Modern enterprises rely on machine learning (ML) models to drive predictions, automation, and personalization. Yet even the most powerful model will fail if its data is inaccurate or inconsistent. Building a data quality framework for machine learning pipelines is not just good practice — it’s a foundation for model reliability, trust, and ROI.
TL;DR — Key Takeaways
- Bad data causes bias, drift, and degraded model performance.
- A Data Quality (DQ) framework ensures ongoing reliability beyond generic data governance.
- Effective frameworks address both classical and ML-specific data quality dimensions.
- Automation, monitoring, and rule versioning prevent quality decay as pipelines scale.
- Continuous improvement and stakeholder alignment drive long-term success.
Related Read: Why Data Integrity Is Critical Across Industries
The Risk of Bad Data in ML
Small data flaws can derail machine learning (ML) models. Poor-quality data is one of the leading causes of model failure — not just technically, but operationally and ethically. According to research from Gartner and McKinsey, over 80% of AI project failures are linked to weak data quality and governance practices. The implications of bad data ripple across model performance, business trust, and regulatory compliance. Let’s examine the key dimensions of this risk.
Bias: The Hidden Distortion in Training Data
When training data disproportionately represents certain demographics or segments, ML models learn skewed patterns that lead to biased and unfair outcomes. For instance, a loan approval model trained predominantly on data from one income bracket may systematically disadvantage other groups. Bias not only erodes model accuracy but also poses ethical and reputational risks for organizations. Ensuring balanced datasets, applying fairness metrics, and conducting bias audits are essential to maintaining model integrity.
Drift: When Reality Changes, Models Falter
Data drift occurs when the statistical properties of features or target variables shift over time — a natural outcome of dynamic real-world environments. For example, changes in consumer behavior, economic conditions, or market trends can cause concept drift, leading to performance decay. Without robust drift detection mechanisms, models can continue making predictions that are no longer valid. Continuous monitoring and automated retraining pipelines help mitigate this degradation and keep models aligned with current realities.
Skew: Misalignment Between Training and Production
Data skew arises when the distribution of input features differs between training and production environments. A model trained on clean, curated datasets may underperform in production where noisy or incomplete data is more common. This mismatch leads to unstable model predictions and wastes retraining cycles. Establishing data versioning, environment parity, and automated validation checks between stages of the ML pipeline can reduce the risk of skew.
Operational Impacts of Poor Data Quality
- Data Pipeline Breakdowns: Even small upstream data errors — such as malformed records or missing fields — can propagate through analytics dashboards, leading to flawed business decisions.
- Costly Retraining: ML teams often spend excessive time debugging model issues that stem from unreliable data sources rather than algorithmic flaws.
- Loss of Trust: When stakeholders observe inconsistent or inexplicable AI outputs, confidence in machine learning systems diminishes, delaying adoption and investment.
- Compliance Risks: In sectors like finance, healthcare, and insurance, biased or erroneous data can trigger regulatory breaches, penalties, or legal action.
In short, data quality is not just a technical concern — it’s a strategic imperative. Building a robust data quality framework ensures that AI and ML systems remain accurate, fair, and reliable as they evolve with the business landscape.
External sources such as Gartner and McKinsey emphasize that over 80% of AI project failures trace back to poor data quality and governance.
Why a DQ Framework Is More Than Data Governance
Traditional data governance frameworks play a crucial role in defining data lineage, access control, and policy enforcement. However, when it comes to machine learning (ML) pipelines, governance alone isn’t enough. ML systems demand a dynamic, continuous, and intelligent approach to ensure that data feeding the models remains consistent, reliable, and bias-free throughout its lifecycle. Let’s break down how a Data Quality (DQ) Framework extends beyond conventional governance.
1. Generic Governance vs. ML-Specific Needs
Data governance ensures that data is properly cataloged, secured, and compliant. Yet ML models rely on data integrity at the feature and label level, not just metadata or access rules. A DQ framework introduces domain-specific checks, such as validating training labels, ensuring balanced class distributions, and monitoring feature transformations. These steps directly affect model accuracy and fairness—dimensions governance alone cannot handle.
2. Periodic Audits vs. Continuous, Real-Time Validation
Governance frameworks typically depend on scheduled audits or reviews to assess compliance and data health. But ML pipelines are highly dynamic, ingesting data continuously from multiple sources. A robust DQ framework incorporates real-time validation, automatically flagging anomalies or missing values as they occur. This proactive mechanism prevents degraded inputs from corrupting model performance downstream.
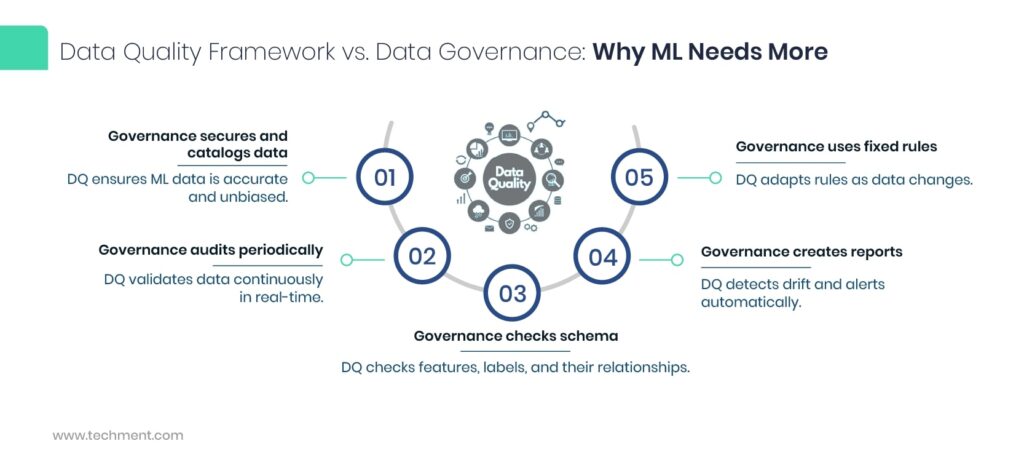
3. Schema & Policy Focus vs. Feature- and Label-Level Checks
While governance frameworks center on schemas, formats, and access policies, they seldom inspect the semantic layers critical to ML. A DQ framework dives deeper — validating feature consistency, label accuracy, and inter-feature correlations. This ensures that models aren’t training on erroneous or misaligned data, reducing the risk of bias and overfitting.
4. Static Thresholds vs. Adaptive, Data-Driven Rules
Governance rules often rely on static thresholds (e.g., acceptable ranges for null values or outliers). In contrast, ML-driven DQ frameworks employ adaptive rules that evolve with the data. These rules can leverage statistical baselines or model-derived expectations to automatically adjust quality thresholds, enabling context-aware validation across changing datasets.
5. Manual Reports vs. Automated Drift Detection & Alerts
Traditional governance produces manual reports summarizing compliance or data usage. In ML, this approach is too slow. A DQ framework integrates automated drift detection, tracking shifts in feature distributions, target labels, or input patterns. When drift is detected, real-time alerts enable teams to retrain models or adjust data pipelines before performance degrades.
In essence, while governance ensures data control, a DQ framework ensures data fitness for ML — turning passive oversight into active, intelligent quality assurance that sustains reliable AI outcomes.
ML systems evolve fast; data changes daily. Hence, your data quality framework must integrate with MLOps pipelines, handle schema drift, and provide versioned, testable rules.
Explore More: Data Quality Framework for AI and Analytics
Core Dimensions of Data Quality in ML
Ensuring high-quality data is the foundation of reliable and scalable AI/ML pipelines. The effectiveness of a model depends not just on the volume of data, but on its accuracy, completeness, consistency, timeliness, uniqueness, and validity. Each of these dimensions plays a pivotal role in determining how well models generalize, adapt, and perform in real-world scenarios.
1. Accuracy
Accuracy measures how closely data values reflect the real-world entities or events they represent. In machine learning, inaccurate data — such as mislabeled samples or erroneous feature values — introduces bias and noise, leading to poor model generalization. For instance, if a fraud detection model is trained on mislabeled transactions, it may either under-predict or over-predict fraudulent activities. Implementing validation checks, domain-driven labeling reviews, and anomaly detection mechanisms can help ensure accuracy throughout the data lifecycle.
2. Completeness
Completeness refers to the extent to which all required data is available for training and inference. Missing values, absent labels, or incomplete feature sets can severely degrade model performance and stability. For example, missing user demographics in a personalization model may lead to skewed recommendations. Techniques such as imputation, synthetic data generation, or enforcing mandatory data capture fields help address completeness issues. Moreover, data profiling and pipeline observability tools can automatically flag incomplete records before they reach production.
3. Consistency
Consistency ensures that data remains uniform across different sources, systems, and timeframes. Inconsistencies — like mixed measurement units, varied feature definitions, or conflicting categorical encodings — can cause silent model failures. For example, temperature data recorded in both Celsius and Fahrenheit without standardization could drastically distort feature scaling. Establishing master data management (MDM) policies, schema enforcement, and feature store governance helps maintain consistency across ML datasets.
4. Timeliness
Timeliness emphasizes the importance of data freshness. In dynamic environments such as demand forecasting or fraud detection, outdated data can lead to inaccurate predictions. ML pipelines must adhere to data freshness SLAs (Service Level Agreements) that define acceptable data latency. Using streaming architectures, event-driven ETL pipelines, and real-time validation layers ensures that models are trained and updated with the most current information.
5. Uniqueness
Uniqueness guarantees that each data entity appears only once within the dataset. Duplicate entries inflate the representation of certain patterns, biasing training outcomes and distorting evaluation metrics. For example, duplicate customer records in churn prediction could cause the model to overfit on specific user behaviors. Deduplication rules, hash-based indexing, and record linkage techniques are essential for maintaining dataset uniqueness, especially when merging data from multiple systems.
6. Validity
Validity ensures that data conforms to defined business rules, formats, and domain constraints. Invalid entries — such as negative ages, incorrect date formats, or values outside permissible ranges — can cause feature drift or model instability. Validation layers, schema registries, and automated data quality checks can enforce validity throughout the data pipeline. Establishing domain-specific validation rules at the data ingestion stage helps detect and reject invalid records before they affect model outcomes.
In essence, a robust data quality framework must operationalize these six dimensions across all ML stages — from ingestion to deployment. By embedding data validation, monitoring, and governance into the pipeline, organizations can ensure their AI models remain accurate, reliable, and explainable.
Additional ML-Specific Dimensions
- Label Noise & Quality
- Class Balance / Distribution
- Feature & Concept Drift
- Correlation Shifts
- Outlier & Anomaly Patterns
These aspects extend the traditional DQ lens into the ML lifecycle, enabling proactive detection before models degrade.
Architectural Layers of a DQ Framework
A resilient data quality framework for machine learning pipelines has five architectural layers:
- Ingestion & Pre-Validation
Schema checks, null thresholds, and sanity filters at data entry. - Profiling & Baseline Measurement
Statistical summaries (mean, variance, quantiles) establish reference distributions. - Validation & Anomaly Detection
Static rules and adaptive algorithms detect data or drift anomalies. - Remediation / Correction
Automatic imputation, clipping, or routing to data stewards. - Monitoring & Drift Detection
Continuous KPI tracking with dashboards and alerts.
Ingestion Layer Example
- Validate schema with tools like Great Expectations or Deequ.
- Reject malformed batches exceeding missing thresholds.
- Quarantine suspicious records for human review.
Profiling & Baseline Layer
- Compute descriptive statistics on historical windows.
- Compare current vs. baseline distributions using metrics like PSI or KS-test.
- Store results in a metadata repository for version control.
Validation & Anomaly Detection
- Apply both static rules and dynamic thresholds (±3σ deviations).
- Use isolation forests or autoencoders for multivariate anomaly detection.
- Trigger alerts for persistent deviation beyond tolerance.
Remediation Layer
- Impute missing data via median or predictive imputation.
- Correct outliers and synchronize with trusted reference sources.
- Record every modification for auditability.
Monitoring & Drift Detection
- Detect input or target drift continuously.
- Measure acceptance rates and alert trends.
- Integrate with observability dashboards (Grafana, Power BI).
- Link severe drift events to model retraining triggers.
Internal Insight: See how Techment helps clients streamline pipelines in this case study.
Designing Data Quality Rules: Static vs Dynamic
Static Rules
- Fixed logic, e.g. age ≤ 120.
- Ideal for structural or regulatory constraints.
Dynamic Rules
- Evolving thresholds based on data statistics, e.g. “value within ±3σ of rolling mean.”
- Automatically adapts to seasonal or behavioral trends.
Calibration Tips
- Begin with conservative thresholds.
- Use historical baselines to refine rules.
- Implement shadow-mode testing before enforcement.
- Log all rule hits for continual learning.
External Resource: Hevo Data offers practical guides on adaptive rule calibration and pipeline observability.
Versioning, Testing & Evolution
Version Control
- Store rule definitions (YAML/JSON) in Git with commit history.
- Tag releases per model or dataset version.
- Include metadata: author, change reason, severity.
A/B Testing Rules
- Deploy rule changes in shadow mode to measure false-positive rates.
- Analyze acceptance vs. rejection trends before rollout.
Rollback & Feedback
- Enable instant rollback to previous versions.
- Collect user feedback on flagged records.
- Regularly retire obsolete or redundant rules.
Tooling & Ecosystem Options
- Open-Source
- Great Expectations – simple declarative rules & data docs.
- Deequ – Spark-based scalable validation.
- TensorFlow Data Validation (TFDV) – built for ML pipelines.
- Evidently AI – drift and performance monitoring.
- Apache Griffin / Soda Core – flexible rule-based checks.
- Commercial Platforms
- Monte Carlo – end-to-end data observability.
- Bigeye, Datafold, Alation, Collibra, Informatica – governance + quality integration.
Feature-store platforms like Tecton include validation hooks.
Integration Tips
- Mix open-source for validation and commercial for observability.
- Ensure low-latency checks for streaming data.
- Integrate with orchestration (Airflow, Dagster) and lineage tools (OpenLineage, DataHub).
Related Resource: Data Management for Enterprises Roadmap
Monitoring, Alerts & KPIs
Once your data quality framework is deployed, continuous monitoring ensures ongoing reliability and transparency.
Key Data Quality Metrics
- Error / Rule Violation Rate – % of records failing validation.
- Admission Rate – % of data accepted vs. quarantined.
- Drift Detection Score – PSI or KS-test values per feature.
- Latency Impact – Time overhead per validation stage.
- Data SLA Breach Count – How often data arrival or validation misses SLAs.
- Anomaly Volume – Frequency of statistical outliers detected.
- Model Degradation Correlation – Link between data anomalies and model accuracy drops.
Alerting & Dashboards
- Implement live dashboards in Grafana or Power BI.
- Use heatmaps to visualize feature-level rule violations.
- Time-series graphs reveal drift or anomaly trends.
- Configure tiered alerts — “Warning” for minor deviations, “Critical” for high-impact breaches.
- Automate notifications via Slack, PagerDuty, or email for rapid response.
SLA & Escalation Practices
- Define who owns each data domain and response timeline.
- Create escalation tiers for unresolved quality incidents.
- Schedule monthly reviews to adjust thresholds based on trends.
Case Example: See how Techment improved real-time alerting in this payment gateway testing optimization case study.
Scaling Considerations & Pitfalls
Scaling a data quality framework for machine learning pipelines introduces new challenges in performance, coordination, and governance.
- High-Throughput or Streaming Data
- Embed lightweight validations in Kafka or Flink streams.
- Use windowed sampling to monitor trends without bottlenecking throughput.
- Apply approximate quantile and frequency sketches for efficiency.
- Schema Evolution
- Use schema registries (e.g., Avro or Protobuf) to manage field evolution.
- Version schema changes and automatically update dependent rules.
- Add new features in monitor-only mode before enforcing rules.
- Multi-Team Collaboration
- Centralize reusable rule templates across teams.
- Establish a “Data Quality Council” to review rules quarterly.
- Encourage internal data maturity assessments for ownership accountability.
- Common Pitfalls in Data Quality Frameworks — and How to Avoid Them
Even well-designed data quality frameworks can fail if not carefully implemented and maintained. Below are five common pitfalls that often undermine data reliability in AI/ML pipelines, along with proven prevention strategies to mitigate them.
1. Overblocking Valid Data — Calibrate Thresholds Using Historical Data
One of the most frequent mistakes in automated data validation is setting thresholds too aggressively, which can lead to overblocking legitimate data. For example, a model input check might reject slightly anomalous but still valid values, reducing the dataset’s diversity and biasing model training.
Prevention Strategy: Calibrate your rules using historical data distributions. Analyze previous anomalies and genuine data variations to fine-tune detection thresholds. Incorporate adaptive techniques that adjust dynamically based on data seasonality or drift patterns. This ensures that the framework remains sensitive enough to catch true issues without rejecting valid entries.
2. Untracked Rule Changes — Maintain Git Versioning and Change Logs
As data quality rules evolve, lack of version control can make it nearly impossible to trace when and why a rule was modified. This leads to inconsistent results and challenges in auditing.
Prevention Strategy: Implement Git-based versioning for all validation rules, transformations, and configurations. Maintain detailed change logs describing the reason, author, and impact of each modification. This not only strengthens governance but also supports reproducibility and collaboration across data teams.
3. Latency Overhead — Separate Heavy Checks into Async Pipelines
Running computationally intensive quality checks (e.g., outlier detection, schema validation) in real-time pipelines can introduce latency that slows downstream processes.
Prevention Strategy: Classify your checks into synchronous (light) and asynchronous (heavy) categories. Perform essential validations inline (e.g., null checks), while offloading resource-heavy ones to asynchronous pipelines or scheduled batch jobs. This ensures low-latency operations while maintaining comprehensive quality coverage.
4. Ignoring Feedback — Capture False Positives for Tuning
Data quality systems often generate false positives, which can frustrate teams if not addressed. Over time, ignoring user feedback leads to alert fatigue and reduced trust in the framework.
Prevention Strategy: Build mechanisms to capture and tag false positives. Create feedback loops where users can mark erroneous alerts, and feed this data back into rule-tuning and model retraining processes. This continuous improvement cycle enhances precision and ensures long-term reliability.
5. Isolated Systems — Integrate with Data Lineage and Governance Tools
Data quality solutions that operate in isolation fail to provide context about upstream or downstream dependencies, making root cause analysis difficult.
Prevention Strategy: Integrate your framework with data lineage and governance platforms (e.g., Collibra, Alation, or open-source alternatives). This integration connects quality issues to their source systems, datasets, and business processes, enabling more effective troubleshooting and compliance managemen
Recommended Read: Unleashing the Power of Data – Techment Whitepaper
Strategic Recommendations
To operationalize data quality for ML success:
- Embed DQ in MLOps: Integrate validation in CI/CD pipelines.
- Automate Drift Detection: Use statistical & ML-based drift tests continuously.
- Centralize Rules: Manage reusable validation libraries per domain.
- Adopt Incremental Maturity: Start with baseline checks; evolve toward adaptive validation.
- Measure Business Impact: Link DQ metrics to downstream KPIs like conversion, churn, or risk score accuracy.
- Promote Data Literacy: Train engineers and analysts to interpret drift and anomaly metrics.
- Benchmark Regularly: Use a data quality maturity model to assess progress quarterly.
Explore Related Case Study: Streamlining Operations with Reporting Automation
Data & Stats Snapshot
FAQ: Data Quality in ML Pipelines
- What’s the difference between data quality and data governance?
Governance sets the policies; data quality enforces them with technical checks, rules, and monitoring. - How often should I review data quality rules?
Every 3–6 months or after major model retrains. Adapt thresholds as data distributions shift. - Which tools are best for ML-specific DQ?
Start with TFDV for profiling and Great Expectations for validation. Combine with Evidently AI for drift visualization. - How do I correlate data quality with model performance?
Track data drift metrics (PSI, KS) against model accuracy (AUC, F1). Use dashboards to visualize correlation. - Can a DQ framework be automated?
Yes — automation via MLOps CI/CD pipelines enables self-healing data processes and minimal manual review.
Conclusion & Next Steps
A well-designed data quality framework for machine learning pipelines transforms reactive firefighting into proactive reliability management. It ensures trust, consistency, and scalability across your data-driven ecosystem.
Next Steps / Implementation Checklist
Want to evaluate your data maturity? Talk to our data experts to build a custom Data Quality Framework.
Related Reads
- Why Data Integrity Is Critical Across Industries
- Data Management for Enterprises Roadmap
- Data Integrity: The Backbone of Business Success
- How Techment Transforms Insights into Actionable Decisions Through Data Visualization?
- Top 5 Technology Trends in Cloud Data Warehouse in 2022
- Data Quality Framework for AI and Analytics



