“Data pipelines that fail quietly or drift invisibly are among the most insidious causes of strategic failure in AI/analytics initiatives.”
That statement echoes a growing reality facing CTOs, Heads of Engineering, and Data Leaders: the foundation underlying your ML, BI, and operational AI systems is only as strong as the pipeline design that feeds them.
In today’s data-rich environment, selecting the right design patterns is not merely a technical concern — it directly impacts system stability, agility, and business outcomes.
In this blog, we explore Essential Design Patterns in Modern Data Pipelines to help you architect data systems that are scalable, reliable, observable, and future-proof. Whether you’re building real-time anomaly detection, unified customer analytics, or large-scale model training, the design decisions you make now will echo through performance, cost, and trust in your data.
TL;DR — What You’ll Gain
- Why data pipeline design patterns are business-critical now
- Authoritative definitions and framework components
- Core pipeline design patterns and when to use them
- Best practices for reliability, observability, and automation
- Step-by-step roadmap for adoption
- Metrics, ROI levers, and a mini case example
- Future trends like data mesh, observability, and AI-native pipelines
- Techment’s approach to pipeline strategy and transformation
Learn how Techment empowers data-driven enterprises in Data Management for Enterprises: Roadmap
1. The Rising Imperative of Essential Design Patterns in Modern Data Pipelines
Why This Topic Matters — Now
The past five years have triggered a seismic shift: data volume, velocity, and diversity have outpaced the monolithic, ad hoc ETL systems many enterprises rely on. Today, organizations wrestle with pipelines that:
- break under load,
- drift without detection,
- lack lineage or auditability,
- incur rising maintenance costs,
- and propagate inconsistencies into downstream analytics and AI.
According to Gartner (2024), by 2026, over 70% of organizations will treat data pipelines as products with SLAs, not just internal plumbing.
McKinsey’s AI Adoption Report (2023) adds that enterprises with mature data systems are 2× more likely to achieve measurable ROI from AI initiatives.
Pipelines are no longer invisible infrastructure. They are strategic enablers — the arteries through which data vitality flows. Neglecting them invites business risk: from compliance violations to degraded AI performance.
The Cost of Inaction
Without structured patterns, organizations accumulate pipeline debt — brittle, undocumented, and reactive architectures that resist change. This leads to:
- Operational fragility: Small schema changes cause cascading failures.
- Poor observability: Data errors propagate silently until discovered by end users.
- Engineering drag: 60–70% of team time lost to maintenance.
- Trust erosion: Stakeholders question analytics validity.
- Innovation freeze: New data sources and models take months to onboard.
The results? Missed opportunities, eroded margins, and a widening gap between technical potential and business realization.
Investing in essential design patterns in modern data pipelines is not optional — it’s a strategic imperative for resilient, data-driven enterprises.
Explore real-world insights in Why Data Integrity Is Critical Across Industries
2. Defining Essential Design Patterns in Modern Data Pipelines
What Do We Mean by “Design Pattern”?
In software engineering, a design pattern is a reusable solution to a recurring problem. In data engineering, it’s the architectural blueprint guiding how data is ingested, transformed, governed, and delivered — balancing trade-offs across latency, scalability, consistency, and cost.
Design patterns don’t prescribe tools — they prescribe structure. They help you choose whether to use batch or streaming ingestion, ETL or ELT, linear or branched transformations, centralized or domain-owned pipelines, and manual or automated governance.
Core Dimensions of Data Pipeline Design Patterns

Each layer embodies reusable pattern decisions. The composition of these patterns defines your pipeline architecture.
Dive deeper into AI-driven data frameworks in Data Quality Framework for AI and Analytics
Key Components of a Robust Pipeline Framework
Modern data pipelines are the nervous system of enterprise analytics and AI. To make them resilient, scalable, and observable, each layer must be designed intentionally — not incidentally.
3.1 Ingestion & Ingress Patterns
This is the entry point of your data — the “on-ramp” where it all begins.
Common Ingestion Patterns
- Batch ingestion — periodic, bulk data loads (e.g., nightly ETL jobs)
- Micro-batch ingestion — frequent small loads (every few minutes)
- Streaming ingestion — continuous event-driven flows
- Change Data Capture (CDC) — incremental updates based on database logs
When to Use Each
- Use batch for stable, non-real-time workloads (e.g., finance reporting).
- Use streaming for real-time analytics (fraud detection, personalization).
- Use CDC for efficient synchronization without full reloads.
- Combine batch and streaming (hybrid) for cost-efficient agility.
Pro Tip:
Adopt a metadata-driven ingestion pattern, where schema and transformation rules are parameterized — not hard-coded. Research on metadata-driven ingestion models (Arxiv, 2025) found that schema evolution costs drop up to 35% in enterprise-scale data platforms.
3.2 Pre-Processing, Filtering, and Cleansing
Once data enters, quality assurance begins.
- Filter invalid records to maintain data trustworthiness.
- Schema validation and type enforcement prevent silent errors.
- Deduplication ensures idempotency for recurring ingestion.
- Canonical schema normalization harmonizes formats across domains.
- Light enrichment (adding geolocation, category tags, etc.) can happen at this stage.
This stage ensures the rest of your pipeline doesn’t operate on “garbage in.”
3.3 Transformation & Enrichment
The transformation stage defines how raw data becomes business-ready.
Core Transformation Patterns
- ETL (Extract–Transform–Load): transformations before loading (legacy model).
- ELT (Extract–Load–Transform): transformations post-load, in the target store (modern cloud-native approach).
- Streaming transformation: event-by-event computation using windows or stateful stream processing.
- Hybrid (Lambda or Kappa): combining both real-time and batch streams.
According to GeeksforGeeks, Lambda and Kappa architectures enable systems to maintain both real-time responsiveness and historical accuracy. The best-fit choice depends on your latency tolerance and data freshness needs.
3.4 Storage & Serving Layer
This layer determines where data “lives” — and how fast it can be accessed.
Storage Options
- Data Warehouses (e.g., Snowflake, Redshift, BigQuery): BI-focused, optimized for SQL workloads.
- Data Lakes / Lakehouses (e.g., Databricks, Delta Lake): unify raw and curated data for both analytics and ML.
- Feature Stores (e.g., Feast, Tecton): specialized storage for ML training and inference features.
- API Serving Layers: deliver enriched data for applications.
Design Considerations:
- Choose schema-on-write for governance-heavy pipelines.
- Use schema-on-read for flexibility in analytics exploration.
- Partition and cluster by access frequency.
- Plan retention and tiered storage (hot, warm, cold).
3.5 Orchestration & Flow Control
The orchestration layer is the “brain” that coordinates the pipeline.
Core Orchestration Patterns
- DAG-based orchestration: (e.g., Apache Airflow, Prefect, Dagster) manages dependencies and scheduling.
- Event-driven orchestration: triggers jobs based on external events (e.g., file arrival, Kafka topic activity).
- Stateful orchestration: allows iterative or feedback-driven processes.
Reliability Principles:
- Use checkpointing to restart failed stages gracefully.
- Design for idempotency — multiple runs shouldn’t corrupt state.
- Implement retry logic and dead-letter queues (DLQs) for error handling.
3.6 Observability, Lineage & Governance
Observability is no longer optional. It’s the backbone of data trust.
- Logging & Metrics: Track throughput, error rate, latency.
- Lineage tracking: Understand how data flows across transformations.
- Schema versioning: Manage evolution without breaking dependencies.
- Alerting & Drift Detection: Automate anomaly identification.
- Access Controls & Masking: Enforce data privacy and compliance.
Enterprises are now embedding data observability platforms to monitor freshness, schema drift, and null anomalies in real time.
3.7 Reliability & Resilience
Pipelines must survive failures gracefully.
Design patterns for reliability:
- Idempotent transformations
- Exactly-once or at-least-once delivery
- Checkpointing for streaming systems
- Fallback or circuit breaker logic
- Dead-letter queues for bad data
Incorporating these resilience patterns turns brittle ETL code into enterprise-grade pipelines.
See how Techment implemented scalable data automation in Unleashing the Power of Data Whitepaper
4. Best Practices for Reliable & Scalable Pipelines
Modern enterprise pipelines should be built for predictability, repeatability, and adaptability.
Here are 6 proven best practices:
- Adopt Schema Contracts & Versioning
Define strict schema validation rules. Evolve with backward compatibility — not ad hoc changes. - Leverage Metadata-Driven Configuration
Store transformation logic, source details, and dependencies as metadata. Simplifies onboarding and maintenance. - Implement Observability from Day Zero
Integrate logs, metrics, and traces before scaling the system. Measure freshness, volume, and anomalies continuously. - Use Canary or Shadow Pipelines
Test new transformations on sampled data before production. Helps detect regressions early. - Design for Idempotency & Safe Retries
Avoid duplication and data corruption during reprocessing. Prefer exactly-once semantics where feasible. - Embed Governance & Compliance Rules in Code
“Governance-as-code” enforces data quality, masking, and access control consistently across pipelines.
Following these practices helps enterprises move from reactive firefighting to predictive stability — improving both confidence and speed of innovation.
Explore how Techment drives reliability through automation in Intelligent Test Automation: The Next Frontier in QA
5. Implementation Roadmap: Step-by-Step Guide
A pragmatic roadmap helps leaders evolve from fragile legacy flows to modern, pattern-based architectures.
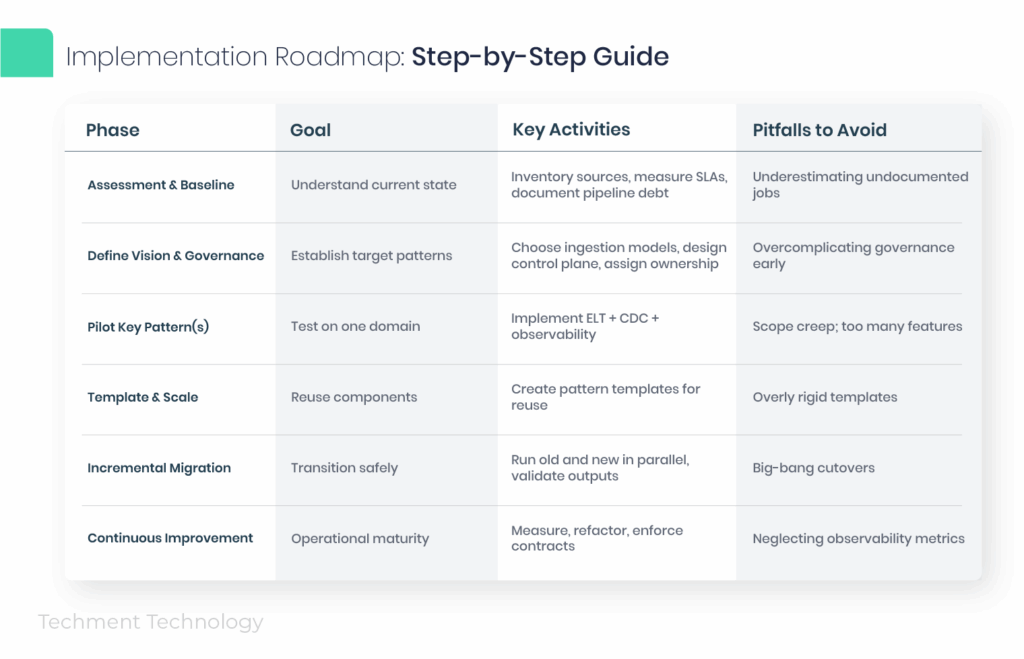
Pro Tips:
- Start with the minimum viable pipeline (MVP) — ingestion + transformation + observability.
- Use shadow runs for validation.
- Maintain a pipeline catalog for ownership and SLA visibility.
- Integrate governance and alerting within orchestration DAGs.
This roadmap aligns with Techment’s data modernization frameworks used in enterprise-scale transformations.
Read how Techment streamlined governance in Streamlining Operations with Reporting Case Study
6. Measuring Impact & ROI
Why Measure?
You can’t improve what you don’t measure. Design patterns must translate into business value — faster delivery, better reliability, and measurable trust in data.
Key Quantitative Metrics

ROI Outcomes
- Reduced latency → faster insights → quicker decisions.
- Improved observability → fewer incidents → more uptime.
- Governance-as-code → reduced compliance risk.
- Metadata-driven reuse → lower engineering cost.
- Consistent quality → higher trust → better AI outcomes.
According to McKinsey’s 2023 AI ROI study, firms that implement mature data governance and observability frameworks realize 2.5× higher ROI from AI-driven initiatives.
Mini Case Snapshot
A retail fintech enterprise migrated from legacy ETL to a hybrid ELT + streaming architecture based on essential design patterns.
Results (after 6 months):
- Latency reduced from 4 hours → 5 minutes
- Data error detection: 5 min → real-time
- Engineering rework reduced by 60%
- Operational costs down by 25%
- Enabled 3 new data products: fraud monitoring, dynamic pricing, and unified customer analytics
That’s tangible ROI — achieved not just through technology, but through pattern discipline.
Discover measurable outcomes in Optimizing Payment Gateway Testing Case Study
7. Emerging Trends and Future Outlook
Design patterns continue to evolve with technology and enterprise needs. Here’s what’s shaping the next decade of data pipelines:
7.1 Data Mesh and Productized Pipelines
The shift toward data mesh decentralizes ownership: each domain becomes accountable for its own “data products” — complete with pipelines, governance, and observability.
This demands design patterns for domain isolation, federated governance, and self-serve infrastructure.
7.2 Observability and AIOps
Future pipelines will go beyond logs and metrics. Data observability + AIOps means using ML to predict anomalies, self-heal pipelines, and recommend resource optimizations.
7.3 Foundation Models & Vector Data Pipelines
As enterprises integrate LLMs and vector databases, new design patterns emerge for:
- Vector ingestion and embedding pipelines
- Real-time semantic search
- Model drift monitoring and vector reindexing
These are becoming critical for GenAI applications across industries.
7.4 Multi-Cloud and Hybrid Data Architectures
To avoid vendor lock-in and improve redundancy, enterprises are designing multi-cloud pipelines — leveraging cross-cloud ingestion, shared metadata catalogs, and unified control planes.
7.5 Serverless and Function-Based Pipelines
Serverless architectures (e.g., AWS Lambda, Google Cloud Functions) are enabling lightweight, event-driven pipeline components — perfect for dynamic scaling.
Explore next-gen data thinking in Data Cloud Continuum: Value-Based Care Whitepaper
8. Techment’s Perspective and Approach
At Techment, we view pipelines as strategic enablers — the scaffolding for enterprise intelligence, automation, and AI innovation.
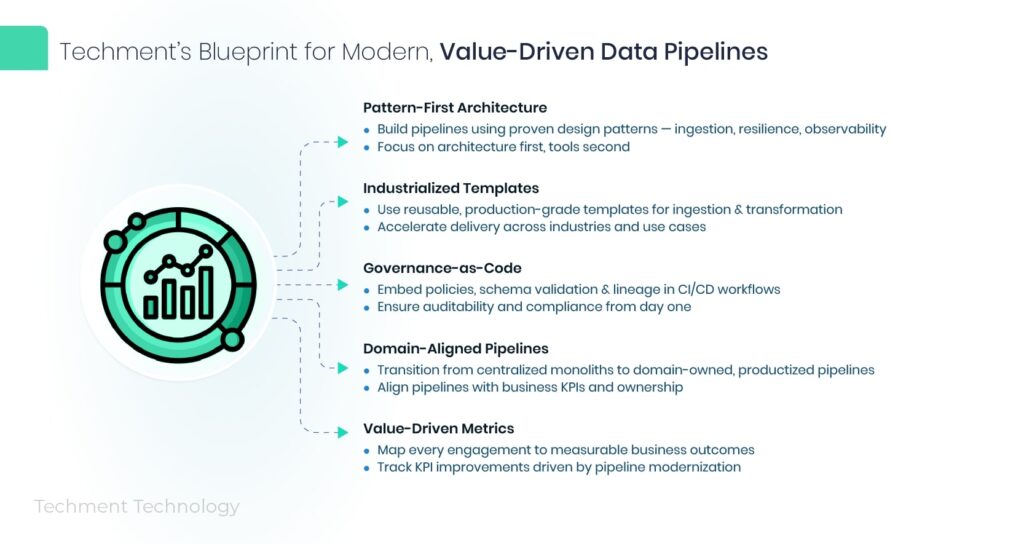
Our Core Principles
- Pattern-First Architecture
Every pipeline begins with proven design patterns — ingestion, resilience, observability — before tool selection. - Industrialized Templates
Techment maintains reusable, production-grade templates for ingestion, transformation, and observability layers across industries. - Governance-as-Code
Policy, schema validation, and lineage tracking are embedded in CI/CD workflows — ensuring auditability from day one. - Domain-Aligned Pipelines
We help enterprises transition from centralized monoliths to domain-owned, productized pipelines aligned with business KPIs. - Value-Driven Metrics
Every engagement includes KPI mapping — translating architecture improvements into measurable business outcomes.
“We treat data pipelines as living products. If your pipeline fails you, your mission fails.”
— Techment Data Engineering Lead
This philosophy helps clients achieve operational reliability, analytics trust, and AI scalability — without sacrificing agility.
Get started with a free consultation in Unleashing the Power of Data Whitepaper
Conclusion
Enterprises today stand at a crossroads:
Either modernize your data pipelines through design discipline — or risk being paralyzed by complexity, inconsistency, and fragility.
The Essential Design Patterns in Modern Data Pipelines outlined here provide a roadmap to build future-ready data systems — not just for analytics, but for sustained digital transformation.
If your pipelines still rely on ad hoc scripts or manual interventions, now is the time to act. Start small, pilot one pattern, embed observability, and scale incrementally.
The payoff — agility, trust, and business acceleration — is undeniable.
Schedule a free Data Discovery Assessment with Techment at techment.com/contact-us
Frequently Asked Questions (FAQ)
Q1. What is the ROI of implementing essential pipeline design patterns?
A: ROI appears as reduced latency, fewer incidents, higher data quality, and faster onboarding of new data sources. Most enterprises see positive ROI within 6–12 months.
Q2. How can enterprises measure success after refactoring pipelines?
A: Track latency, error rates, throughput, MTTR, and business enablement metrics (e.g., new analytics products released). Compare pre- and post-implementation baselines.
Q3. What tools enable scalability while following modern design patterns?
A: Tools like Airflow, Dagster, Kafka, Flink, BigQuery, Databricks, and Monte Carlo support pattern-based architecture. But framework discipline matters more than tooling.
Q4. How should enterprises modernize legacy pipelines without major downtime?
A: Use shadow runs and parallel execution for validation. Gradually shift workloads to the new architecture, retiring legacy components incrementally.
Q5. What governance challenges typically arise in modern data pipelines?
A: Common pain points include schema drift, lack of lineage, inconsistent access control, and manual compliance tracking. Solved via governance-as-code and metadata-driven policies.
Related Reads on Techment.com
- Why Data Integrity Is Critical Across Industries
- Data Quality Framework for AI and Analytics
- Data Management for Enterprises: Roadmap
- Streamlining Operations with Reporting Case Study



