
Join our Partner Rewards Program and reap
exclusive benefits for every successful
client
referral
Why orchestration is no longer optional
As data environments grow in scale and complexity, traditional hand-cranked ETL/ELT scripts no longer suffice. Enterprises now contend with:
- Hybrid infrastructures (cloud, on-prem, edge)
- Multi-modal workloads (batch, streaming, change-data-capture, micro-batches)
- Interdependent services (AI/ML, analytics, operational systems)
- Strict SLAs and availability requirements
- Trust and governance demands from compliance, audit, and business users
Gartner has noted that the DataOps / orchestration tool category is accelerating in maturity and adoption, as complexity increases. Without a smart orchestration layer, organizations accumulate “pipeline debt” — fragile scripts, brittle dependencies, undocumented workflows, and limited visibility.
If unaddressed, the consequences are serious:
- Undetected failures corrupt downstream models or dashboards
- Latency spikes undermine real-time decision making
- Maintenance overhead drains engineering bandwidth
- Lack of visibility breeds distrust in data
- Inability to evolve pipelines in response to new use cases
Consider a global fintech firm managing 100+ pipelines across geographies. One small schema change upstream triggers a cascade of failures downstream, taking six hours to diagnose and repair. That delay costs not just data engineers but business revenue — a risk no CTO wants.
The gap between current state and future expectation is widening. As organizations adopt AI, decision systems, and closed-loop feedback, they need pipelines that do more than move data — pipelines that reason, self-heal, and adapt.
The new imperative: Data Orchestration: Making Pipelines Smarter is the foundation for unlocking resilient, scalable data ecosystems.
Explore real-world insights in Why Data Integrity Is Critical Across Industries
Defining Data Orchestration (Conceptual Foundation)
A succinct definition
Data orchestration is the automated coordination of data flows, tasks, dependencies, and logic across systems and pipelines — ensuring data is processed in the right order, under the right conditions, with robust governance and observability.
While “pipeline orchestration” is often used interchangeably, orchestration in the broader sense encompasses not just ETL/ELT tasks but metadata flows, governance, event triggers, quality checks, adaptive scaling, error handling, and feedback loops.
In essence:
Data Orchestration = Workflow + Intelligence + Governance + Observability
Core dimensions
You can think of data orchestration as operating across four interlocking dimensions:
- Workflow logic & dependency management
Control when and how tasks run, with conditionals, loops, branching, retries, and event-based triggers. - Resource & execution orchestration
Allocate compute, memory, parallelism; dynamically scale; schedule within resource constraints. - Data & metadata coordination
Catalog lineage, synchronize schema changes, manage versioning, track data quality, enforce policies. - Observability & feedback loops
Monitor health, detect anomalies, trigger corrective workflows or alerts, and feed metrics back into process tuning.
Why this definition matters
By elevating orchestration from “cron + pipelined tasks” to a cross-cutting system with intelligence and governance, you shift the paradigm:
- Pipelines become systems, not scripts
- Failure becomes a first-class event that can be handled programmatically
- Governance (data access, schema evolution, lineage) becomes baked in
- Teams can iterate, extend, and maintain pipelines with resource asymmetry
This is the mindset shift behind “Data Orchestration: Making Pipelines Smarter.”
Dive deeper into AI-driven data frameworks in Data Quality Framework for AI and Analytics
Key Components of a Robust Data Orchestration Framework
In practical terms, building a smart orchestration system means anchoring four key component domains. Below, each is described with examples, metrics, and automation patterns.
- Governance & Metadata Layer
Purpose: Ensure trust, compliance, auditability, and controlled evolution.
Functions:
- Lineage tracking: Record relationships from source to sink, transformations applied, data versions.
- Schema/version control: Manage schema changes, migrations, and backward compatibility.
- Policy enforcement: Role-based access, masking, anonymization.
- Quality metadata: Maintain data quality metrics, validation rules, thresholds.
Example: When a source column is deprecated, the system warns dependent pipelines, suggests migrations, or auto-blocks incompatible runs. You might also tie in governance checks before data reaches consumption layers (e.g. verify no PII leakage).
Metric examples:
- % of pipelines instrumented with lineage
Time to detect schema drift of blocked runs due to policy violations
Automation patterns: intercept schema drift events, auto-propagate changes, gate pipeline runs until data passes governance checks.
- Workflow Logic & Dependency Layer
Purpose: Define how tasks execute (sequence, conditions, branching, retry, event triggers).
Functions:
- DAG modeling (Directed Acyclic Graphs) or flow graphs
- Conditional execution, loops, branches
- Event-driven triggers (file arrival, API signals)
- Failure, retry, backoff logic, fallback tasks
- Dynamic dependency resolution
Example: A marketing pipeline might branch: if the new leads volume > threshold, run enrichment; else skip enrichment. Or, only run model retraining if significant drift is detected.
Metric examples:
- Task success rate
- Mean time between recovery events
- Number of dynamic branches executed
Automation patterns: templates for common DAG motifs, use of sub-DAGs or task groups, parameterized workflows.
- Execution & Resource Orchestration Layer
Purpose: Efficient execution of tasks across compute resources, elasticity, isolation, workload scheduling.
Functions:
- Task scheduling (batch, streaming, micro-batches)
- Resource allocation & autoscaling
- Containerization/virtualization (e.g. Kubernetes, serverless patterns)
- Prioritization, quotas, resource isolation
- Retry strategies and backoff
Example: A nightly pipeline may spawn Spark clusters on demand; for smaller tasks, execute in lightweight containers; backfill tasks may run on spare capacity.
Metric examples:
- Cost per pipeline run
- Average resource utilization
- Execution latency variance
Automation patterns: dynamic scaling rules, resource-aware scheduling, priority queuing, preemptible compute, hybrid runtime engines.
- Observability, Monitoring & Feedback Layer
Purpose: Detect, alert, and self-heal — turning black-box pipelines into transparent, introspectable systems.
Functions:
- Real-time and historical dashboards (task status, runtime, latency, errors)
- Alerting & incident triggers (thresholds, anomalies)
- Auto-recovery (retry, rerun, skip)
- Drift detection (schema, data distribution)
- Feedback control loops (metrics feed logic)
Example: If a task’s runtime suddenly spikes 3× baseline, trigger a “slow-path” alert, auto spawn extra compute, or re-optimize that step. Or detect that data volume has jumped beyond expected, and throttle downstream consumption.
Metric examples:
- Mean time to detect failure
- Mean time to recover
- Anomaly detection false positive rate
- SLA adherence rate
Automation patterns: integrate with observability stacks, embed anomaly detectors, build auto-healing loops.
Putting It All Together: Orchestration in a Smart Pipeline
Consider a simplified customer-360 pipeline:
- Extraction: pull data from CRM, transactional DB, mobile logs
- Validation: run checks on schemas, volumes, nulls
- Transformation: compute aggregates, enrich with external datasets
- Model scoring / enrichment
- Load & serve
In a smart orchestrated implementation:
- The governance layer verifies schema consistency before extraction; any drift triggers hold.
- The logic layer enforces that validation must pass before transformation; if validation fails, branch to a remediation pipeline.
- The execution layer spins up compute only on needed tasks; for heavy joins, use Spark; for light tasks, serverless or container.
- The observability layer tracks runtime performance, issues alerts on anomalies, and triggers an automated retry or fallback.
This layered approach ensures your data orchestration is resilient, adaptive, governable, and visible.
See how Techment implemented scalable data automation in Unleashing the Power of Data Whitepaper
Best Practices for Reliable, Intelligent Orchestration
Below are 5 strategic best practices to ensure your orchestration system isn’t just functional, but robust and future-ready.
- Start with a pipeline maturity assessment
Before re-architecting, map your existing pipelines: dependencies, failure patterns, maintenance effort, visibility gaps. Use a maturity scorecard (e.g. from 1 = cron jobs to 5 = full auto-healing orchestration). Identify top pain areas to prioritize.
- Adopt modular, reusable task patterns
Abstract common logic (e.g. ingestion, validation, transformation) into reusable building blocks. Encourage a library of “orchestration primitives” so new pipelines glue together known components, reducing error and increasing consistency.
- Use declarative, versioned orchestration definitions
Define pipelines as code (e.g. YAML, Python, DSL) and place orchestration metadata in version control. This allows reproducibility, auditing, rollback, code review, and safer evolution. Avoid hard-coding logic in scripts.
- Embed governance and quality gates
Don’t treat validation or compliance as afterthoughts. Use the orchestration layer to enforce gates: no pipeline run if schema drift, missing lineage, or data quality thresholds are violated.
- Build observability and feedback into the loop
Make monitoring, anomaly detection, and auto-recovery native. Use metrics and signals to influence logic (e.g. dynamic retry or ramp down), not just after-the-fact alerts. Consider integrating data observability tools (Gartner’s Data Observability segment is rising in attention).
- Maintain cross-functional alignment & ownership
Orchestration isn’t purely a data engineering concern. Product, analytics, and operations must align on SLAs, error response, schema changes, and exception handling. Define clear roles (who owns fallback, who resolves data errors, etc.)
Implementation Roadmap: From Concept to Continuous Improvement in Data Orchestration
To help you get started, here’s a structured, pragmatic roadmap (6 phases) you can adopt:
Phase 1: Assessment & Design
- Conduct pipeline maturity audit
- Identify high-value use cases for orchestration
- Map data domains, dependencies, SLAs
- Define target orchestration architecture & operational principles
Pro tip: start with critical pipelines (e.g. revenue, compliance) to prove ROI early.
Phase 2: Prototype & Proof-of-Concept
- Build a minimal orchestration skeleton for one use case
- Implement core components: lineage, retry logic, alerting
- Validate integration with upstream/downstream systems
Pitfall to avoid: Over-engineering the first version — keep the POC focused, minimal, and instrumented.
Phase 3: Incremental Rollout & Parallel Runs
- Gradually onboard additional pipelines
- Run orchestration in “monitor-only” mode for legacy pipelines initially
- Develop task templates and reusable modules
- Collect metrics, iterate
Phase 4: Governance & Policy Roll-in
- Introduce governance gates (schema, quality, lineage)
- Enforce policy checks in orchestration logic
- Build dashboards, define ownership
Phase 5: Observability & Auto-Recovery
- Instrument runtime metrics, anomaly detectors
- Define alerting and automatic fallback paths
- Introduce feedback loops (e.g. rerun, alternate logic)
Phase 6: Optimization & Continuous Evolution
- Analyze usage, bottlenecks, cost patterns
- Expand dynamic branching, parameterization, scalability
- Conduct regular reviews, refine templates, and extend architecture
- Evolve orchestration to support emerging use cases (e.g. ML retraining, streaming)
Each phase should be governed by clear success metrics and checkpoints. Use a “pilot → scale → optimize” mindset.
Read how Techment streamlined governance in Streamlining Operations with Reporting Case Study
Measuring Impact & ROI
To justify orchestration investments, it’s essential to link technical metrics to business outcomes. Below are key metrics and a mini case example.
Key metrics & KPIs

Mini Case Snapshot
At a global e-commerce platform, Techment implemented an orchestration overhaul across 50 pipelines. After six months:
- Task success rate rose from 97% to 99.97%
- Mean time to recover (MTTR) dropped from ~40 minutes to ~4 minutes
- Manual incident time was cut by ~60%
- SLA adherence improved from 93% to 99.8%
- Engineers saved ~25% of weekly capacity (≈ two FTE-equivalents)
- ROI payback in < 12 months, owing to reduced outages and faster product delivery
These numbers reflect the power of turning pipelines from liability into assets — especially when supporting AI, analytics, and real-time use cases.
Discover measurable outcomes in Optimizing Payment Gateway Testing Case Study
Emerging Trends and Future Outlook
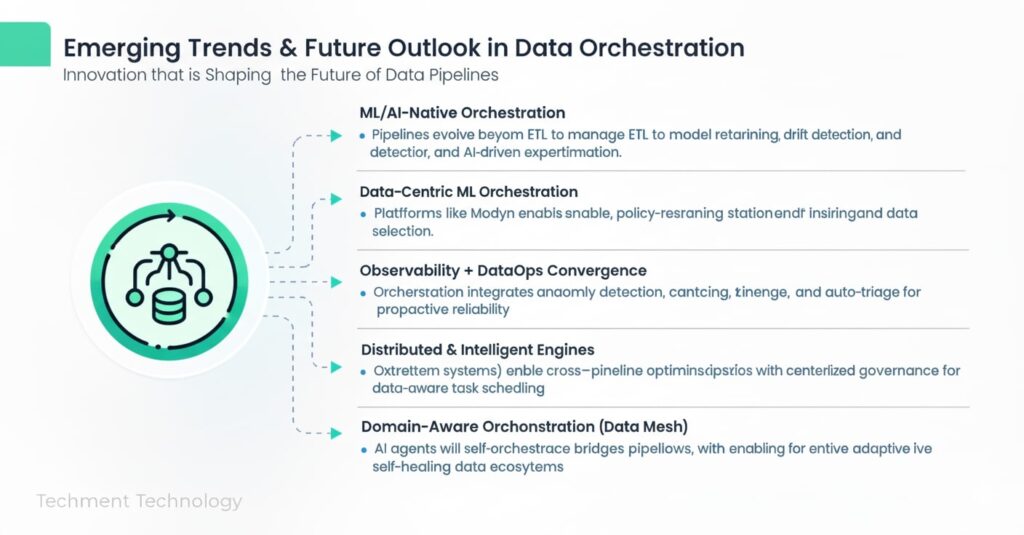
To stay ahead, your orchestration strategy must evolve along with the data landscape. Below are major emerging themes shaping the next decade.
- ML/AI-native orchestration
As organizations embed AI in workflows, pipelines won’t end at ETL. Orchestration will need to natively manage:
- Model retraining cycles
- Experimentation pipelines
- Drift triggers, A/B rollout
- Data selection and sampling strategies
Platforms like Modyn are pushing toward data-centric ML orchestration, where policies govern retraining and data selection. arXiv
- Observability + data ops convergence
Data observability is maturing rapidly (driven by the Gartner Data Observability market) and will be a standard component of orchestration loops. Orchestration systems will increasingly integrate anomaly detection, lineage-based error root cause, and auto-triage.
- Distributed, intelligent orchestration engines
Next-gen systems (e.g. iDDS) are exploring distributed, data-aware scheduling across heterogeneous resources, integrating dispatch and logic within the same system. This allows cross-pipeline optimization, dynamic task placement, and scalable orchestration at scientific scales.
- Interplay with data mesh & domain orchestration
As data mesh adoption grows, orchestration must respect domain boundaries. Rather than a monolithic orchestrator, multi-tenant or federated orchestration patterns will emerge — bridging local domain pipelines with global governance.
- “Agentic” AI and autonomous pipelines
Gartner predicts many enterprise “agentic AI” projects will be scrapped due to complexity — but where they succeed, orchestration will be the nervous system. Pipelines must support autonomous agents that reason about data flows, dependencies, and feedback loops — essentially orchestrating themselves.
Explore next-gen data thinking in Data Cloud Continuum: Value-Based Care Whitepaper
Techment’s Perspective & Approach
At Techment, we view Data Orchestration: Making Pipelines Smarter not as a one-time project, but as a strategic capability. Our proprietary methodology, Orchestra™, blends research, field experience, and tooling to accelerate adoption and scale.
Key pillars in our approach
- Assessment-first: We begin with a detailed orchestration maturity diagnostic, benchmarking against industry norms.
- Modular design: We deliver task libraries, orchestration templates and blueprint patterns that your teams can adopt and extend.
- Governance-first mindset: Policies and metadata guardrails are built into pipelines from day one — not bolted on later.
- Observability-driven: Each pipeline includes instrumentation from the outset; we tie orchestration logic to feedback signals.
- Cross-team enablement: We train Product, Analytics, and Engineering stakeholders on governance, SLA design, and orchestration best practices.
We at Techment don’t view pipelines as mere plumbing — they’re active systems that must adapt, self-heal, and scale. Our goal is to make orchestration a core capability, not an afterthought.
By partnering with clients across fintech, health tech, retail, and manufacturing, we’ve helped deliver orchestration systems that reduced downtime, improved model accuracy, and scaled with usage. Whether you are in the early stages or looking to evolve monolithic orchestration layers, we can help you calibrate, roadmap, and execute.
Get started with a free consultation in Unleashing the Power of Data Whitepaper
Conclusion
Data Orchestration: Making Pipelines Smarter is more than a technical pattern — it’s a strategic shift in how data-driven organizations operate. By elevating pipelines into intelligent, observable, and governed systems, you unlock scale, resilience, and agility for AI, analytics, and mission-critical applications.
For CTOs, Data Engineering Leaders, and Product Heads, the time to act is now. Begin by assessing your pipeline maturity. Pilot orchestration on mission-critical workflows. Embed governance and observability from the ground up. Monitor impact and refine iteratively.
Techment stands ready to partner with you—bringing proven frameworks, domain expertise, and hands-on execution to accelerate your journey.
Schedule a free Data Discovery Assessment with Techment at Techment.com/Contact
Let’s make pipelines smarter — together.
FAQs
Q: What is the ROI of implementing data orchestration?
A: The ROI comes from reduced downtime, lower manual overhead, increased SLA adherence, and faster time-to-value for data products. In many engagements, payback occurs in under 12 months as incident resolution time falls and engineering capacity is freed.
Q: How can enterprises measure success of orchestration?
A: Track metrics like task success rate, MTTR, SLA adherence, operational overhead, and pipeline run cost. Tie these to business metrics — e.g. model performance, fraud detection rates, revenue impact.
Q: What orchestration tools enable scalability?
A: Common options include Apache Airflow , Apache NiFi, Prefect, Dagster, AWS Step Functions, and proprietary orchestration platforms. The best tool depends on your cloud ecosystem, scale, and use cases.
Q: How to integrate orchestration with existing data ecosystems?
A: Adopt a phased integration: run in monitoring-only mode first, build connectors to existing ETL/ELT jobs, wrap legacy scripts in orchestration tasks, gradually migrate pipelines. Use adapter layers to abstract legacy systems.
Q: What governance challenges arise in orchestration?
A: Common issues include schema drift, lineage gaps, policy enforcement, versioning, and cross-domain ownership. You must define clear ownership, automate schema gate checks, maintain cataloging, and ensure that orchestration metadata is auditable.
Related Reads from Techment
