
Join our Partner Rewards Program and reap
exclusive benefits for every successful
client
referral
Resiliency Through Cloud Design: Pillar of Application Modernization
Cloud offers undeniable benefits to organizations to build cost-effective, scalable, and agile solutions. Innovation in technology and enterprise-wise competition in providing high-tech solutions have pushed enterprises towards cloud migration.
A solution like a cloud doesn’t provide resiliency automatically in any application architecture and assuming the same can bring unintended enterprise risk. Application resiliency is the ability to react to the failure of its components and provide the best possible solution at times. For multiple technology infrastructures, it’s utterly important to consider application resiliency. The resiliency in the application can be enhanced with different cloud design patterns in terms of bandwidth, communication over the internet, security, etc.
Adding resiliency to the cloud roadmap will help organizations to respond faster. By creating smaller, more manageable applications with cloud design patterns and embedding risk handling capability, companies can respond to unpredictable changes faster, and increase customer satisfaction.
5 Cloud Design Patterns Enhancing Resilience in Applications
Having resiliency-driven applications help enterprises to better perform assessment and planning for physical architecture. Creating cloud resilient applications will help organizations to better achieve the right balance between agility that cloud provides, and organizations’ risk tolerance.
The cloud design patterns to consider for resilient applications are:
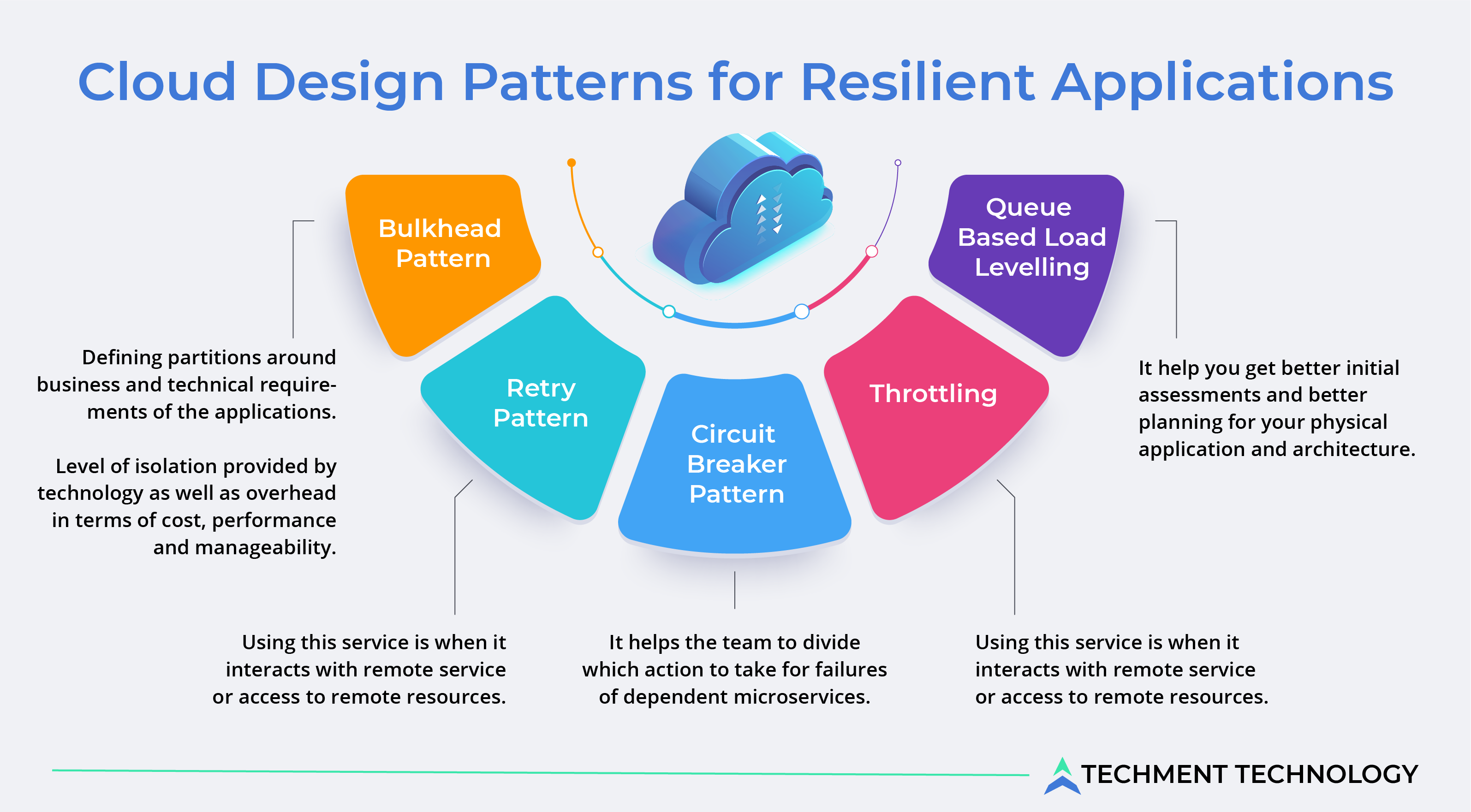
1. Bulkhead Pattern: When elements of applications are isolated with the aim to provide continuous services in case of failure then its a bulkhead pattern. Sometimes consumers may send a misconfigured request which may not respond because those resources could have been exhausted. This affects the service of multiple users. So based on consumer load and availability, the partition service is designed to isolate failure and retain service functionality at this time.
An example of a bulkhead pattern is working in “offline mode” or operating without the cloud by relying on cached resources. The requirement for this pattern are:
- Defining partitions around business and technical requirements of the applications.
- Level of isolation provided by technology as well as overhead in terms of cost, performance, and manageability.
2. Retry Pattern: This method of cloud handles the temporary failure when a request tries to connect to a service or network by retrying an operation that previously failed. Some elements running in the cloud are sensitive to transient faults like momentary loss of network connectivity, components or services, temporary unavailability of service or timeout.
Applications must be designed keeping in view their faults as they are more frequently occurring. For more common transient failures, the request can be spread to different nodes of the application evenly. On failing again it can be tried at different times.
Before implementing this pattern, make sure that all aspects are well understood and fully tested against the variety of conditions. More preferred conditions for using this service is when it interacts with remote service or access to remote resources.
3. Circuit Breaker Pattern: While dealing with excessively scaled requests, a circuit breaker pattern is used and when a dependency has to be made unavailable. It prevents the repeated request of service which is most likely to fail.
While developing a website mostly developers use this pattern to make the page available for the view but provide no content for the widget when the service is unavailable. The page can continue to service without failure.
It also helps the team to divide which action to take for failures of dependent microservices. Though microservices are well defined to isolate failure as the complexity of design increases the chances of network or hardware failure also increase. Hence circuit breaker is best to protect the resources and help the application recover the whole system from going down.
4. Throttling: This pattern controls the number of resources used by instances of applications i.e., limiting the clients from using the service or endpoints repeatedly. Usually, in business hours the number of active users increases and the application starts performing poorly, hence throttling the after the limit can save the application.
“Appropriate performance data is needed so that the system returns in the original state quickly after the load has been released”
5. Queue-Based Load Levelling: When a number of requests demand the same service while a task is running, using the same solution, it can cause performance or reliability issues. So to refactor a solution, a queue is introduced between tasks and the service that runs asynchronously.
This pattern maximizes performance and availability because delays don’t have an immediate impact on the application and can post messages of being unavailable to the queue. The adequacy of this pattern comes when the service is subjected to overloading but not for the application that expects a response from the service with minimal latency.
Having a focused resiliency-based function can help you get better initial assessments and better planning for your physical application and architecture. This functionality can go a long way in finding the right balance between the agility provided by the cloud and the risk tolerance of the organization. If organizations fail to build and integrate a resiliency function into the application development lifecycle, they must be prepared to accept the risk of unplanned downtime, especially when dealing with critical workloads.
Future Proof Your Application with the Right Cloud Design
A resiliency-focused team should critically examine all components of the application stack to understand every possible failure scenario that goes into designing applications. The resilient team should work with application, network, security, and infrastructure architects to develop an interaction node of all the components that are part of the overall application stack. Each interaction point must therefore be evaluated individually for all possible failures that must be assessed on the basis of their severity, observability, and probability.
In an “all-time available” world, the cloud poses inherent risks. The complexity and impact of disruptions require detailed and focused attention. Testing each of the risk scenarios to understand their impact and creating solutions to address the gaps between service and request can provide significant efficiency and disaster recovery plans.
At Techment Technology we monitor the challenges of risks involved in application development and cloud migration and come up with proven cloud-based solutions, platforms, architectures, and methodologies to aid smoother cloud migration with resiliency.


