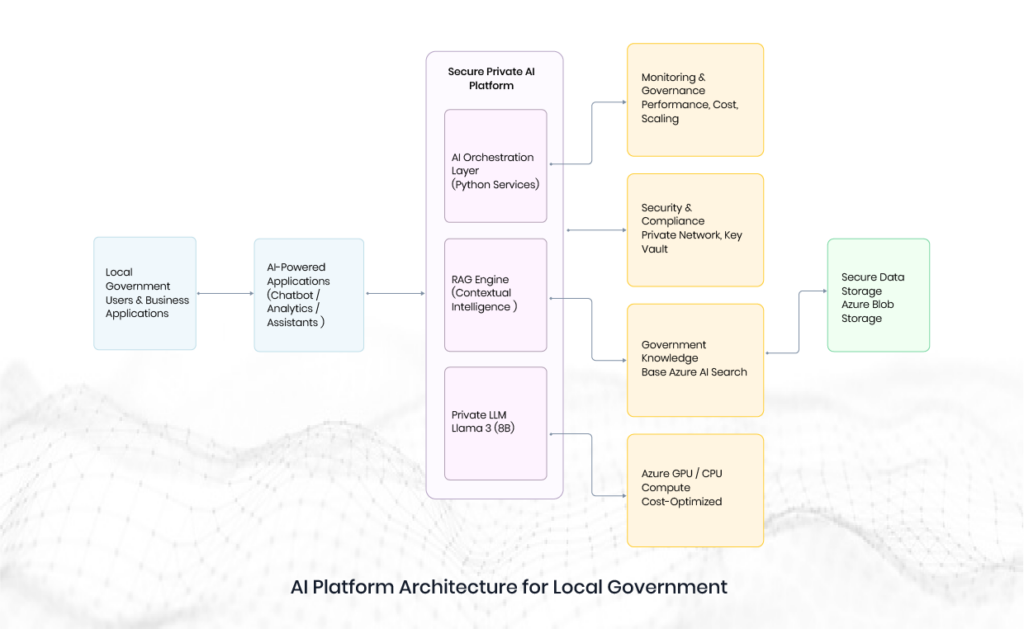
Techment partnered with Microsoft Azure teams to provision GPU-enabled infrastructure and deploy the Llama 3 (8B) model in a secure environment. The client’s knowledge base was integrated into a RAG pipeline, resulting in a functional prototype chatbot. Our team developed Python-based code to process queries, record response times, and benchmark CPU vs GPU workloads. This approach provided actionable insights into performance trade-offs, scalability considerations, and cost optimization. Additionally, we delivered a deployment blueprint covering hosting strategies, security safeguards, provisioning guides, and agent-based AI integration. The POC was successfully completed in 8 weeks, with a $10,000 execution cost and an estimated $4,200 monthly GPU infrastructure cost for ongoing workloads.