
Join our Partner Rewards Program and reap
exclusive benefits for every successful
client
referral
Outburst of data volume, users, and use cases have been troubling stakeholders especially for data engineers & analysts as this brings multitude of data management challenges. Since they are required to provide high-quality, accurate, and useful data for ready-to-use analytics, they leverage automation in data engineering tasks like- data cleaning, data collection, data warehousing, ETL processes, etc.
Data pipeline, which constitutes necessary steps from data ingestion from multiple sources, transformation, processing, and then loading into destination, is now a time taking process which is slowing down the delivery of data products. Hence, data teams require data pipeline automation which delivers data at pace while maintaining speed and quality, and justifying the returns.
What is Data Pipeline Automation?
An automated data pipeline is a pipeline that has been set up to run automatically using triggers. This process includes all aspects of pipeline engineering and operations covering design, development, testing, deployment, orchestration, and change management. By directly integrating analytics into business processes, automation uses data in ways that allow machines and technology to perform business activities.
Data pipeline automation replaces data stacks that have been assembled from multiple tools & platforms. Pipeline automation means a function that automates scheduled jobs, executes workflows, coordinates dependencies among tasks, and monitors execution in real-time.
Why Does Your Enterprise Need Automated Data Pipeline?
Based on the type of data pipeline, automation functions to process all new data events or ensure the processing occurs instantly, process data at their predefined points, or automate other data engineering processes. Enterprises must figure out where automation fits in the pipeline or why they need automation.
Here are some important reasons to automate data pipeline:
- When It’s Difficult to Connect Multiple Data Sources: Extracting data from different sources is the first step in the data analytics process and linking all data sources is tedious and a time-taking task. Automation setup functions to extract data whenever a task becomes repetitive.
- When Data Changes Constantly: When data changes at the source, it becomes difficult to get the historical records required for running projects. Here, automation functions extract historical data for projects by a time-based trigger for analysis.
- When Standardized Data Cleaning is Required: Cleaning a database (fixing, removing, and formatting inappropriate data within a dataset) can be destructive when performed inappropriately and is a cumbersome process. Applying automation can set up customized data flow from the source and will make standard data available in the target system.
One of our clients in the winery industry was unable to manage a large volume of data due to an outdated system, so we migrated their data to a new data storage system, which demanded data cleaning. While ingesting data, our team treated null values (missing values) in the dataset by replacing them with appropriate values.
How Data Pipeline Automation Benefits Different Departments in Organization?
- In Engineering Processes:Data engineers build data pipelines with detailed designs & specifications and perform applied architecture activities for the data analytics process. Learning architectural standards of automation tools allows them to reuse those standards for cumbersome processes rather than rewriting entire code.
- In Operation: To ensure that the pipeline operates as planned and data is delivered as expected, automated orchestration & monitoring tools are used. This improves scheduling, manages workflow, and processes real-time execution more efficiently. Also, automation can scan pipeline task histories to help improve processes.
- In Data Governance: In data governance, automation enhances data lineage tasks which help in building metadata and maintaining end-to-end records.
- In Business Perspective: As automation reduces manual tasks, it reduces errors in data and improves data quality which enables business stakeholders to access timely & comprehensive data.
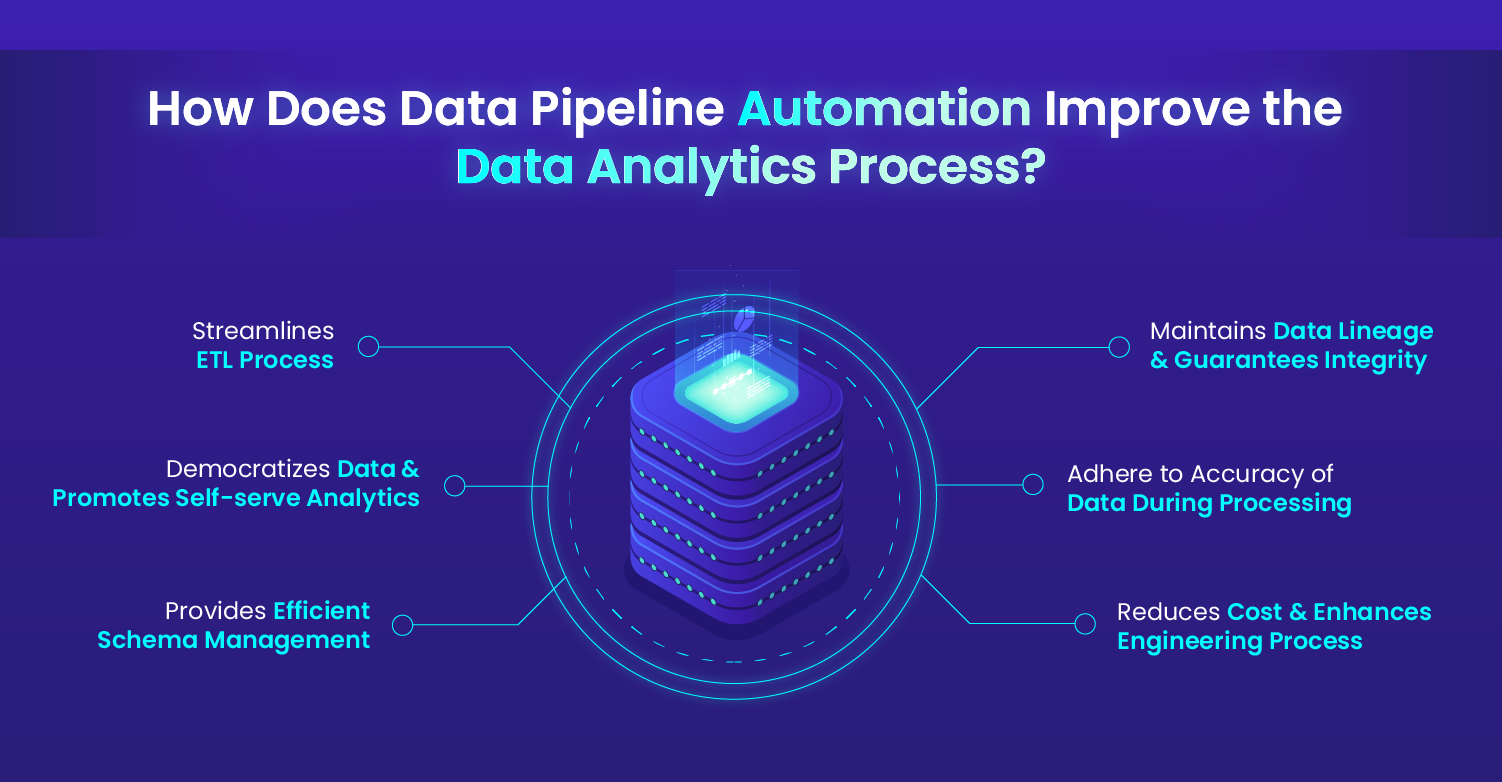
How Does Data Pipeline Automation Improve the Data Analytics Process?
Data Pipeline Automation simplifies intricate procedures, like cloud migration, removes manual adjustments in data pipelines, and creates a safe framework for data-centric businesses.
Here we will illustrate the benefits of data pipeline automation in the data analytics process.
- Streamlines ETL Process: The ETL process includes data extraction from the source, transformation, and storage in a data warehouse or data lake for utilization in business processes. This complex task is taken away by data pipeline automation. This replaces manual pipeline coding and manipulations, simplifies complex data processing, and secure mechanism for data exploration & insights.
- Democratizes Data & Promotes Self-serve Analytics: Data professionals spend more time in data preparation, running queries, or in deriving valuable analytical insights. With automation, business users can schedule data pipelines as needed, ingest data in real-time, and connect cloud databases with business applications to get insights.
- Provides Efficient Schema Management: Every time a change appears in data, like a new column addition, it gives rise to multiple versions which can interrupt the entire ETL process. This interruption brings unexpected elements and data would never reach its destination, leading to downtime and accumulation of stale data. Tracking these changes in data and updating them in the repository comes with overhead.
Automation allows us to make changes instantly and reflect the same in the repository, losslessly and immediately. This prevents any downtime in the data pipeline and will eliminate a lot of the tedious coding work required to adapt to schema changes. - Maintains Data Lineage & Guarantees Integrity: For confident decision-making data integrity is important which comes with proper data lineage. Automating a data pipeline actively maintains the lineage, identifies problems quickly and accurately, and notifies the company to avoid data-based decisions until the issue is resolved.
- Adhere to Accuracy of Data During Processing: Every data record needs to adhere to quality rules which need to be checked at every processing stage of the pipeline. Through the automation of data pipelines, data is assessed in real-time against quality rules or assertions.This real-time tracking avoids costly reruns and delays. It reduces the amount of rework arising after quality checks and simplifies data workflows.
- Reduces Cost & Enhances Engineering Process: Early adopters of data pipeline automation realize additional benefits in terms of cost saving, reduced overhead, etc. Also, engineers do not need to worry about debugging a vast library of code or tracing data lineage, hence increasing the speed of delivery.
Teams can realize dramatic savings in tools or softwares which stem from various points in the process.
Data engineers work to make the magic of data science possible. This entails so many manual tasks which when automated, can save time & effort. With growing data volume, these tasks have become repetitive which increases downtime and leads to the accumulation of stale data, further complicating the entire process.
With an automated data pipeline, data analytics, and engineering process can reach a higher maturity level by making processes non-repeatable. This way enterprises can keep pace with the demands of data-driven business.
How Techment Applied Data Pipeline Automation?
One of our clients in the vinery industry wanted to migrate their large amount of historical data from the MySQL database to the Azure SQL database. Apart from migration, it involved data cleaning and validation. We automated the responses to the events to ensure that the processing occurs instantly.
Ingesting 12 years of customer data was not an easy task and may cause errors while migrating the data. So we automated the data pipeline to ensure accurate & timely information. This also helped us in checking null values and identifying erroneous data points which might have been missed during data extraction. Migrating this large amount of data efficiently we were able to enhance the sales of our clients by 20 to 25%.
Conclusion:
Automated Data Pipeline will Bolster a Data-centric Culture
To span data-driven culture, more people in an organization need to have access to automation tools and technologies. This way more people will be able to gauge their assumptions and outcomes and will feel empowered. Automation will help in scaling the data pipeline while also optimizing cost. The complicated processes like data streaming, data aggregation, and others can be simplified with automation.
Automated data pipelines are the future of data-driven practices that will enable companies to expand their processing capabilities and provide real-time solutions to their customers and teams.
Techment provides expertise at every stage of data engineering, i.e., ETL process, data visualization, data modeling, and more. Connect with our experts to know about our data engineering services.