
Join our Partner Rewards Program and reap
exclusive benefits for every successful
client
referral
In today’s era, organizations generate unprecedented volumes of data daily. However, more than simply collecting data, data is required to drive business value. This is where data engineering comes into play.
Data engineering is a critical function that involves designing, constructing, and maintaining systems and processes that collect, store, process, and transform data into a usable format. This includes various activities such as data ingestion, data integration, data modelling, data transformation, and data storage.
In the modern data-driven landscape, data engineering is crucial for any organization to derive value from its data assets. A well-designed data engineering system can improve data quality, reduce processing time, and enable organizations to make informed decisions based on insights derived from their data.
In this blog, we will dive into the basics of data engineering, including building, maintaining, and optimizing the infrastructure. From understanding data ingestion and modelling to designing scalable data pipelines, we will provide a comprehensive overview of data engineering and explore how it can help organizations thrive in the data-driven age.
What is Data Engineering?
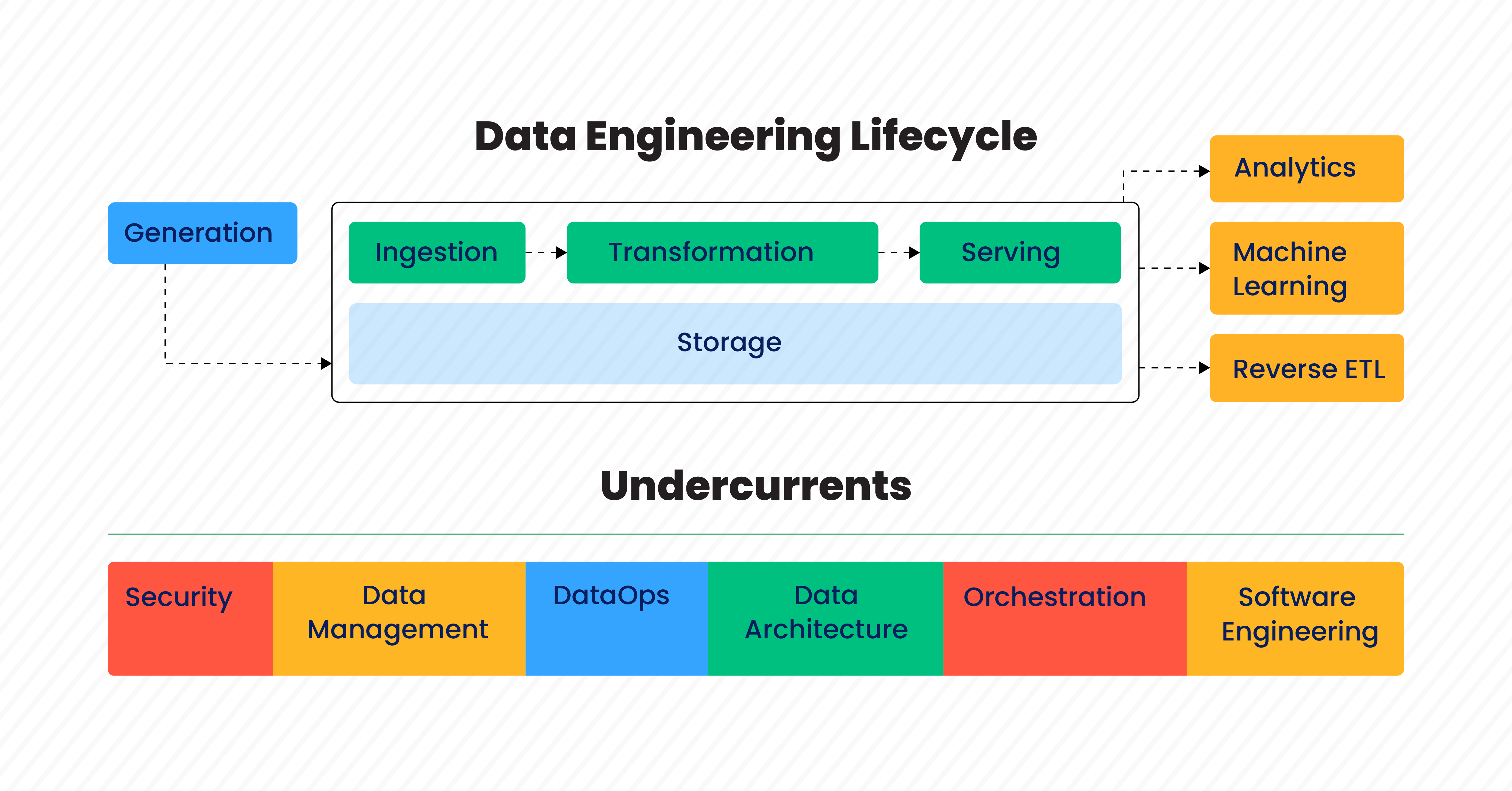
Data engineering is a critical discipline that enables organizations to manage and utilize their data assets effectively. It involves designing, constructing, and maintaining the infrastructure that facilitate the extraction, transformation, and loading (ETL) of large volumes of data from various sources into a suitable format for analysis.
Data engineers perform many tasks, including data ingestion, processing, transformation, and storage. They work closely with data scientists and analysts to understand their data requirements and design robust data pipelines that can efficiently and reliably process data at scale. Data engineers can effectively manage and process data from disparate sources by utilizing cutting-edge tools and technologies such as ETL frameworks, databases, data warehouses, and data lakes.
With their specialized knowledge and skills, data engineers play a crucial role in the success of any data-driven organization. Designing and implementing efficient and scalable data pipelines enables organizations to derive valuable insights from their data and make informed business decisions.
1. Data Ingestion: Data Ingestion is the backbone of any successful data-driven organization. It involves collecting and importing data from diverse sources into a centralized repository such as a data lake or data warehouse. Skilled data engineers utilize various methods such as batch processing, real-time streaming, and API calls to ensure that data is ingested reliably and consistently.
Challenges faced in Data Ingestion
However, data ingestion has its challenges. One of the biggest hurdles is dealing with data scattered across multiple sources and in different formats. To overcome this, data engineers must understand data integration techniques such as ETL and ELT and be adept at working with various data formats, including CSV, JSON, XML, and Parquet. Moreover, data engineers must ensure that the data is ingested in a secure and compliant manner, adhering to regulatory requirements such as GDPR and HIPAA.
Selecting the right data storage platform is another vital aspect of data ingestion. Depending on the type and volume of data, data engineers may choose to store data in a data lake, a data warehouse, or a hybrid of both. Data lakes are best suited for storing massive volumes of unstructured and semi-structured data, such as log files, sensor data, and social media feeds. On the other hand, data warehouses are optimized for structured data and are typically used for data analysis and reporting. Organizations are increasingly gravitating toward hybrid solutions that combine the strengths of data lakes and data warehouses to store and analyze data cost-effectively. When choosing a storage platform, data engineers must carefully consider the costs and performance implications before settling on a solution that best fits their organization’s needs.
In summary, data ingestion is a critical process that requires the expertise of data engineers to collect and integrate data from diverse sources into a centralized repository. Dealing with different data formats, ensuring secure compliance, and selecting the right storage platform are key challenges that must be carefully considered for a successful data ingestion strategy. With the right skills and knowledge, data engineers can help their organizations effectively manage their data assets and derive valuable insights to drive business growth.
2. Data Processing: Data processing is a crucial step in the data engineering process that involves transforming, cleaning, and aggregating data to make it usable for analysis. With the advent of big data, data engineers use various tools and techniques to process large volumes of data in real-time or batch mode. This blog post will explore the key concepts and tools used in data processing and their applications in the modern data landscape.
Real-time Data Processing and Batch Processing
Real-time data processing is essential for applications that require up-to-the-minute data insights. Apache Kafka and Apache Flink are popular technologies data engineers use to process data in real time. Apache Kafka is a distributed streaming platform that enables data engineers to stream data in real time from various sources such as sensors, websites, and social media platforms. Apache Flink is a distributed processing framework that can handle large volumes of data in real time and can be used to perform tasks such as data filtering, aggregation, and enrichment. These technologies enable organizations to respond quickly to changing market conditions and make informed decisions based on real-time data insights.
Batch processing is another critical component of data processing that involves processing large volumes of data in batches. Apache Spark is a popular tool for batch processing that can handle large-scale data processing tasks in a distributed and fault-tolerant manner. Data engineers can use Spark to perform a wide variety of functions, such as data filtering, transformation, and machine learning. Spark supports multiple programming languages such as Python, Java, and Scala, and integrates with various data sources such as Hadoop Distributed File System (HDFS), Amazon S3, and Cassandra, making it a versatile tool for data processing. With batch processing, organizations can analyze large volumes of data efficiently and derive valuable insights to inform business decisions.
3. Data Storage: Data storage is a crucial component of data engineering that involves storing data in a format suitable for analysis. Data engineers use various technologies such as relational databases, NoSQL databases, and data warehouses to store the data. They also use data lakes to store large volumes of unstructured data such as images, videos, and text. The choice of storage technology depends on various factors such as data volume, complexity, query patterns, and budget.
Popular tools for Data Storage
One popular technology for data storage is Hadoop, an open-source framework that allows data engineers to store and process large volumes of data in a distributed and fault-tolerant manner. Hadoop includes various components, such as HDFS, YARN, and MapReduce, which provide a comprehensive data storage and processing solution. HDFS is a distributed file system storing data across multiple nodes, providing fault tolerance and scalability. YARN is a resource manager that manages resources and schedules tasks in a Hadoop cluster. MapReduce is a processing framework that allows data engineers to process large volumes of data in a parallel and distributed manner.
Another popular technology for data storage is Amazon S3, a cloud-based object storage service that allows data engineers to store and retrieve data at scale. S3 provides various features such as versioning, encryption, and lifecycle policies, making it a secure and flexible data storage solution. Data engineers can use S3 to store multiple data types, such as images, videos, logs, and backups. S3 is highly scalable, allowing organizations to store and retrieve petabytes of data quickly.
Data warehouses are another technology used for data storage in data engineering. A data warehouse is a central data repository optimized for querying and analysis. Data engineers can use data warehouses to store structured data such as transactional, customer, and sales data. Data warehouses use various techniques such as indexing, partitioning, and compression to optimize query performance. Popular data warehouse technologies include Amazon Redshift, Snowflake, and Google BigQuery.
4. Data Modeling: Data modeling involves creating a blueprint of data structure and relationships to enable efficient analysis, reporting, and decision-making. A well-designed data model facilitates data storage, retrieval, and manipulation in a way that optimizes its usefulness for downstream applications.
Types of Data Modeling
There are two types of data Modeling – conceptual and physical. As a data engineer, conceptual and physical data modeling expertise is a must. A conceptual data model allows for a bird’s-eye view of the data entities and their interrelationships. In contrast, a physical data model translates this abstract representation into a concrete database structure. By skillfully navigating both types of data modeling, data engineers can ensure that the data is accurately represented, efficiently stored, and effectively utilized for achieving business goals.
In addition to designing the structure and relationships of data, data modeling involves defining the rules that govern how the data is collected, stored, and processed. This includes identifying data constraints, such as minimum and maximum values, and ensuring data accuracy and integrity. As part of the data modeling process, data engineers must also consider the scalability and performance of the database. By carefully selecting appropriate data models and ensuring efficient database design, data engineers can optimize the performance of the database, resulting in the faster and more accurate data processing.
5. Data Quality: Data quality is an essential pillar of data engineering that forms the foundation of data-driven decision-making. It is the process of ensuring that data is accurate, consistent, and complete and that it meets the required standards. Data quality can lead to correct analysis, incorrect conclusions, and suboptimal decision-making, which can have dire consequences for organizations.
Ensuring data quality is an ongoing process
Data engineers play a critical role in ensuring data quality by leveraging various tools and techniques such as data profiling, data cleansing, and data validation. These techniques help identify and eliminate errors, inconsistencies, and redundancies in the data, ensuring that the data is of high quality and fit for purpose.
Data quality is crucial because it affects the accuracy and reliability of the insights derived from the data. Accurate and reliable data is vital for making informed decisions and driving growth. Only accurate or complete data can lead to better decisions. Data engineers must ensure that the data meets the required quality standards and is fit for the intended purpose. They must also monitor and maintain data quality over time, as data quality can degrade due to various factors such as data entry errors, system upgrades, and changes in business processes.
Ensuring data quality is not a one-time process but an ongoing effort that requires continuous monitoring, refinement, and improvement. Data engineers must work closely with data analysts and other stakeholders to understand their data quality requirements and develop strategies to meet them. Data engineers can enable better decision-making, increased efficiency, and improved business outcomes by ensuring high-quality data.
In conclusion, data quality is a critical aspect of data engineering, and data engineers must use various tools and techniques to ensure that the data is accurate, consistent, and complete. High-quality data is the foundation for data-driven decision-making and business growth, and data engineers must work diligently to ensure that data quality is maintained over time.
6. Data Transformation: It involves transforming raw data into a format easily consumed by downstream applications such as analytics, machine learning, and reporting. This consists of various tasks, including data type conversions, merging data from multiple sources, and handling missing or invalid data. Skilled data engineers use techniques such as SQL queries, mapping, and enrichment to ensure that the data is properly transformed.
7. Data Normalization
In addition to these techniques, data normalization is essential to data transformation. It involves transforming data into a consistent format to ensure it can be easily analyzed and compared across different sources. Normalizing data may include converting units of measurement, standardizing date formats, and providing consistent spellings and capitalization. To accomplish this, data engineers can employ various powerful tools and techniques, including regular expressions, Python libraries like Pandas and NumPy, and SQL functions.
Normalizing data can be particularly challenging in complex scenarios where data is sourced from multiple systems with different data structures or when integrating data from different sources. However, by carefully normalizing data, data engineers can ensure that it is in a consistent format, which enables easier analysis and provides that downstream applications can work with the data effectively. In short, data transformation and normalization are essential skills for any data engineer looking to deliver high-quality data to downstream applications.
Conclusion
Data engineering is a critical part of the data lifecycle that enables organizations to manage and process large volumes of data efficiently and reliably. In this blog, we have introduced some key concepts in data engineering, such as data ingestion, data processing, data storage, data modeling, data quality, and data transformation. These concepts provide a foundation for building robust and scalable data pipelines that deliver high-quality insights for data scientists and analysts. By understanding these concepts, data engineers can design and implement data pipelines that meet the requirements of their organizations and ensure that their data is managed consistently and reliably.


