
Join our Partner Rewards Program and reap
exclusive benefits for every successful
client
referral
In the era of data-driven decision-making, trust in data has become as vital as the data itself. Yet, despite massive investments in analytics and AI, enterprises often face an invisible barrier: poor data quality. According to Gartner, organizations believe that poor data quality costs an average of $12.9 million annually—not only through inefficiencies but also through missed opportunities and flawed insights.
For CTOs, QA leaders, Product Managers, and Engineering Heads, this reality translates into a hard truth: unreliable data can derail even the most sophisticated analytics or AI strategy. Whether predicting customer churn, optimizing supply chains, or automating business intelligence, analytics and AI are only as accurate as the data fueling them.
That’s why building an Enterprise Data Quality Framework is no longer optional—it’s the strategic foundation for reliable analytics and AI. This framework doesn’t merely clean data; it institutionalizes trust, governance, and accountability across every dataset, team, and decision.
This blog explores the best practices, architecture, and governance principles that power enterprise-grade data quality frameworks—and shows how to operationalize reliability for your analytics and AI initiatives.
TL;DR — What You’ll Learn
- Why data quality is the cornerstone of enterprise analytics and AI success
- The structure and components of a modern Enterprise Data Quality Framework
- How governance, automation, and monitoring create reliable data ecosystems
- Best practices and step-by-step implementation guidance
- Emerging trends shaping the future of data quality and AI reliability
Learn More: Data Management for Enterprises: Roadmap
The Rising Imperative of Enterprise Data Quality
Data is growing faster than organizations can manage it. IDC predicts that global data creation will reach 175 zettabytes by 2025, a scale that introduces massive complexity in maintaining accuracy, completeness, and consistency.
In large enterprises, challenges like data silos, fragmented governance, and inconsistent lineage often erode the reliability of analytics. As data moves across systems—from ERP to CRM to data lakes—quality often deteriorates.
Poor data quality manifests in subtle but devastating ways:
- Misleading analytics that distort decision-making
- Machine learning models trained on incomplete or biased data
- Compliance risks due to invalid or duplicated records
The result? “Garbage in, garbage out” becomes the defining barrier to AI maturity. A 2023 McKinsey report found that 68% of AI failures were directly linked to data quality and governance shortcomings.
Explore Insights: Why Data Integrity Is Critical Across Industries
What Is an Enterprise Data Quality Framework?
An Enterprise Data Quality Framework (EDQF) is a structured approach that ensures data is accurate, complete, consistent, and reliable across the organization. It defines the standards, roles, technologies, and processes required to manage and monitor data quality continuously.
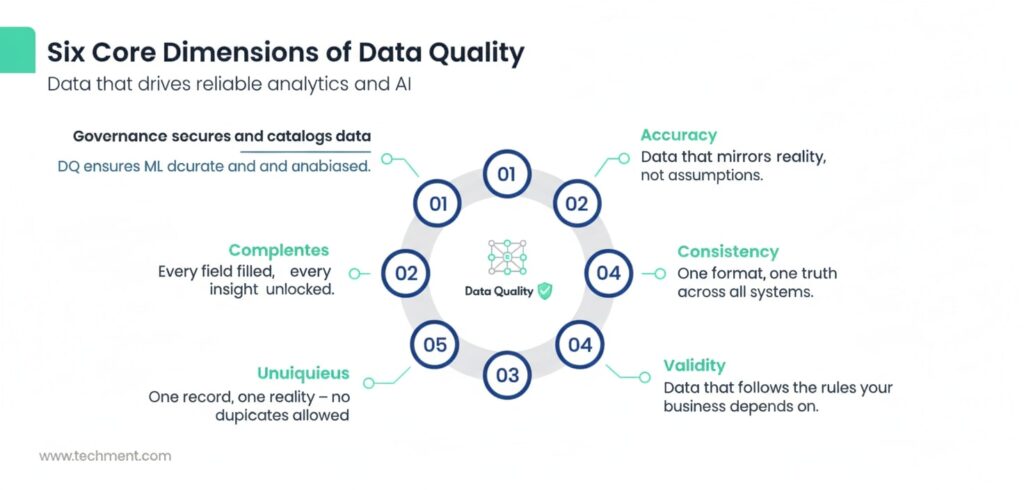
Six Core Dimensions of Data Quality
Ensuring data quality in enterprise environments requires focusing on six foundational dimensions. These pillars collectively ensure that organizational data is accurate, reliable, and ready to fuel analytics, AI, and decision-making at scale.
1. Accuracy – Data Reflects Real-World Values
Accuracy ensures that data correctly represents the real-world entities or events it describes. Inaccurate data — whether due to human error, faulty integration, or outdated sources — can lead to flawed insights and poor business outcomes. Regular validation checks, reconciliation against authoritative systems, and automated verification processes help maintain high accuracy across enterprise datasets.
2. Completeness – No Critical Missing Fields
Completeness refers to the extent to which all required data is available for analysis. Missing or null fields can severely distort analytics and AI model outcomes. Enterprises should define completeness thresholds, use mandatory field validation during data entry, and employ imputation techniques to handle unavoidable gaps — ensuring that datasets are as comprehensive as possible.
3. Consistency – Uniform Formatting and Semantics Across Systems
Consistency ensures that data remains uniform and coherent across multiple platforms, business units, or databases. Discrepancies in data formats or semantics (e.g., “N/A” vs. “NULL,” “CA” vs. “California”) can create integration conflicts. Enforcing common data definitions, maintaining a centralized metadata repository, and implementing master data management (MDM) practices are essential to achieve enterprise-wide consistency.
4. Validity – Compliance with Business and Regulatory Rules
Validity measures how well data conforms to defined business rules, schemas, and regulatory constraints. Invalid data — such as an email field without “@” or a negative quantity in inventory — signals process failures. Automated rule-based validation at ingestion points and regular audits ensure data aligns with both internal policies and external standards like GDPR or HIPAA.
5. Uniqueness – Eliminating Duplicates and Redundancy
Uniqueness ensures that each record exists only once in the system. Duplicate customer or transaction records can inflate reporting and degrade AI model training. Deduplication algorithms, entity resolution tools, and cross-system reconciliation processes help preserve data integrity and operational efficiency.
6. Timeliness – Data Availability When Needed
Timeliness ensures that data is current, updated, and accessible at the right moment. Delayed or stale data can render analytics irrelevant, especially in fast-paced industries like finance or logistics. Leveraging real-time data pipelines, automated refresh cycles, and latency monitoring ensures timely data delivery for decision-making and AI workloads.
The Four Framework Layers
A robust enterprise data quality framework operates across four interdependent layers that sustain ongoing data excellence.
1. Data Profiling & Assessment – Understanding Data Health
This initial layer involves examining data sources to assess quality metrics such as accuracy, completeness, and consistency. Using profiling tools, organizations can detect anomalies, missing values, and integrity violations early. Regular assessments form the foundation for data quality baselines and improvement roadmaps.
2. Data Cleansing & Standardization – Correcting and Harmonizing Data
Once issues are identified, cleansing processes correct inaccuracies, remove duplicates, and fill in missing values. Standardization ensures uniform formatting, naming conventions, and reference codes across datasets. Automation tools can streamline cleansing while maintaining alignment with organizational data standards.
3. Governance & Stewardship – Defining Ownership and Accountability
Governance establishes policies, roles, and responsibilities for managing data assets. Data stewards and custodians enforce compliance with quality rules and resolve data issues collaboratively. Clear ownership enhances accountability and ensures that data quality practices are embedded into operational processes and culture.
4. Monitoring & Continuous Improvement – Sustaining Data Excellence
The final layer focuses on tracking data quality KPIs and evolving standards. Continuous monitoring detects degradation trends, while feedback loops enable proactive improvements. Integrating dashboards and alerts into data management systems supports transparency and aligns data quality initiatives with business goals.
Read More: Data Quality Framework for AI and Analytics
Key Components of a Robust Data Quality Framework
A scalable EDQF relies on interconnected layers that combine governance, technology, process, and measurement.
- Governance Layer
- Define data ownership and accountability through stewardship models
- Establish a Data Governance Council chaired by business and IT leaders
- Implement data policies that outline validation rules, access, and compliance
- Technology Layer
- Deploy AI/ML-driven tools for anomaly detection and auto-correction
- Utilize metadata management systems to maintain lineage visibility
- Integrate data catalogs for transparency across data sources
- Process Layer
- Build standardized workflows for validation, cleansing, and enrichment
- Automate pipelines for real-time or batch-based quality checks
- Introduce DataOps principles to streamline collaboration
- Measurement Layer
- Define Data Quality KPIs like:
- Accuracy %
- SLA compliance rate
- Data Quality Index (DQI)
Case Insight: Unleashing the Power of Data Whitepaper
Best Practices for Reliable Analytics and AI
The future of AI-driven enterprises lies in data reliability, not model sophistication. As organizations race to adopt AI and analytics, the real competitive edge comes from building trust in the underlying data. The following best practices are essential for ensuring that your data quality framework delivers reliable, actionable intelligence.
1. Data-Centric AI Philosophy
Modern AI success depends more on the quality of data than on the complexity of algorithms. Adopting a data-centric AI approach means prioritizing clean, complete, and representative datasets over constant model tweaking. As Andrew Ng emphasizes, improving the accuracy and consistency of data often boosts model performance far more than refining model architecture. Enterprises should focus on standardizing data collection methods, minimizing labeling errors, and enforcing robust metadata management practices to enable more trustworthy AI outcomes.
2. Shift-Left Data Quality
Embedding data quality checks early in data pipelines prevents issues before they propagate downstream. This “shift-left” approach integrates validation, schema conformance, and duplicate detection at ingestion and ETL stages. By identifying anomalies at the source, organizations can dramatically reduce reprocessing costs and prevent analytics errors that erode stakeholder trust. Automated testing frameworks and data observability tools can streamline these early-stage interventions.
3. AI/ML-Driven Automation
Leveraging AI and machine learning for continuous data anomaly detection, cleansing, and lineage prediction is becoming a cornerstone of scalable data quality frameworks. Automated systems can detect missing values, outliers, or inconsistent formats in real time—ensuring a continuously improving data ecosystem. ML-based lineage prediction also helps in tracing root causes of data issues faster, enhancing both agility and governance.
4. Cross-Functional Data Governance
Sustainable data quality management requires collaboration between IT, business, and analytics teams. Establishing shared data ownership ensures accountability and promotes consistent data definitions across the enterprise. Cross-functional governance frameworks encourage better communication, clearer policies, and faster remediation cycles when data discrepancies arise.
5. Continuous Monitoring and Observability
Enterprises should implement data observability dashboards to monitor data drift, schema changes, and freshness metrics proactively. Continuous monitoring transforms data governance from a reactive to a predictive discipline. By integrating these insights with business KPIs, organizations can maintain analytics reliability and ensure that AI models evolve with accurate, up-to-date information.
Read More: Intelligent Test Automation: The Next Frontier in QA
Implementing an Enterprise Data Quality Framework: Step-by-Step
- Step 1: Assess Maturity : Begin by evaluating your organization’s current data management maturity using frameworks like the Data Management Capability Assessment Model (DCAM). This helps identify gaps in governance, processes, and technology readiness—laying the foundation for a scalable enterprise data quality framework.
- Step 2: Define KPIs & SLAs : Establish data quality KPIs and SLAs that align with business objectives—such as achieving 95% customer data accuracy or 99% completeness in financial records. Clear, measurable goals ensure accountability and enable consistent tracking of progress across departments.
- Step 3: Select Technology Stack : Adopt a modern data quality technology stack that combines automation and governance. Enable data profiling, cleansing, and rule-based validation to ensure consistency and trust in enterprise analytics and AI pipelines.
- Step 4: Establish Governance Roles : Create a structured data governance hierarchy with defined roles—Data Stewards, Custodians, and Quality Champions. These roles ensure that data ownership, policy enforcement, and issue resolution are managed effectively across business units.
- Step 5: Iterate & Improve : Treat data quality as a continuous journey rather than a one-time project. Regularly refine quality rules, monitor KPIs, and implement feedback loops to drive continuous improvement and align data governance with evolving business and regulatory needs.
Tip: Start with high-impact data domains—Customer, Finance, and Product—to quickly demonstrate value and build momentum before scaling your data quality framework enterprise-wide.
Case Study: Streamlining Operations with Reporting
Measuring Data Quality Impact on Analytics and AI
High-quality data directly improves analytics accuracy and AI performance.
Key Metrics
- Accuracy % – Fewer incorrect records
- Completeness Index – Fewer missing attributes
- Data SLA Adherence – Timely delivery and updates
- Model Drift Rate – Detects decline in predictive accuracy
ROI Snapshot
A Fortune 500 retail enterprise achieved a 22% increase in forecasting accuracy and 15% faster decision cycles after implementing an EDQF (Source: McKinsey, 2024).
Learn More: Optimizing Payment Gateway Testing Case Study
Emerging Trends and Future Outlook
The next frontier of data quality will be autonomous, explainable, and decentralized.
- Foundation Models for Data Correction: AI foundation models trained on large-scale datasets will self-correct inconsistencies automatically.
- Explainable Data Pipelines: Future pipelines will offer auditable transparency, showing exactly how data evolved from source to insight.
- Real-Time Validation: Streaming architectures will enforce continuous validation for IoT and transactional data.
- Data Mesh Architecture: Data ownership will shift to domain-driven teams, decentralizing governance but enforcing shared standards.
Explore More: Data Cloud Continuum: Promise of Value-Based Care
Techment’s Perspective: Building Reliable Enterprise Data
At Techment, we view data quality as the foundation of digital transformation. Our AI-driven data frameworks empower enterprises to ensure accuracy, lineage, and trust across analytics ecosystems. Through our work in data automation, governance, and observability, we help organizations achieve real-time reliability and readiness for AI adoption.
Read More: Unleashing the Power of Data Whitepaper
Strategic Recommendations
- Define measurable DQ KPIs early in transformation programs
- Automate data validation across ingestion and analytics layers
- Embed governance roles within business functions, not just IT
- Monitor ROI through analytics performance improvement
- Adopt continuous improvement loops aligned with AI lifecycle
Data & Stats Snapshot
- Gartner (2024): Poor data quality costs organizations 15–20% of revenue annually
- McKinsey (2023): Companies with strong DQ governance see 2.5x higher analytics ROI
- Forrester (2024): 58% of enterprises cite data inconsistency as their top AI challenge
- Accenture (2024): Reliable data pipelines improve decision speed by 40%
- Techment Research (2025): Firms integrating automation in DQ improved SLA compliance by 32%
FAQ: Enterprise Data Quality Framework
- What is the ROI of improving data quality?
Enterprises often achieve 20–40% efficiency gains and measurable improvements in analytics accuracy after implementing structured data quality frameworks. - How do you measure enterprise data quality success?
Use KPIs such as accuracy, completeness, and DQI improvement over time—backed by user adoption and reduced rework rates. - What tools help automate data quality governance?
Platforms like Collibra, Informatica, Talend, and Great Expectations offer integrated DQ automation and governance. - How can teams build cross-functional ownership?
Form a Data Governance Council with IT, business, and analytics leaders sharing accountability. - How does data quality enable reliable AI?
Reliable data minimizes model drift, bias, and prediction errors—making AI outcomes trustworthy and explainable.
Conclusion
Reliable analytics and AI begin with trusted data. Building an Enterprise Data Quality Framework transforms raw information into strategic intelligence—establishing a foundation for agility, compliance, and innovation.
For CTOs and Engineering Heads, the path to AI excellence lies not in algorithms, but in data governance maturity.
Learn how Techment can help you build a scalable Enterprise Data Quality Framework for trustworthy analytics and AI.
Get Started: Schedule a Free Data Discovery Assessment
Related Reads
- Why Data Integrity Is Critical Across Industries
- Data Quality Framework for AI and Analytics
- Data Management for Enterprises: Roadmap


