Join our Partner Rewards Program and reap
exclusive benefits for every successful
client
referral
Rapid digitalization processes generate a heap of digital and physical data, and the digital exhausts create a high volume of siloed data. The data proliferating from the value chain of CRM, ERPs, on-premise solutions, cloud solutions, and other digital platforms are often siloed and create risks and opportunities.
Hence, just as high as the requirement of data management and data quality, data modeling is vital in digital transformation!
What is Data Modeling?
Data modeling is that software engineering process that provides a blueprint for building a new database or re-engineering legacy applications. The process provides downstream results, knowledge of best data practices, and the best tools to access it. The model creates a whole information system that communicates about the connection between data points and structure.
Hence, it’s a predictable way of defining data resources, supporting business processes, and planning IT architecture across an organization and beyond.
Because of its high level abstraction, data modeling has been divided into three categories which are performed in following sequence:
- Conceptual Data Models (Domain Models): Model contains overview of what a system will contain, how it will be organized, and what business rules are involved.
- Logical Data Models: This model provides greater detail about concepts but not technical system requirements. This helps in procedural implementation environments or for data-oriented projects.
- Physical Data Models: This provides schema for how the data will be stored in the database. Also, this offers final design to be implemented as a relational database.
Why is Data Modeling Important?
A comprehensive and optimized data model is used to create a simplified database that eliminates redundancy, reduces storage requirements, and enables efficient retrieval.
Data modeling is the most crucial step in any analytical project. Data models are used to create logical databases, populate data warehouses, and implement applications that enable users to access information in meaningful ways.
Example: IBM SPSS is a data modeler software that allows data in various formats to be easily imported into data sets. According to the Gartner Peer Insights survey, it has been rated as one of the highest used data modelers (with a rating of 4.4).
Despite so many benefits to offer, the modern data stack is so intricate and diverse that creating a data model is rarely straightforward. So the question is how should an organization prepare to get into modeling? And, what are the mistakes that must be avoided in data modeling:
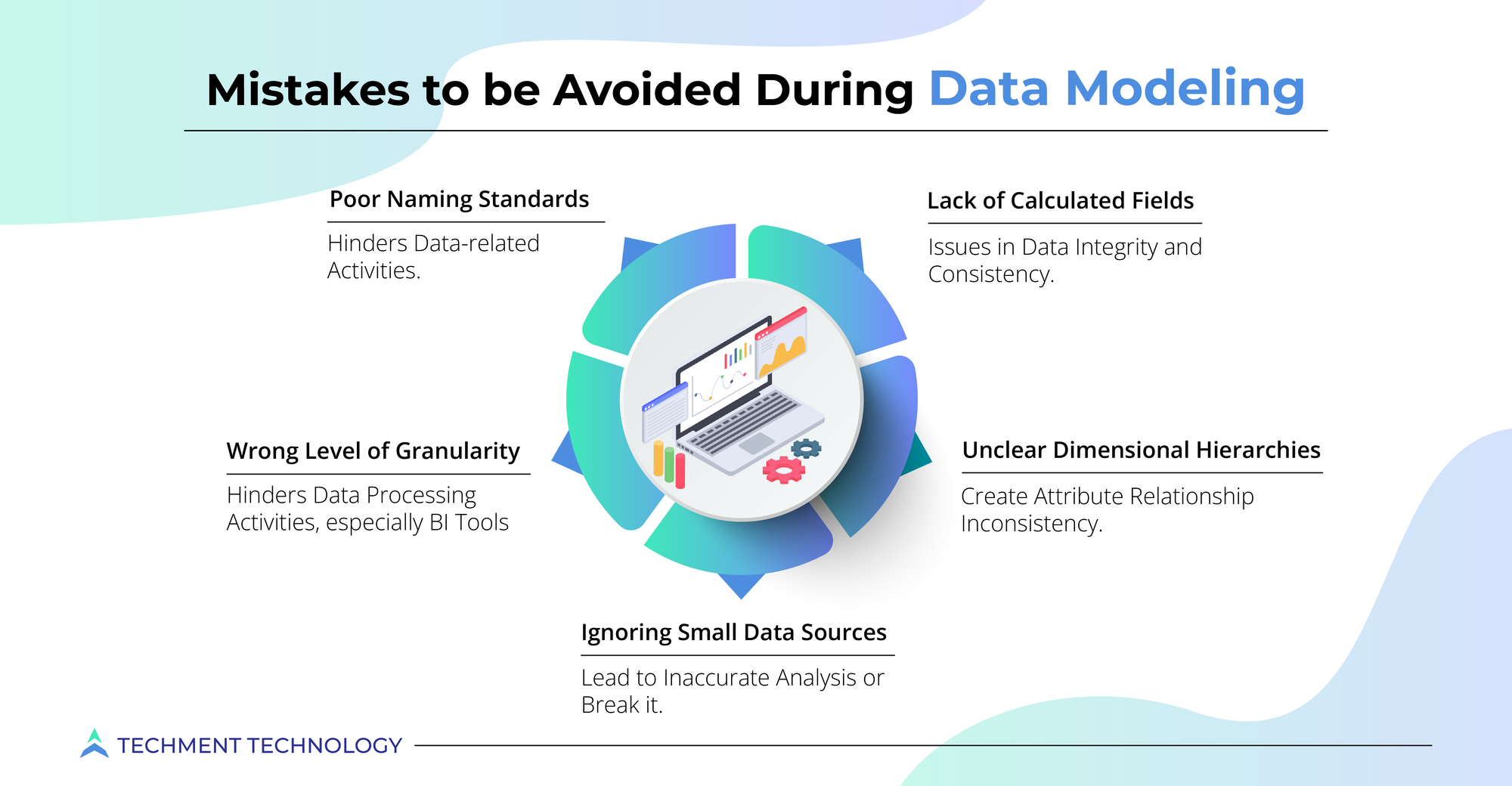
While pulling data from multiple sources, like in a data warehouse, it is necessary to map out data in warehouse format and structure conforming to the warehouse designs. Perfect data modeling and database designs are essential that work well with data warehouses and analytical tools to facilitate data exchange with business partners & stakeholders. Hence, boosting the data modeling is imperative for analytical tools, dashboards, data mining, and data integration.
How Should Organizations Boost Data Modeling?
Data modeling is crucial in AI projects as it requires high data quality. Here are the ways to boost data modeling:
1. Visualizing Data to be Modeled: The countless data rows and columns are challenging to model, whereas the graphical representations are easy to interpret and detect anomalies. Data visualization makes data clean, consistent, and error-free and spots different data types at the same time. Data modeling ensures that data is stored in a database and accurately represented.
2. Segregating Business Enquiries: Understanding business requires identifying parameters like historical sales data, feedback, etc., which are important. Segregating dimensions, facts, filters, and orders are essential to organizing data. Before data modeling, collecting the data and creating tables for facts and dimensions facilitates the analytical behavior and answers the business intelligence (BI) questions well.
3. Using Only Workable Data: Not all data generated is of use to the organization. Data modeling wastes can be avoided by identifying the correct data that needs to be modeled and eliminating the rest. Enterprise architects can create high-level data structures that support organizations’ software infrastructure and business intelligence (BI) processes.
4. Verifying Each Stage Before Modeling: Verification is necessary while modeling as lots of finer details are required for smooth running of the subsequent processes. To identify each data record, attributes like the primary key must be chosen for data sets.
For instance, ProductID in the dataset will be the primary key for historical sales data. Such identifiers also help in eliminating duplicate data.
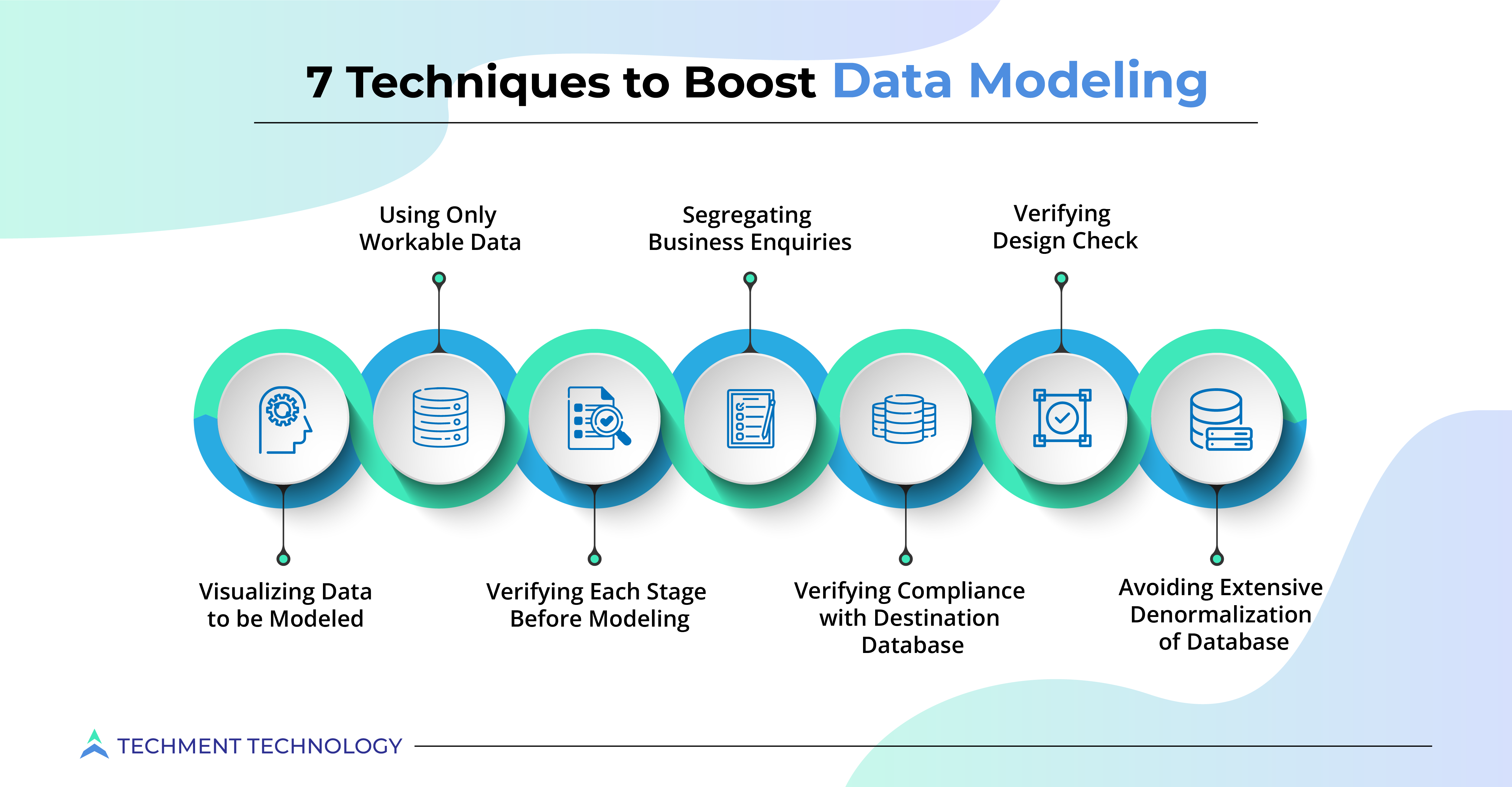
5. Verifying Design Check: Data models are built, keeping track of the source and destination databases, so the model must meet specific rules, statistical tests, and standards. While modeling for source and destination databases, different verification validations are needed, like field level mismatch between source & destination, indexes, columns, tables, etc.
6. Verifying Compliance with Destination Database: While modeling for a data warehouse, the schema script must comply with destination database providers like Snowflake, Oracle, Azure, or others.
Consider Snowflake, and it doesn’t support indexes!
If a source system is SQL Server, which supports all indexing options, Snowflake at the other end will give an error message that indexing is not supported at runtime. So complying with the destination database will be vital before deploying the target database or populating the data warehouse.
7. Avoiding Extensive Denormalization of Database: Denormalizing refers to adding redundant data to data query performance and eliminating complex join operations. But excessive denormalization should be avoided as it hampers data integrity and can be inconsistent. This may also limit the usefulness of different analytics applications. This process is seen more in business intelligence (BI) applications than in data warehouses.
Updating data models from time to time is necessary because business priorities change continuously. Hence, initial data models must be preserved, for easy expansion & modification in the future.
Conclusion:
Updated Data Models Will facilitate Data Integrity
Database designs have also changed in the past few years, where traditional databases were stored using disk and in dozens of different tables, whereas at present, they are stored in columnar designs to reduce tables and improve speed & efficiency.
Organizations demand constant new systems, innovative database structures & techniques, and new data models for further development efforts. Information connectivity and significant data sources are extending IT professionals’ scope of data modeling. Such expansions will be easy to manage with the help of cloud computing infrastructure, where databases can be stored and easily accessed. Cloud infrastructure will help ensure data integrity and make the company’s data more reliable. Techment’s data modelers are capable of developing such self-service tools and making data modeling & visualization more collaborative. For free consultation, contact us.