
In the age of continuous delivery and DevOps, software quality cannot stop at the moment of release. Traditional testing methods, focused on pre-release validation, often miss issues that only surface under real-world conditions—such as unexpected user behavior, unpredictable traffic surges, or complex integrations across distributed systems.
This is where shift-right testing practices come into play. By extending testing into production environments, organizations can embed quality post-release, monitor user experience in real-time, and respond quickly to issues before they impact business outcomes. For QA leaders, CTOs, and product owners, this approach represents not just a testing methodology, but a cultural shift toward continuous quality assurance.
TL;DR (Key Takeaways)
- Shift-right testing extends quality checks beyond release into production.
- Real-time monitoring and observability ensure faster issue detection and resolution.
- Techniques like canary releases, feature toggles, and chaos engineering reduce risk.
- Embedding quality in production builds resilient, customer-trusted systems.
- Shift-right requires cultural alignment, strong tooling, and strategic execution.
1. What Are Shift-Right Testing Practices?
Shift-right testing refers to extending testing and validation into production environments. Unlike shift-left testing, which focuses on defect prevention early in development, shift-right ensures that quality continues to be validated under real-world conditions.
Core Components of Shift-Right Testing
Real-time Monitoring of System Performance and User Experience
- Shift-right testing relies heavily on continuous, real-time monitoring to detect issues that traditional pre-release testing might miss.
- This involves tracking application response times, error rates, throughput, and user interaction patterns to identify anomalies as they occur.
- By capturing both technical performance metrics (e.g., latency, CPU utilization) and user-centric KPIs (e.g., session duration, click paths), teams gain a holistic view of how software performs in real-world conditions.
- Advanced observability tools with dashboards and alerting systems empower teams to proactively address problems before they escalate into outages.
Progressive Delivery Techniques such as A/B Testing and Canary Releases
- Progressive delivery enables organizations to validate features in production while minimizing risk.
- A/B testing allows comparison of different feature variants with actual user groups to measure impact on engagement, usability, or conversions.
- Canary releases gradually roll out new features to a subset of users, ensuring stability before full-scale deployment.
- These approaches reduce the blast radius of potential defects while enabling data-driven decisions about whether to proceed, roll back, or iterate on changes.
Chaos Engineering to Validate System Resilience under Failure Conditions
- Chaos engineering simulates unexpected disruptions—such as server crashes, network latency, or service unavailability—to test how systems behave under stress.
- This controlled experimentation validates whether failover mechanisms, redundancies, and recovery strategies are working as intended.
- By “breaking things on purpose” in production-like environments, teams uncover hidden weaknesses that traditional tests often overlook.
- As resilience becomes a competitive advantage, chaos engineering ensures applications can withstand failures without degrading customer experience.
Continuous Feedback Loops Between Production and Development Teams
- Shift-right testing thrives on continuous feedback that flows seamlessly from operations back to development.
- Real-world insights—such as usage analytics, performance anomalies, and incident reports—inform future design and coding practices.
- Automated pipelines that integrate monitoring data into development workflows accelerate the feedback cycle, enabling rapid fixes and enhancements.
- This cultural shift transforms testing from a one-time activity into an ongoing process of quality validation, fostering collaboration between DevOps, QA, and product teams.
Learn how Techment helps enterprises implement test automation successfully.
2. Why Traditional Testing Alone Is No Longer Enough
Even the most rigorous pre-release testing cannot fully replicate the complexity and unpredictability of real-world environments. As applications scale, several challenges make it clear that traditional approaches are insufficient:
- Complex Integrations
Modern applications rarely exist in isolation. They depend heavily on APIs, third-party services, and distributed microservices. While these integrations may function smoothly in controlled test environments, behavior often changes at production scale. Latency spikes, inconsistent response times, or unexpected dependency failures can occur only under real user load. Traditional testing environments cannot fully simulate this dynamic ecosystem, making continuous, real-world validation critical. - User Unpredictability
No matter how comprehensive test cases are, they cannot capture the full range of user behavior. Real users interact with applications in ways developers and testers never anticipated—skipping flows, rapidly switching contexts, or chaining actions in unexpected sequences. This unpredictability often exposes edge cases, performance bottlenecks, and usability issues that go undetected pre-release. Without observing real user interactions, organizations risk delivering an experience that looks perfect in QA but breaks down in production. - Environmental Differences
Pre-release environments are designed for controlled testing, not for mirroring production at scale. In reality, production involves far higher concurrency levels, diverse global traffic patterns, and significantly larger datasets. These differences can expose issues like race conditions, database deadlocks, or infrastructure bottlenecks that traditional testing simply misses. Simulated environments, no matter how advanced, cannot fully replicate the scale, diversity, and complexity of real-world conditions. - Security Threats
Cybersecurity adds another layer of unpredictability. Threat actors constantly evolve their tactics, exploiting vulnerabilities that may not even exist at the time of pre-release testing. Traditional security testing—while essential—cannot anticipate zero-day exploits, real-time phishing attempts, or novel attack vectors. To ensure resilience, applications must be continuously monitored in production, where security threats are active and evolving.
These challenges highlight why shift-right testing practices—such as real-time monitoring, chaos testing, and user behavior analytics—are becoming essential. Traditional testing lays the foundation, but only production-aware strategies can guarantee ongoing quality, resilience, and user trust.
According to Capgemini’s World Quality Report, over 50% of QA leaders state that traditional testing misses key production-related risks, highlighting the urgent need for shift-right practices.
3. Key Benefits of Shift-Right Testing
3.1 Enhanced User Experience
- Real-time monitoring tools enable teams to continuously track application performance under real-world conditions.
- Early detection of latency issues, performance bottlenecks, or API failures ensures that end-users face minimal disruptions.
- By simulating actual user journeys in production, organizations can fine-tune experiences, leading to higher customer satisfaction and retention.
- A proactive approach to quality directly translates into smoother digital interactions, which is vital for brand loyalty in competitive markets.
3.2 Faster Incident Response
- Shift-right testing focuses on reducing Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR) through automation and intelligent alerts.
- Instead of waiting for customer complaints, monitoring and observability systems immediately flag anomalies.
- Quick resolution minimizes downtime, preserves revenue, and strengthens customer trust in digital platforms.
- The ability to act in near real-time helps businesses maintain service-level agreements (SLAs) and avoid reputational damage.
3.3 Continuous Feedback Loop
- Data captured from production—such as error logs, user behavior analytics, and performance metrics—feeds directly into the development cycle.
- This constant feedback enables teams to prioritize fixes based on real impact, rather than assumptions.
- Continuous learning ensures that new releases are not only bug-free but also aligned with user expectations and business goals.
- Ultimately, this creates a closed-loop system where production insights fuel product innovation and faster value delivery.
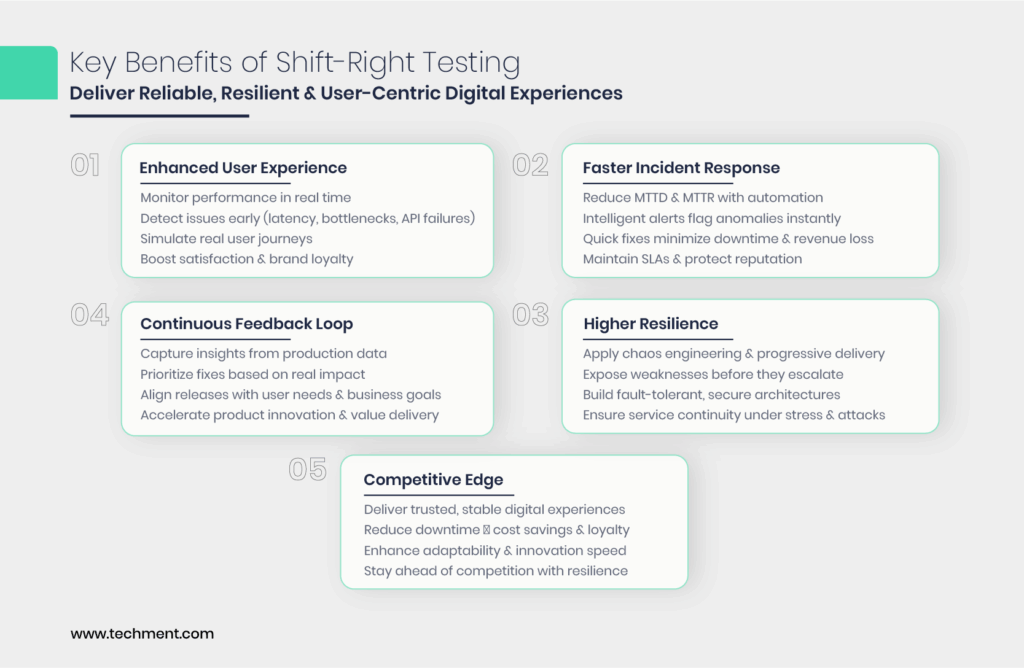
3.4 Higher Resilience
- Practices like chaos engineering and progressive delivery validate system stability under unpredictable real-world scenarios.
- By intentionally introducing failures, teams identify weaknesses before they escalate into widespread outages.
- Resilience testing helps build fault-tolerant architectures, ensuring services remain available despite traffic spikes, hardware issues, or cyberattacks.
- This proactive resilience strengthens operational continuity, making digital ecosystems more reliable.
3.5 Competitive Edge
- Businesses adopting shift-right practices deliver more stable and trusted digital experiences, which customers increasingly demand.
- Reduced downtime translates into cost savings, improved productivity, and stronger customer loyalty.
- A resilient, high-performing system becomes a strategic differentiator in industries where user experience defines market leaders.
- Companies that embrace shift-right testing gain faster adaptability, positioning themselves ahead of slower-moving competitors.
Learn how Techment drives better business outcomes through quality engineering.
4. Embedding Quality in Production: Strategies That Work
Practical approaches to embedding quality post-release:
- Canary Deployments: Release to a small group before global rollout.
- Feature Toggles: Switch features on/off dynamically without redeployments.
- Service Monitoring: Tools like Dynatrace, New Relic, and Datadog enable real-time system monitoring.
- Chaos Engineering: Inject controlled failures to test system resilience (e.g., Netflix’s Chaos Monkey).
- Synthetic Monitoring: Simulate real-user interactions to validate end-to-end functionality.
5. Real-World Testing After Release: Approaches and Tools
5.1 Observability and Monitoring
- Observability-first approach: Post-release quality relies on continuous observability, where metrics, logs, and traces reveal hidden issues in real-world usage.
- Prometheus & Grafana: Widely adopted for time-series monitoring and visualization, helping teams identify performance bottlenecks and system anomalies quickly.
- Splunk: Provides advanced log aggregation, search, and analysis, offering enterprise-grade insights into user behavior, error frequency, and security anomalies.
- Value: Together, these tools enable proactive detection, reducing mean time to detect (MTTD) and mean time to resolve (MTTR), ensuring smoother user experiences.
5.2 A/B and Multivariate Testing
- Controlled experimentation: Allows product teams to validate different UI/UX designs, workflows, or feature toggles directly in production.
- A/B testing: Splits traffic between two variants to measure impact on KPIs such as conversion rate, retention, or engagement.
- Multivariate testing (MVT): Goes beyond A/B by testing multiple combinations of elements (e.g., button color, layout, copy) simultaneously.
- Value: Ensures that real user feedback drives product evolution, while minimizing risks associated with feature rollouts.
5.3 Fault Injection and Resilience Testing
- Chaos engineering mindset: Intentionally introduces failures in live systems to validate resilience and recovery strategies.
- Gremlin: Industry-leading platform for simulating CPU spikes, network latency, or infrastructure outages.
- Chaos Mesh: Kubernetes-native tool enabling pod failures, network delays, and resource exhaustion tests.
- AWS Fault Injection Simulator: Cloud-native service for simulating real-world failures at scale within AWS environments.
- Value: Strengthens system reliability and fault tolerance, ensuring that services remain available even under unpredictable conditions.
5.4 Continuous Performance Testing
- Beyond pre-release load testing: Extends performance validation into production, monitoring response times, throughput, and scalability continuously.
- JMeter: An open-source tool capable of executing complex load, stress, and endurance tests directly against live environments.
- k6: Developer-friendly, scriptable performance tool with CI/CD integration, enabling ongoing validation of APIs and microservices in production.
- Value: Provides continuous performance baselines, ensuring applications scale seamlessly as user traffic and workloads evolve.
Related Read: Enterprise Test Automation ROI: Measuring Value Beyond Cost Savings
6. Challenges and How to Overcome Them

According to Gartner, organizations with strong DevOps cultures achieve 60% faster recovery times from failures, validating the importance of cultural change.
7. How Techment Implements Shift-Right for Enterprise Clients
At Techment, we help organizations embed quality in production by combining:
- Intelligent monitoring integrated with CI/CD pipelines.
- Progressive delivery models like canary deployments and feature toggles.
- Chaos engineering for resilience validation.
- Automated feedback loops to inform future sprints with real-world data.
Example: For a retail client managing high-volume e-commerce traffic, Techment implemented real-time monitoring with synthetic tests and canary releases. This reduced post-release defects by 35% and ensured peak-season stability.
Explore our QA Testing Solutions.
- Conclusion + Actionable Takeaways
In an era of continuous delivery, shift-right testing bridges the gap between release and real-world reliability. By embedding quality post-release, organizations achieve faster recovery, higher resilience, and improved customer trust.
Actionable Takeaways:
- Use canary deployments and feature toggles to minimize risks.
- Implement observability platforms for real-time insights.
- Conduct chaos engineering to validate resilience.
- Establish continuous feedback loops for sustained improvement.
- Partner with experienced providers for seamless adoption.
Contact us to implement test automation at scale.
Data & Stats Snapshot
- 50%+ of QA leaders report traditional testing misses key risks (Capgemini WQR).
- Companies with DevOps cultures recover 60% faster from failures (Gartner).
- Shift-right adopters see 30–40% fewer production incidents (Forrester).
FAQ Section
- What is shift-right testing in DevOps?
Shift-right testing extends testing into production environments, ensuring quality validation under real-world conditions.
- How does shift-right differ from shift-left testing?
- Shift-left: Detects defects early in development.
- Shift-right: Ensures quality continues to be monitored post-release.
- What are the risks of testing in production?
Risks include user impact and data privacy challenges. These are mitigated with canary deployments, feature flags, and data masking.
- What industries benefit most from shift-right?
Industries with high availability demands—such as finance, retail, and healthcare—benefit greatly.
- What tools are used for shift-right testing?
Common tools include Dynatrace, Gremlin, Prometheus, Splunk, and AWS Fault Injection Simulator.
- Does shift-right mean testing replaces monitoring?
No. Monitoring is part of shift-right, but shift-right also involves progressive delivery, chaos engineering, and real-time validation.
- How does Techment support shift-right adoption?
By integrating observability, chaos testing, and automation within enterprise CI/CD pipelines.




