop reasoning and cross-system intelligence.
- Adaptive and Self-RAG optimize cost, latency, and reliability dynamically.
- Selecting the right RAG architecture is now a strategic architectural decision — not an implementation detail.
Why RAG Architectures Are Strategic Infrastructure in 2026
In 2026, retrieval-augmented generation is no longer a feature layer — it is enterprise AI infrastructure.
Early generative AI deployments treated retrieval as a bolt-on enhancement to reduce hallucinations. That model no longer holds. As AI systems move into regulated, revenue-impacting, and mission-critical workflows, the retrieval layer determines whether outputs are reliable, auditable, and economically sustainable.
Three structural shifts have elevated RAG architectures to infrastructure status:
1. Enterprise Knowledge Scale Exceeds Model Context
Even with expanded context windows, enterprise data ecosystems span billions of tokens across data lakes, SaaS systems, document repositories, and structured databases. Injecting raw data into prompts is computationally wasteful and governance-risky. Strategic retrieval ensures only relevant, permission-compliant, high-signal information enters generation.
2. Governance and Compliance Are Non-Negotiable
Enterprise AI systems must enforce role-based access, data lineage, audit logs, and explainability. RAG architectures act as a policy enforcement layer — filtering what the model is allowed to see before generation occurs. In regulated industries, retrieval design is inseparable from compliance design.
3. Cost and Latency Are Board-Level Concerns
Uncontrolled prompt expansion and multi-step reasoning can create unpredictable inference costs. Modern RAG architectures — particularly Hybrid and Adaptive patterns — introduce cost discipline by optimizing retrieval depth based on query complexity.
4. AI Systems Are Becoming Multi-System Orchestrators
Enterprise copilots no longer answer static questions. They access CRM systems, financial databases, APIs, and knowledge graphs. The retrieval layer coordinates these interactions. In agentic environments, RAG becomes the backbone of cross-system intelligence.
5. Competitive Advantage Depends on Precision
As foundational models commoditize, differentiation shifts to data orchestration and retrieval strategy. Enterprises that design precise, domain-aware RAG architectures will produce more accurate, explainable, and contextually grounded AI systems.
In practical terms, RAG architecture now influences:
- AI reliability
- Regulatory exposure
- Operational cost
- Time-to-decision
- Scalability across departments
For enterprise leaders, retrieval design is no longer a developer-level implementation detail. It is a strategic architectural decision that shapes long-term AI maturity.
Organizations that treat RAG as infrastructure build AI systems that are precise, governed, scalable, and economically viable. Those that do not risk deploying intelligent systems without structural integrity.
Strengthen your foundation with our offerings as AI strategy and road-mapping.
RAG Architecture Comparison: Which Model Fits Your Enterprise?
Enterprise leaders are no longer asking whether retrieval-augmented generation is necessary. The strategic question in 2026 is which RAG architecture aligns with operational complexity, governance requirements, and long-term AI strategy.
Different architectures optimize for different enterprise priorities:
- Speed and simplicity → Naive RAG
- Production reliability → Hybrid RAG
- Relationship-aware intelligence → Graph RAG
- Multi-step workflow automation → Agentic RAG
- Risk mitigation → Self-RAG
- Cost optimization → Adaptive RAG
- Enterprise scalability → Modular RAG
There is no universal “best” RAG architecture. The right choice depends on:
- Query complexity
- Data heterogeneity
- Regulatory sensitivity
- Cost tolerance
- Observability maturity
Selecting incorrectly leads to over-engineering or reliability gaps.
Enterprise Comparison Table
| Architecture | Retrieval Type | Complexity | Latency | Governance Risk | Best For | Production Readiness |
| Naive RAG | Vector Only | Low | Low | Medium | FAQs | High |
| Hybrid RAG | Vector + Keyword | Medium | Medium | Low | Enterprise Search | Very High |
| Graph RAG | Knowledge Graph | High | Medium-High | Low | Legal / R&D | Medium |
| Agentic RAG | Multi-step + Tools | Very High | Variable | High | Investigations | Emerging |
| Adaptive RAG | Dynamic Routing | Medium-High | Optimized | Medium | Cost-sensitive AI | High |
| Self-RAG | Reflective | High | Higher | Very Low | Regulated Domains | Emerging |
| Modular RAG | Composable | High | Flexible | Medium | Multi-domain Enterprise | High |
Key Criteria Enterprises Should Evaluate Before Selecting a RAG Architecture
Before implementing any RAG architecture, enterprises should evaluate five strategic dimensions.
1. Query Complexity
Are users asking single-fact lookup questions or multi-hop analytical queries?
2. Governance Sensitivity
Does the system operate in a regulated environment requiring explainability and audit logs?
3. Cost Sensitivity
Is cost per query tightly constrained, or is reasoning depth prioritized?
4. System Integration Requirements
Does retrieval require access to multiple systems such as SQL databases, APIs, or knowledge graphs?
5. Scalability Horizon
Will this system expand across departments or remain domain-specific?
Answering these questions prevents architectural mismatch.
Why Retrieval Is Now a Strategic Layer
Large language models now offer context windows exceeding one million tokens. At first glance, this appears to reduce the need for retrieval. In reality, it amplifies its importance.
Enterprise knowledge bases often exceed billions of tokens. Injecting raw data into context windows is:
- Computationally wasteful
- Governance risky
- Operationally imprecise
Strategic retrieval ensures only relevant, permission-compliant, high-quality knowledge enters generation.
According to research from Gartner, by 2026 over 70% of enterprise generative AI initiatives will require structured retrieval pipelines to mitigate hallucination and compliance risk. RAG architectures are no longer enhancements; they are safeguards.
For organizations shaping their broader AI roadmap, retrieval design must align with enterprise strategy — not just developer convenience. This principle is deeply connected to enterprise AI planning frameworks, as outlined in Techment’s guide on Enterprise AI Strategy in 2026
Naive RAG: The Foundational Architecture
Naive RAG is the simplest implementation of retrieval-augmented generation. It relies purely on vector embeddings and semantic similarity to retrieve top-k document chunks before generating responses.
How Naive RAG Works
- Queries and documents are embedded into dense vectors
- Cosine similarity identifies closest chunks
- Retrieved content is appended to prompts
- LLM generates response based on augmented context
This architecture remains the entry point for most enterprise RAG architectures.
Enterprise Strengths
Rapid Deployment
Organizations can deploy Naive RAG in days using vector databases such as Pinecone or Azure AI Search.
Reduced Hallucinations
By grounding outputs in enterprise documents, hallucination rates drop significantly.
Low Infrastructure Complexity
No graph traversal. No orchestration. Minimal ranking logic.
For enterprises exploring early-stage AI assistants, this approach is often aligned with modernization efforts such as those described in Techment’s Best Practices for Generative AI Implementation in Business.
Limitations of Naive RAG
Semantic Similarity ≠ True Relevance
Embedding proximity does not always correlate with answer quality.
No Multi-Hop Reasoning
It cannot connect facts across documents.
No Self-Correction
If retrieval fails, generation still proceeds confidently.
Enterprise Use Cases
- Internal documentation assistants
- HR policy bots
- Customer knowledge portals
- FAQ-style enterprise copilots
Naive RAG remains foundational — but insufficient for complex enterprise reasoning.
Graph RAG: Relationship-Aware Intelligence
Why Graph RAG Emerged
Vector similarity works well for chunk-level matching. But enterprises rarely operate at chunk-level granularity. They operate at relationship level:
- Case law precedents
- Supply chain dependencies
- Fraud transaction chains
- Research citation networks
Graph RAG introduces structured knowledge representation to RAG architectures.
How Graph RAG Works
- Entities and relationships extracted via LLMs
- Knowledge graph constructed
- Community detection creates semantic clusters
- Queries traverse relationship paths
- Generation synthesizes multi-hop findings
Enterprise Advantages
Multi-Hop Reasoning
Graph traversal enables reasoning across entity relationships.
Holistic Dataset Analysis
Identifies patterns invisible to flat vector search.
Improved Explainability
Graph paths provide traceable reasoning chains.
Trade-Offs
High Indexing Cost
Graph construction is computationally intensive.
Maintenance Complexity
Graphs require ongoing entity extraction updates.
Enterprise Use Cases
- Legal research platforms
- Pharmaceutical R&D knowledge graphs
- Compliance audit systems
- M&A due diligence intelligence
Organizations modernizing their data architecture must consider how graph-driven RAG architectures integrate with broader data fabric initiatives such as Microsoft Fabric deployments. Techment’s perspective on modern analytics foundations provides additional context in Microsoft Data Fabric vs Traditional Data Warehousing.
Graph RAG is not for every enterprise. But for relationship-intensive domains, it becomes transformative.
Hybrid RAG: The Enterprise Production Standard
The Rise of Hybrid RAG Architectures
In real-world enterprise systems, queries are messy:
- “Find revenue recognition policy for IFRS 15”
- “Explain customer churn modeling approach”
- “Show me SLA terms in contract 2022-AC-455”
Some require semantic understanding. Others require exact keyword matching.
Hybrid RAG architectures combine:
- Vector search (semantic understanding)
- Lexical search (BM25/TF-IDF)
- Optional graph traversal
How Hybrid RAG Works
- Parallel retrieval using vector + keyword search
- Merge and re-rank results
- Provide enriched context to LLM
- Generate grounded response
Enterprise Benefits
Reduced False Negatives
Exact term queries are captured.
Reduced False Positives
Semantic drift minimized.
Higher Recall & Precision
Studies show hybrid retrieval consistently outperforms single methods.
Hybrid RAG is rapidly becoming the enterprise default because it balances reliability and flexibility.
Infrastructure Implications
Hybrid RAG architectures require:
- Vector databases
- Search engines
- Ranking logic
- Monitoring pipelines
While complexity increases, so does reliability.
Enterprises deploying hybrid retrieval must ensure data quality foundations are robust. Retrieval quality is only as strong as the underlying data discipline. Techment’s blueprint on Data Quality for AI in 2026 offers critical insight into this alignment.
Use Cases
- Enterprise search platforms
- Regulatory reporting assistants
- IT operations knowledge systems
- Technical documentation copilots
Hybrid RAG is not experimental. It is production-grade.
Hybrid vs Vector-Only RAG: Production Reliability Differences
Vector-only RAG performs semantic similarity matching using embeddings. While fast to deploy, it often struggles with:
- Exact keyword compliance requirements
- Structured document references
- Policy numbers and contract identifiers
Hybrid RAG combines:
- Semantic search (vector embeddings)
- Lexical search (keyword matching such as BM25)
This significantly improves recall and precision.
In enterprise production systems, Hybrid RAG consistently outperforms vector-only approaches because it captures both semantic meaning and exact terminology — a critical distinction in legal, financial, and regulatory domains.
When Graph RAG Outperforms Hybrid RAG in Enterprise Workloads
Hybrid RAG improves document retrieval. Graph RAG transforms reasoning.
Graph-based architectures outperform hybrid systems when:
- Insights depend on relationships between entities
- Multi-hop reasoning is required
- Context spans multiple interconnected records
Examples include:
- Fraud detection tracing ownership networks
- Legal precedent analysis
- Supply chain risk assessment
- M&A due diligence
If the question requires understanding how entities relate — not just retrieving relevant text — Graph RAG becomes strategically necessary.
Contextual RAG: Preserving Meaning Across Chunks
The Chunking Problem in RAG Architectures
Traditional chunking splits documents arbitrarily. This breaks:
- Pronoun references
- Section continuity
- Contextual nuance
Contextual RAG enhances each chunk with document-level metadata.
How Contextual RAG Works
- Analyze document structure
- Attach section headers and positional context
- Enrich embeddings with semantic role
- Retrieve context-aware chunks
Enterprise Impact
Improved Disambiguation
Prevents misinterpretation of references.
Better Long-Form Document Handling
Critical for regulatory, medical, and legal documents.
Reduced Context Drift
Organizations operating in regulated sectors — healthcare, finance, government — benefit significantly from contextual RAG architectures.
Context precision must align with governance strategy. Enterprises building AI under compliance mandates should align retrieval pipelines with broader governance initiatives such as those described in Data Governance for Data Quality.
Adaptive RAG: Matching Strategy to Query Complexity
Why Static Pipelines Fail at Scale
Enterprise queries are heterogeneous:
- “What is our refund policy?”
- “Analyze revenue impact of contract changes across regions.”
Treating both queries equally wastes resources.
Adaptive RAG dynamically selects retrieval depth based on query classification.
How Adaptive RAG Works
- Classify query complexity
- Route simple queries to fast retrieval
- Route complex queries to multi-step pipelines
- Optimize latency and cost
Enterprise Benefits
Cost Optimization
Avoids over-processing simple queries.
Latency Control
Fast answers for operational questions.
Strategic Depth for Complex Tasks
Adaptive RAG architectures align directly with cost-governance frameworks — a growing concern for enterprises scaling generative AI workloads.
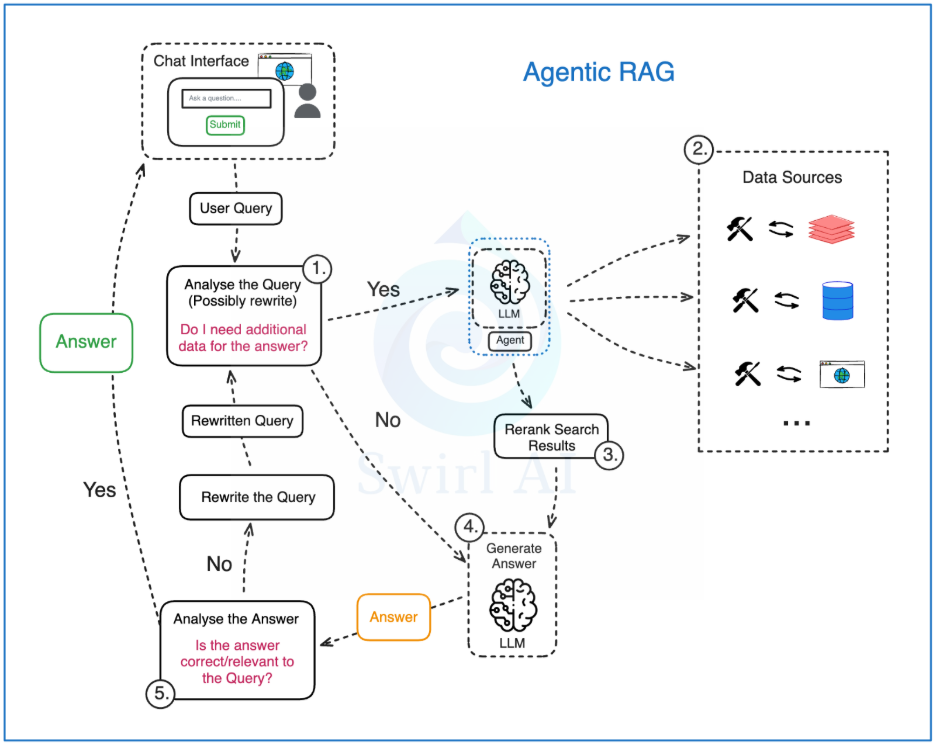
Agentic RAG: From Retrieval to Autonomous Reasoning
Why Agentic RAG Architectures Are Emerging
Traditional RAG architectures retrieve context and generate responses. Agentic RAG goes further — it reasons, plans, acts, evaluates, and refines.
As enterprise AI moves toward autonomous systems, retrieval must support:
- Multi-step workflows
- Tool invocation
- Cross-system data access
- Iterative reasoning
- Memory persistence
Agentic RAG transforms retrieval from a passive lookup mechanism into an active cognitive layer.
How Agentic RAG Works
Task Decomposition
An orchestrator (often using ReAct or Chain-of-Thought prompting) breaks complex requests into steps.
Tool Invocation
Agents query vector databases, SQL systems, APIs, cloud storage, or graph databases.
Memory Systems
Short-term memory tracks current workflow state. Long-term memory stores historical knowledge and prior results.
Iterative Refinement
The system evaluates intermediate outputs and refines queries until acceptable confidence thresholds are reached.
Enterprise Advantages
Cross-System Intelligence
Instead of retrieving from one knowledge base, Agentic RAG can:
- Query CRM systems
- Retrieve support tickets
- Access financial databases
- Cross-reference policy documents
Autonomous Research
Ideal for strategic decision support, fraud investigation, compliance reviews, and root-cause analysis.
Higher Accuracy in Complex Scenarios
Multi-step reasoning significantly improves analytical quality.
Governance, Security, and Compliance Considerations Across RAG Architectures
Governance maturity determines architectural feasibility.
Enterprise RAG systems must integrate:
- Role-based access control (RBAC)
- Data lineage tracking
- Retrieval logging
- Version control
- PII redaction mechanisms
- Model output auditing
Architectures differ in governance exposure:
- Naive RAG: Moderate risk
- Hybrid RAG: Lower risk with structured filtering
- Agentic RAG: Higher governance exposure due to autonomous tool usage
- Self-RAG: Strong reliability but higher complexity
Without governance alignment, even technically strong architectures fail in production.
Enterprise Use Cases
- Multi-source financial analysis
- Incident investigation platforms
- Enterprise copilots with workflow automation
- Autonomous compliance auditing
Agentic RAG is powerful — but it is not a default choice. It is strategic infrastructure.
Why Self-RAG Matters for Enterprise Reliability
One of the persistent criticisms of generative AI is overconfidence. Standard RAG architectures retrieve context and generate answers without validating factual alignment.
Self-RAG introduces reflection mechanisms that evaluate retrieval quality and generation accuracy before delivering responses.
How Self-RAG Works
Adaptive Retrieval Decisions
The system determines whether retrieval is needed or if parametric knowledge suffices.
Relevance Evaluation
Retrieved documents are assessed before generation proceeds.
Generation with Self-Assessment
The model produces both answers and confidence signals.
Iterative Correction
If confidence is low, additional retrieval or regeneration occurs.
Enterprise Value
Reduced Hallucinations
Self-evaluation reduces unsupported claims.
Confidence Scoring
Supports explainability and trust in high-stakes environments.
Cost Optimization
Retrieval is invoked only when necessary.
For industries like healthcare, legal services, and financial institutions, Self-RAG architectures align directly with risk mitigation requirements.
Limitations
- Requires specialized training
- Increased computational overhead
- More complex monitoring requirements
Self-RAG is particularly suited for:
- Medical AI copilots
- Legal research systems
- Investment advisory platforms
When combined with strong data quality frameworks — such as those outlined in Data Quality for AI in 2026.
Modular RAG: Designing for Evolution
The Problem of Static Architectures
Enterprise AI systems are not static. Embedding models change. LLMs evolve. Retrieval strategies improve.
Monolithic RAG architectures become obsolete quickly.
Modular RAG treats retrieval, indexing, generation, and orchestration as composable building blocks.
How Modular RAG Works
Independent Indexing Modules
Chunking, metadata extraction, and embedding pipelines operate independently.
Pluggable Retrieval Modules
Vector search, keyword search, graph traversal, and SQL retrieval are interchangeable.
Flexible Generation Layer
LLMs can be upgraded without altering indexing systems.
Central Orchestration
Coordinates data flow between modules.
Enterprise Advantages
Future-Proofing
Swap embedding models without re-architecting systems.
Experimentation at Scale
A/B test retrieval strategies in production.
Multi-Use Case Support
Different departments can use distinct retrieval strategies within one unified platform.
Modular RAG architectures are particularly aligned with enterprises deploying unified analytics platforms such as Microsoft Fabric, where composability is core to platform philosophy. For a deeper architectural perspective, see Techment’s Microsoft Fabric Architecture: CTO’s Guide.
Trade-Offs
- Higher engineering investment
- Interface management complexity
- Governance coordination across modules
Modular RAG is ideal for enterprises scaling AI across multiple domains.
Agentic Graph RAG: Strategic Graph Exploration at Scale
The Convergence of Three Paradigms
Agentic Graph RAG combines:
- Autonomous agents
- Knowledge graphs
- Retrieval augmentation
Instead of statically traversing graphs, agents dynamically decide:
- Which entities to explore
- Which paths to prioritize
- When to backtrack
- When to synthesize
How Agentic Graph RAG Works
Strategic Planning
Agent analyzes query intent and constructs exploration strategy.
Dynamic Graph Traversal
Multi-hop reasoning across entity networks.
Iterative Evaluation
Intermediate findings guide further exploration.
Synthesis and Validation
Information aggregated across graph paths before response generation.
Enterprise Use Cases
- Fraud detection following ownership chains
- Supply chain risk analysis
- National security intelligence
- Complex litigation research
Limitations
- High computational cost
- Sophisticated orchestration requirements
- Challenging observability and debugging
Agentic Graph RAG architectures are currently best suited for high-value investigative systems where reasoning depth justifies cost.
Enterprise Implementation Blueprint for RAG Architectures
Selecting RAG architectures is not purely technical. It is organizational.
Step 1: Classify Use Case Complexity
- Simple retrieval → Naive or Hybrid RAG
- Relationship-heavy reasoning → Graph RAG
- Multi-step workflows → Agentic RAG
- Risk-sensitive domain → Self-RAG
- Multi-domain scalability → Modular RAG
Step 2: Align With Data Governance
Strong governance frameworks are mandatory.
Enterprises must integrate:
- Role-based access controls
- Data lineage tracking
- Audit logs
- Version control
Governance maturity directly influences RAG architecture selection.
Step 3: Define Cost Governance
Adaptive RAG and Hybrid RAG often offer optimal balance between performance and cost.
Step 4: Design Observability Frameworks
Monitor:
- Retrieval precision
- Hallucination rates
- Latency
- Cost per query
- Confidence scores
Without observability, enterprise AI systems degrade silently.
How Techment Helps Enterprises Design RAG Architectures
Enterprise RAG architectures demand more than technical implementation. They require strategic alignment across data, governance, cloud infrastructure, and AI readiness.
Techment supports enterprises through:
AI Strategy & Architecture Alignment
We help organizations define:
- Which RAG architecture fits their maturity
- How retrieval aligns with enterprise AI strategy
- Governance models supporting AI deployment
See how insights become decisions in Enterprise Data Quality Framework: Best Practices for Reliable Analytics and AI
Data Modernization for Retrieval Readiness
RAG architectures fail without high-quality, structured data.
Techment enables:
- Data discovery and transformation
- Metadata enrichment
- Governance automation
- Fabric-based analytics modernization
Organizations modernizing toward AI-ready data foundations often leverage insights from AI-Ready Enterprise Checklist.
Microsoft Fabric & Azure Integration
We design unified architectures integrating:
- Microsoft Fabric
- Azure AI services
- Purview governance
- Enterprise data lakes
This ensures retrieval pipelines operate within secure, compliant ecosystems.
End-to-End Implementation
From roadmap design to deployment and optimization, Techment delivers:
- Hybrid and Adaptive RAG systems
- Agentic workflow automation
- Graph-enabled intelligence platforms
- Observability and evaluation frameworks
Our role is consultative — not transactional.
We enable enterprises to deploy RAG architectures strategically, not experimentally.
The 2026–2027 Trajectory of RAG Architectures
The future is not about replacing RAG with larger context windows.
It is about precision retrieval at scale.
As context windows expand, targeted retrieval becomes more valuable — not less.
Enterprise AI will move toward:
- Hybrid baselines
- Adaptive cost-aware pipelines
- Agentic orchestration for complex workflows
- Self-correcting reliability layers
- Composable modular ecosystems
RAG architectures are evolving from retrieval utilities to enterprise intelligence frameworks.
Enterprise RAG Implementation Timeline and Resource Requirements
Implementation duration varies significantly by architecture.
Hybrid RAG
4–8 weeks
Requires:
- Data engineering
- Vector database setup
- Search integration
- Monitoring pipeline
Graph RAG
3–6 months
Requires:
- Entity extraction pipeline
- Knowledge graph construction
- Maintenance workflows
Agentic RAG
3–9 months
Requires:
- Orchestration framework
- Tool connectors
- Identity management
- Observability layer
Complex architectures require cross-functional collaboration between:
- Data engineers
- Cloud architects
- AI engineers
- Governance teams
Underestimating organizational readiness is a common failure point.
Monitoring, Evaluation, and Observability for Enterprise RAG Systems
Enterprise RAG systems must be measurable.
Critical metrics include:
- Retrieval precision and recall
- Hallucination rate
- Latency per query
- Cost per request
- Confidence scoring
- Drift detection
Without observability, RAG systems degrade silently as data evolves.
Continuous evaluation ensures reliability, especially in regulated industries.
Lay the groundwork for AI readiness, identify ROI-positive use cases, and build a prioritized execution roadmap designed for value, feasibility, and governance with our AI services.
Conclusion: Choosing the Right RAG Architecture Is a Strategic Decision
RAG architectures in 2026 are no longer interchangeable patterns.
They represent a spectrum:
- From Naive and Hybrid RAG for foundational enterprise use
- To Graph and Agentic systems for deep reasoning
- To Adaptive and Self-RAG for cost-aware and risk-sensitive environments
The most successful enterprises will not chase architectural complexity for its own sake.
They will align RAG architecture choice with:
- Business objectives
- Governance maturity
- Risk tolerance
- Data quality readiness
- Cost discipline
RAG architectures are now core enterprise infrastructure — not experimental AI add-ons.
Organizations that approach retrieval strategically will build AI systems that are accurate, explainable, scalable, and economically sustainable.
Techment partners with enterprises to design and implement the right RAG architectures for long-term AI success.
FAQs
1. Which RAG architecture should most enterprises start with?
Hybrid RAG is the production baseline for most enterprises in 2026. It balances accuracy, cost, and governance. More complex architectures like Graph or Agentic RAG are used only when reasoning depth requires them.
2.How does hybrid RAG differ from graph RAG?
Hybrid RAG combines vector and keyword search to improve document retrieval accuracy. Graph RAG adds a knowledge graph layer to enable multi-hop, relationship-based reasoning across connected data.
3. Is agentic RAG necessary for enterprise production systems?
No. Agentic RAG is only necessary for complex, multi-step workflows that require tool orchestration or cross-system reasoning. Most enterprise search use cases perform well with Hybrid RAG.
4. Can large context windows replace retrieval-augmented generation?
No. Large context windows increase cost and governance risk. RAG remains essential for precise, permission-aware, and cost-controlled enterprise AI systems.
5. How much does enterprise RAG implementation cost?
Costs vary by architecture. Hybrid RAG is moderate and deployable in weeks. Graph and Agentic RAG require higher investment, longer timelines, and greater infrastructure maturity.
Related Reads
- Microsoft Fabric Architecture: A CTO’s Guide to Modern Analytics & AI
- Fabric AI Readiness: How to Prepare Your Data for Scalable AI Adoption
- Data Quality for AI in 2026: The Ultimate Enterprise Guide
- Enterprise AI Strategy in 2026: What Leaders Must Get Right
- How to Assess Data Quality Maturity: Your Enterprise Roadmap
- Data Migration
- Data Transformation
- Data Pipeline Engineering
- Data Cleansing & Cataloging
- Data Governance & Quality
- Visualization and Analytics




