
Join our Partner Rewards Program and reap
exclusive benefits for every successful
client
referral
One major focus in the field of data transport and transformation involves the creation of ETL pipelines. Numerous tools and technologies allow for constructing these pipelines on-premises or in the cloud. An ETL pipeline is the foundational structure that empowers data to become meaningful, actionable, and advantageous. It represents a remarkable engineering achievement that turns unprocessed data into valuable insights, empowering organizations to make informed choices and formulate future-oriented strategies.
The effectiveness of an ETL tool lies in its ability to support a wide range of data transformations. These transformations are crucial in constructing robust data pipelines, freeing developers from the need to undertake extensive custom development efforts. Azure Data Factory (ADF) is an Azure cloud service designed to aid in developing ETL pipelines. The primary method for data transformation in ADF involves utilizing the Data Flow component’s various transformations. You can easily orchestrate and automate data transfer and transformation tasks, allowing seamless and efficient data management.
But the common question when using a cloud-based data platform for transformation is, will this accommodate large data from widely distributed sources? For instance, in a financial firm, if there are over 10,000 data tables stored across multiple legacy servers and platforms, it presents significant challenges in terms of accessibility for business reporting purposes. Would migrating to the cloud provide a scalable solution for managing this large amount of data efficiently?
Undoubtedly, ADF can handle large volumes of data effectively.
Scalable Data Transformation with ADF’s Robust Pipeline
ADF is a powerful tool that allows users to perform Extract, Load, and Transform (ELT) operations in Azure. With ADF, users can easily transform their data into the desired format, making use of downstream applications and analytics easier.
One of the standout features of Azure Data Factory is its ability to replicate data between various sources and targets seamlessly. This platform can offer enhanced capabilities and performance by leveraging Spark’s underlying technology stack.
In addition, ADF provides built-in parallelism and time-slicing features, allowing users to quickly and efficiently migrate large amounts of data to the cloud in just a few hours. This helps to improve the overall performance of the data pipeline significantly.
Techment’s Approach of Data Transformation in ADF
One of our clients working for a financial firm, received and managed diverse financial and safety data from various sources like ComputerEase, Quickbooks, Spectrum, Sage 100, Sage 50, Foundation, Netsuite, Sage Intacct, and safety metrics in CSV format, and centralizing these data for business insights was essential. Also, data mapping was necessary here to map data fields and derive meaningful insights for analytics.
Due to the diverse formats of historical and real-time data, ranging data from safety measures, training, financial data like financial performances, data about back-office support, desk management, etc, were stored in CSV format in the SQL server. The management of this data required transformation and thorough cleaning process to maintain data integrity.
The existing tools and data management systems did not allow for easy and efficient data access for business reporting. Hence, to help gather data from existing applications and enable business analytics, we provided a more accessible and 360-degree view of business data through different dashboards like fleet dashboard, salesforce dashboard, financial dashboard, activity dashboard, and more.
In such scenarios, it’s preferable to take stored procedures to allow complex data transformations to perform intricate data manipulation. This helps to encapsulate the SQL and business logic, which provides reusability and modularity.
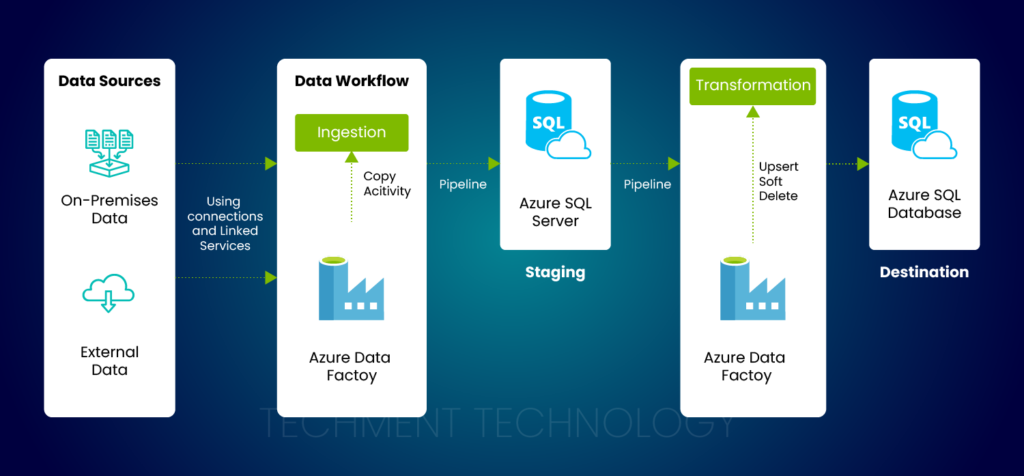
For our client, we built an ETL data pipeline using Data flow in Azure Data Factory, as this is a code-free data transformation method that executes in Spark. The ADF Dataflow was triggered to build a scalable ETL data pipeline in Azure, carrying out the necessary data transformations. The DataFlow feature allows developers to configure data transformation logic using a no-code, drag-and-drop approach and implement transformation.
Mapping Data Flows operates on distinct compute resources. The visual representation of data flow undergoes conversion into Scala and is further compiled into a JAR library. This library is subsequently processed on a Spark cluster to execute relevant data flow activities. A robust data pipeline was created, seamlessly depositing the refined data into a SQL server. The integration of Azure SQL ensured centralized and reliable data storage.
As the client needed a visualization solution, we provided them with dashboards in Power BI, and even did the data modeling in Power BI. To ensure accuracy, we also included manual data validation within the Azure Data Factory (ADF) pipeline. The team also optimized the pipeline and explored queries to ensure data retrieval was as efficient as possible. We used scheduled triggers to automate the pipeline, ensuring data is updated automatically.
These BI dashboards provided value by giving a complete view of past performances, future scope of improvements, trends, and more. This end-to-end solution improved data accuracy and accessibility, and has significantly enhanced the client’s capacity for data-driven insights and strategic decision-making.
The Tangible Values Delivered
Through ADF’s Data Flow, our data transformation process saw a remarkable improvement in quality, as there were fewer chances of error because mapping Data Flows can be scaled out for high data processing requirements. We also reduced data retrieval times by 40% for our client with easy access to vital insights.
Here Dataflow offers the advantage that different refresh schedules can be set for different tables. This is particularly useful for large tables with infrequently changing data. With Dataflows, you can specify that such tables should not be refreshed daily like the other tables.
Moreover, Dataflows provide the option to create and expose multiple tables that others can use and connect back to it with build access and bring in the tables they need.
Techment’s Data Transformation Capabilities Driving Success for Organizations
With ADF’s robust data transformation capabilities, we empower organizations to elevate their data quality, streamline integration processes, and enhance accessibility for downstream applications and analytics. Our tailored approach ensures that your data is not just transformed, but optimized to drive maximum value for your business.
We help organizations provide a reliable and scalable framework for data integration and transformation in the cloud. If you want to take your data strategy to a new height, we are here to deliver cost-effective and efficient solutions that meet your unique business needs.
Reach out to us now to learn more about how we can leverage different data transformation solutions to transform your data landscape and drive success for your organization.